1. 使用Anaconda
Anaconda,中文大蟒蛇,是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖.可通过Anaconda下载。选择合适版本。
注意:一个python环境应当只安装一个版本的tensorflow,如果还需要安装其他版本的tensorflow,应该再创建一个python环境
Anaconda,中文大蟒蛇,是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖.可通过Anaconda下载。选择合适版本。
注意:一个python环境应当只安装一个版本的tensorflow,如果还需要安装其他版本的tensorflow,应该再创建一个python环境
两个可供突破的大方向:
资源:
正如前面所说的,阅读文献的选择应该是在你确定了一个大的研究方向之后,选择经典和最新的文献进行阅读其摘要是否与自己领域相关,相关都建议下载阅读,所谓经典和最新是指:
Git 是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。Git原来是 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。
VScode是微软推出一个轻量化编辑器,只需要下载相应的编译器和包即可支持C/C++、java、python的编写。相对于VS来说,VScode更加的轻便、体积小,支持许多插件。

?key1=value1&key2=value2。MySQL最重要最与众不同的就是它的存储引擎架构,这种架构设计将查询处理(QUERY PROCESSING)及其他系统任务和数据存储/提取相分离。在这里主要介绍MySQL的服务器架构、各种存储引擎之间的区别。
MySQL各组件协同工作的示意图如下:
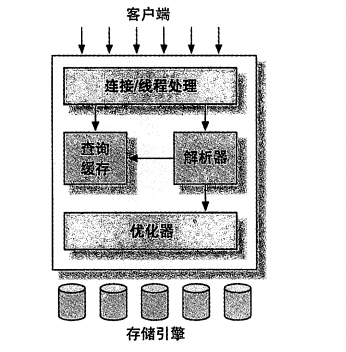
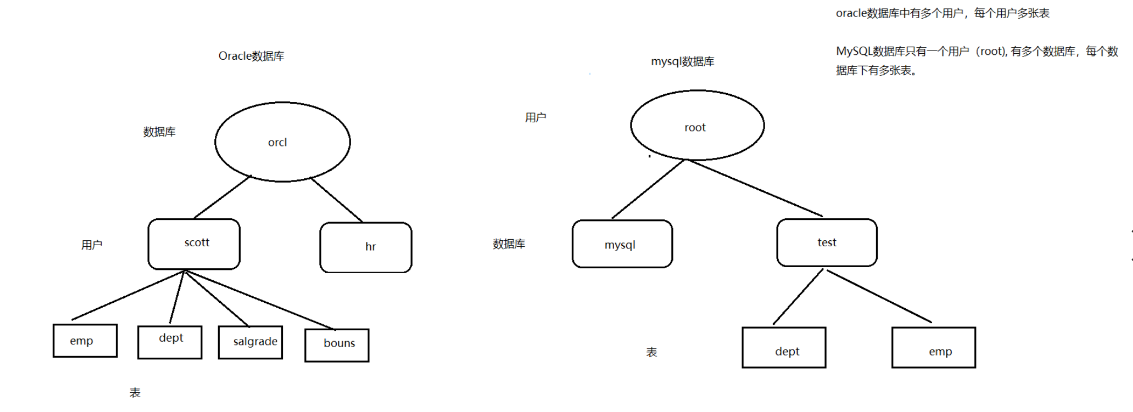
数据库是一个以某种有组织的方式存储的数据集合。MySQL数据库中只有一个用户,名为root,但是它可以有多个数据库,如下是与Oracle数据库的不同之处:
读者在看到这篇文章的时候不应该以本文的讲解顺序进行刷题。正常来说,按模块刷题是最好的,我的刷题是按照数组->链表->树->dp的循环进行,然后对各模块的方法进行总结,比如遇到 - 数组一类的,其可使用的方法最多:二分查找、快慢指针、双指针、滑动窗口、前缀和数组、差分数组等。 - 遇到链表,那么快慢指针是最多的。 - 遇到树,那么递归(广度or深度)是最常用的形式、非递归遍历也要顺序,记住对称性解题方式。 - 遇到动态规划,先分类其是属于哪种形式的dp(线性dp、区间dp、背包dp和状压dp),然后确定dp含义,分析状态转移方程。 - 其他方法,比如**单调栈、单调队列的实现、拓扑排序、归并排序、KMP算法、分治、广度*等算法就就需要在刷题中不断掌握
注意:在解题中一定不要忽略暴力解,许多奇妙的解法就是从暴力解的思路上想出来的,一旦遇到一道不会优解的题,可以先想一想暴力解的思路,有什么地方可以优化暴力解,来达到降低时间复杂度的效果
动态规划的思想就是:如果一个问题能够由子问题一步步递推得来,即当前子问题的解将由上一次子问题的解推出,利用这种特性,使用一个数据结构dp来存储上一次子问题的结果,避免重复计算。
所以动态规划最重要的有三点:
知道上述三点,问题也就迎刃而解。在算法当中,常见的dp类型有线性dp、区间dp、背包dp和状压dp。下面将对这几个进行讲解。
总结:对于是否使用DP,那么就得看你能不能确定dp数组的含义,以及能够确定状态转移方程。
tips:做了比较多的题,通常许多的字符串dp类型的题目是区间dp,像回文串、编辑距离等待,二数组类型的dp,较多的是线性dp、多状态dp(状压dp)和背包dp类型
问题:你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
DP的由来是因为可以将一个问题由子问题得出:完整的问题可以由正方向得出(符合人的逻辑,自底向上),也可以由反方向得出(回溯,自顶向下),一般来说推荐正难则反,即推荐反向思考。
