深入理解计算机系统_信息表示和处理
1 信息的存储
大多数的计算机使用8位的块,或者说是字节(byte),作为最小的可寻址内存单位,而不是访问内存中单独的位。机器级程序将内存视为一个非常大的字节数组,我们称为虚拟内存,内存的每个字节都由一个唯一的数字来标识,即称为地址;所有可能的地址空间的集合就是虚拟地址空间。
顾名思义,虚拟地址空间只是一个展现给机器级程序的概念性映像。实际的实现(第九章:虚拟内存)是将DRAM、闪存、磁盘存储器、特殊硬件和操作系统软件结合起来,位程序提供一个看上去统一的字节数组。
深入理解计算机系统_导论
1 学习本书的目的
计算机系统由硬件和系统软件组成。本书是推荐给哪些希望深入了解这些组件如何工作,以及这些组件是如何影响程序正确性和性能,以此来提高自身技能的读者。学完本书,你将知道:
- 如何避免由计算机表示数字的方式引起的奇怪的数字错误(第二章:信息的表示和处理)
- 学会一些小窍门来优化自己的C代码,以充分利用现代处理器和存储器系统的设计
- 你将了解编译器是如何实现过程调用的
- 如何利用这些知识来避免缓冲区溢出错误带来的安全漏洞
- 将学会如何识别和避免链接时那些令人讨厌的错误(第七章:链接)
- 学会如何编写自己的Unix shell、自己的动态存储分配包、自己的web服务器
- 并发带来的希望和陷阱
c++的ref作用
C++11 中引入 std::ref
用于取某个变量的引用,这个引入是为了解决一些传参问题。
我们知道 C++ 中本来就有引用的存在,为何 C++11 中还要引入一个
std::ref 了?主要是考虑函数式编程(如
std::bind)在使用时,是对参数直接拷贝,而不是引用。下面通过例子说明
GOF23
1 概览
23种设计模式主要可以分为三种类型:
创建型模式:用来创建对象
- 单例模式、工厂模式、抽象工厂模式、建造者模式、原型模式。
结构型模式:是从程序的结构上实现松耦合,从而可以扩大整体的类结构,用来解决更大的问题。(关注对象和类的组成关系)
- 适配器模式、桥接模式、装饰模式、组合模式、外观模式、享元模式、代理模式。
行为型模式:关注系统中对象之间的相互交互,研究系统在运行时对象之间的相互通信和协作,进一步明确对象的职责
- 模版方法模式、命令模式、迭代器模式、观察者模式、中介者模式、备忘录模式、解释器模式、状态模式、策略模式、职责链模式、访问者模式。

- 模版方法模式、命令模式、迭代器模式、观察者模式、中介者模式、备忘录模式、解释器模式、状态模式、策略模式、职责链模式、访问者模式。
场景题
1.秒杀系统的设计
秒杀一般出现在商城的促销活动中,指定了一定数量(比如:10个)的商品(比如:手机),以极低的价格(比如:0.1元),让大量用户参与活动,但只有极少数用户能够购买成功。这类活动商家绝大部分是不赚钱的,说白了是找个噱头宣传自己。
像这种瞬时高并发的场景,传统的系统很难应对,我们需要设计一套全新的系统。可以从以下几个方面入手:
- 页面静态化
- CDN(content delivery Network)加速
- 缓存
- mq异步处理
- 限流
- 分布式锁
思路:
首先,对于秒杀系统中的活动页面一般是固定的,比如:商品名称、商品描述、图片等。为了减少不必要的服务端请求,因此要对活动页面做静态化处理。用户浏览商品等常规操作,并不会请求到服务端。只有到了秒杀时间点,并且用户主动点了秒杀按钮才允许访问服务端。
但只做页面静态化还不够,因为用户分布在全国各地,有些人在北京,有些人在成都,有些人在深圳,地域相差很远,网速各不相同。为了让用户最快访问到活动页面,这就需要使用CDN,它的全称是Content Delivery Network,即内容分发网络。使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。
秒杀是一个读多写少的场景(因为在秒杀过程中,每一个请求一般都会检查库存是否充足,足够了才允许修改库存下单,由于大量用户抢少量商品,只有极少部分用户能够抢成功,所以绝大部分用户在秒杀时,库存其实是不足的,系统会直接返回该商品已经抢完。这是非常典型的:读多写少 的场景)。