所以dp问题最经典的解题思路四个步骤就是:问题能否从结果往前递归回溯(即由上一个问题得到当前问题解)?-->回溯+记忆化搜索(优化时间)-->1:1翻译成递推,即dp形式-->优化空间
回溯的方式更加容易且贴合dp的子问题递归,因此这里讲的是以反向方式来解决。(不去关心到达怎么解决,只关心当前状态是按什么方程由上一个状态得来的)
记忆化搜索:通过dfs的参数来决定创建的是几维数组,它也决定可了递推式中dp的维度
线性DP,一般从前缀/后缀上进行转移。 ### 1.1 背包问题 本质还是选与不选
#### 0-1背包
0-1背包:有n个物品,第i个物品的体积为w[i],价值为v[i],每个物品至多选一个,求体积和不超过capacity时的最大价值和。
思路:
背包问题是dp的一个经典题型,涉及到一个当前元素选与不选:
- 选:在剩余容量为c-w[i]时,从前i-1个物品得到的最大价值和 -
不选:在剩余容量c时,从前i-1个物品得到的最大价值和
- 取两者较大值。
边界问题: -
i<0或者c<0时,需要返回0,次数代表没有其他商品可选,或者没有容量可以装了
记忆化搜索:通过dfs的参数来决定创建的是几维数组,它也决定可了递推式中dp的维度
1 | int maxValue(vector<int>&w,vector<int>&v,int capacity){ |
讲上述的“回溯+记忆化搜索”进行1:1翻译可以得到递推,注意翻译过程中的边界条件如何实现(一般通过增加1个开额外的dp数组即可)
上述中,用dp数组得到的递推式如下:
dp[i][c] = max(dp[i-1][c],dp[i-1][c-w[i]]+v[i])
1 | int maxValue(vector<int>&w,vector<int>&v,int capacity){ |
变体题目:
完全背包与01背包的不同点,只在于可以重复选择:
只需要更改res = dfs(i-1,c-w[i])+v[i];为res = dfs(i,c-w[i])+v[i];即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16int maxValue(vector<int>&w,vector<int>&v,int capacity){
int n = w.size();
//数组存储已经得到过的dfs{i,c)
vector<vector<int>> cache(n,vector<int>(capacity+1,-1));
function<int(int,int)> dfs = [&](int i,int c){
if(i < 0||c < 0) return 0;
int& res = cache[i][c];
if(res!=-1) return res;
if(c>=w[i]){
res = dfs(i,c-w[i])+v[i];
}
res = max(res,dfs(i-1,c));
return res;
};
return dfs(n-1,capacity);
}
变体题目: 332.零钱兑换
leetcode内由许多股票问题,这类成为状态机DP 121.买卖股票的最佳时机 122.买卖股票的最佳时机Ⅱ 123.买卖股票的最佳时机Ⅲ 188.买卖股票的最佳时机Ⅳ 714.买卖股票的最佳时机含手续费 309.买卖股票的最佳时机含冷冻期
上面的题目均可由回溯+记忆化搜索的一个模板解决。
其题意就是就是至少交易0次,即可以交易无穷次。
1 | int maxProfit(vector<int>& prices) { |
将回溯+记忆化搜索进行1:1翻译成递推(自底向上),则递推式:dp(i,0)表示前i个股票中当前未持有股票时的最大利润,dp(i,1)`表示前i个股票中当前持有股票时的最大利润,有:
dp(i,0) = max(dp(i-1,0),dp(i-1,1)+prices[i])dp(i,1) = max(dp(i-1,1),dp(i-1,0)-prices[i])边界条件-->即递推的初始状态:
只需要将if(i<0) return hold?INT_MIN/2:0;这句话转换,因此我们为dp多开辟一个空间作为出发临界状态,即dp大小为dp[n+1][2]
dp[0][0] = 0dp[0][1] = INT_MIN/21 | int maxProfit(vector<int>& prices) { |
最多可以完成 k 笔交易。也就是说,你最多可以买 k 次,卖 k
次。只需要将上面的代码dfs添加一个参数j即可 ##### 回溯+记忆化搜索
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15int maxProfit(int k, vector<int>& prices) {
int n = prices.size();
int cache[n][k+1][2];
memset(cache,-1,sizeof(cache));
function<int(int,int,bool)> dfs = [&](int i,int j,bool hold){
if(j<0) return INT_MIN/2;
if(i<0) return hold?INT_MIN/2:0;
int& res = cache[i][j][hold];
if(res!=-1) return res;
if(hold) res = max(dfs(i-1,j,true),dfs(i-1,j,false)-prices[i]);
else res = max(dfs(i-1,j,false),dfs(i-1,j-1,true)+prices[i]);
return res;
};
return dfs(n-1,k,false);
}
1 | int maxProfit(int k, vector<int>& prices) { |
思考:恰好k次交易如何做,那就需要保证初始状态正好是从恰好0次交易出发,而不会由其他状态,因此只有dp[0][1][0]=0
,其他均为INT_MIN+100000
直接秒 1
2
3
4
5
6
7
8
9
10
11
12
13
14int maxProfit(vector<int>& prices) {
int n =prices.size();
vector<vector<int>> cache(n,vector<int>(2,-1));
function<int(int,bool)> dfs = [&](int i,bool hold){
if(i<0) return hold?INT_MIN/2:0;
int& res = cache[i][hold];
if(res!=-1) return res;
//买入的前一天不能卖出,卖出的前一天没有限制
if(hold) res = max(dfs(i-1,true),dfs(i-2,false)-prices[i]);
else res = max(dfs(i-1,false),dfs(i-1,true)+prices[i]);
return res;
};
return dfs(n-1,false);
}
从后缀转移进行转移,即:
1 | class Solution { |
将上面的回溯+记忆搜索进行1:1翻译, 1
2
3
4
5
6
7
8
9
10
11
12int longestCommonSubsequence(string text1, string text2) {
int m = text1.size(),n=text2.size();
vector<vector<int>> dp(m+1,vector<int>(n+1,0));
for(int i=0;i<m;++i){
for(int j=0;j<n;++j){
if(text1[i]==text2[j]) dp[i+1][j+1] = dp[i][j]+1;
else dp[i+1][j+1]=max(dp[i][j+1],dp[i+1][j]);
}
}
return dp[m][n];
}
我们遇到的问题中,有很大一部分可以用动态规划Dynamic Programming来解。
解决这类问题可以很大地提升你的能力与技巧,我会试着帮助你理解如何使用DP来解题