如果直接使用MYSQL,这么高的并发数据库极有可能挂点,因此应该对库存信息使用redis缓存,,在秒杀活动开始前,将库存信息预缓存倒redis中,同时采用分布式锁防止缓存击穿,并且为了提高系统可用性可以使用集群的方式部署多个节点。
为防止超买超卖(query查询操作非原子操作),扣减库存操作中,使用redis扣减库存。redis的
incr方法是原子性的,可以用该方法扣减库存,:- 1)先判断该用户有没有秒杀过该商品,如果已经秒杀过,则直接返回-1。2)扣减库存,判断返回值是否小于0,如果小于0,则直接返回0,表示库存不足。3)如果扣减库存后,返回值大于或等于0,则将本次秒杀记录保存起来。然后返回1,表示成功。(下述代码不足点:由于预先执行incrby,导致库存变负数,后面有回退库存时,会导致库存不准)
1
2
3
4
5
6
7
8
9bool exist = redisClient.query(productId,userId);
if(exist) {
return -1;
}
if(redisClient.incrby(productId, -1)<0) {
return 0;
}
redisClient.add(productId,userId);
return 1; - 因此,最好的策略:我们都知道lua脚本,是能够保证原子性的,而redis支持lua脚本,它跟redis一起配合使用,能够完美解决上面的问题
1
2
3
4
5
6
7
8
9
10
11
12
13StringBuilder lua = new StringBuilder();
lua.append("if (redis.call('exists', KEYS[1]) == 1) then");
lua.append(" local stock = tonumber(redis.call('get', KEYS[1]));");
lua.append(" if (stock == -1) then");
lua.append(" return 1;");
lua.append(" end;");
lua.append(" if (stock > 0) then");
lua.append(" redis.call('incrby', KEYS[1], -1);");
lua.append(" return stock;");
lua.append(" end;");
lua.append(" return 0;");
lua.append("end;");
lua.append("return -1;");
- 1)先判断该用户有没有秒杀过该商品,如果已经秒杀过,则直接返回-1。2)扣减库存,判断返回值是否小于0,如果小于0,则直接返回0,表示库存不足。3)如果扣减库存后,返回值大于或等于0,则将本次秒杀记录保存起来。然后返回1,表示成功。(下述代码不足点:由于预先执行incrby,导致库存变负数,后面有回退库存时,会导致库存不准)
同时,为了防止redis因为宕机导致的最后数据的不一致性,需要开启redis的持久化机制。
真实的秒杀场景中,有三个核心流程:
秒杀-->生成订单-->支付。真正并发量大的是秒杀功能,下单和支付功能实际并发量很小。所以,我们在设计秒杀系统时,有必要把下单和支付功能从秒杀的主流程中拆分出来,特别是下单功能要做成mq异步处理的。而支付功能,比如支付宝支付,是业务场景本身保证的异步。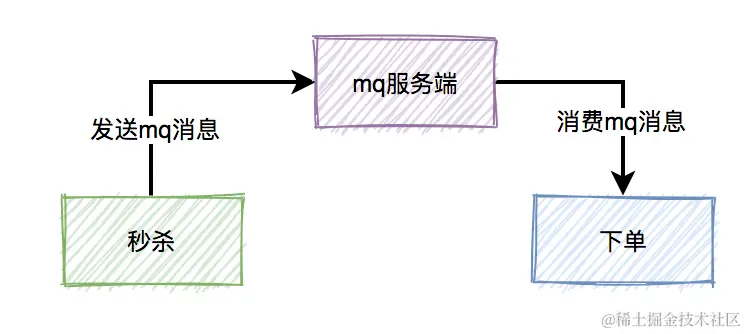
- 往mq发送下单消息的时候,有可能会失败。原因有很多,比如:网络问题、broker挂了、mq服务端磁盘问题等。这些情况,都可能会造成消息丢失。那么,如何防止消息丢失呢?
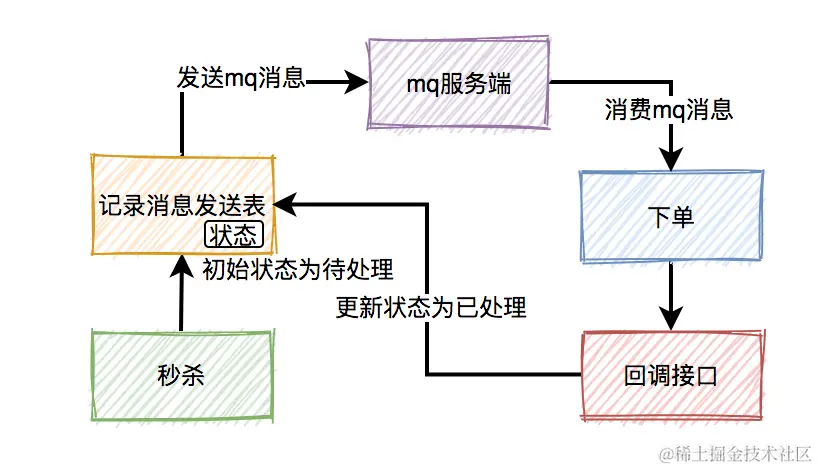
- 方法1:在生产者发送mq消息之前,先把该条消息写入消息发送表,初始状态是待处理,然后再发送mq消息。消费者消费消息时,处理完业务逻辑之后,再回调生产者的一个接口,修改消息状态为已处理。
- 防范2:借助mq的消息的持久化
- 往mq发送下单消息的时候,有可能会失败。原因有很多,比如:网络问题、broker挂了、mq服务端磁盘问题等。这些情况,都可能会造成消息丢失。那么,如何防止消息丢失呢?
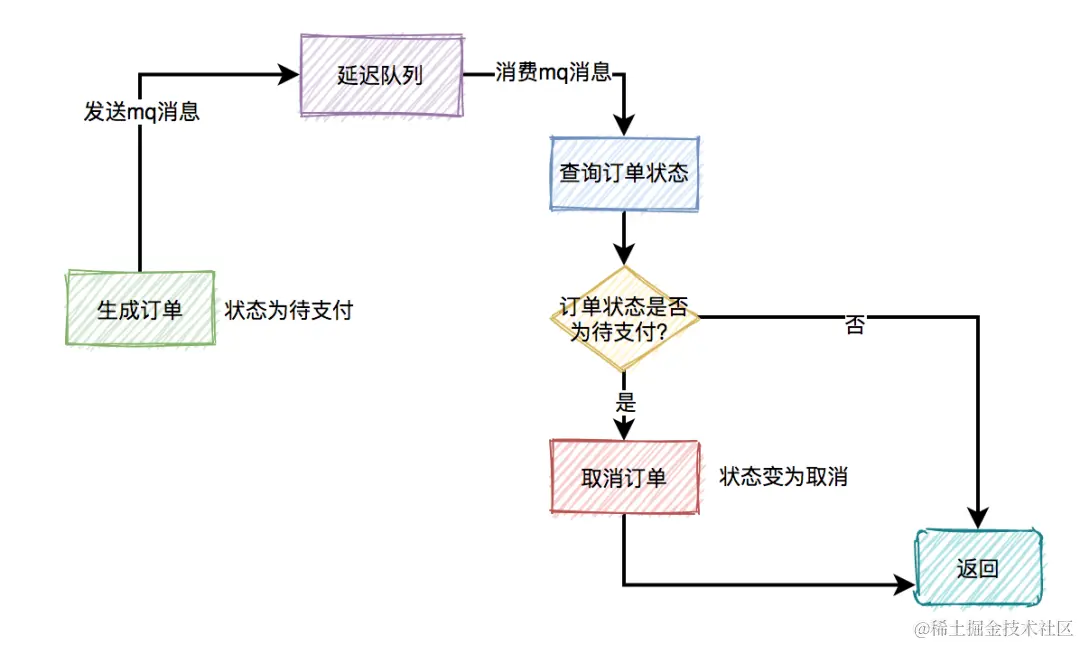
回退库存: 如果用户秒杀成功了,下单之后,在15分钟之内还未完成支付的话,该订单会该被自动取消,库存+1,这种场景可以使用延时队列,下单时消息生产者会先生成订单,此时状态为待支付,然后会向延迟队列中发一条消息。达到了延迟时间,消息消费者读取消息之后,会查询该订单的状态是否为待支付。如果是待支付状态,则会更新订单状态为取消状态。如果不是待支付状态,说明该订单已经支付过了,则直接返回。
- 限流:
- 基于nginx的限流:针对整体而言
- 基于请求速率的限流:通过
ngx_http_limit_req_module模块来实现,该模块支持基于固定窗口算法和令牌桶算法的限流。 - 固定窗口算法:
- 允许定义一个请求速率(如每秒允许的请求数量)和一个时间窗口。
- 当请求到达时,Nginx会检查在当前的时间窗口内是否已经达到了设置的速率限制。
- 如果请求超出了速率限制,Nginx可以配置为返回错误状态码(如503 Service Temporarily Unavailable)或者延迟处理请求。
- 令牌桶算法:
- 通过固定速率向桶中添加令牌。
- 每个请求都需要消耗一个令牌才能被处理。
- 如果桶中有足够的令牌,请求将立即被处理;如果没有令牌,则请求可以被延迟处理或拒绝。
- 这种算法允许一定程度的突发流量,因为桶中可以积累令牌以应对短时间内的请求峰值。
- 基于请求速率的限流:通过
- 基于nginx的限流:针对整体而言
针对科技限流: - 对同一用户限流:了防止某个用户,请求接口次数过于频繁,可以只针对该用户做限制。比如某个id,每分钟只能请求5次接口。 - 对同一ip限流:有时候只对某个用户限流是不够的,有些高手可以模拟多个用户请求,这种nginx就没法识别了。这时需要加同一ip限流功能。 - 对接口限流:别以为限制了用户和ip就万事大吉,有些高手甚至可以使用代理,每次都请求都换一个ip。这时可以限制请求的接口总次数。这种限制对于系统的稳定性是非常有必要的。但可能由于有些非法请求次数太多,达到了该接口的请求上限,而影响其他的正常用户访问该接口。看起来有点得不偿失。 - 加验证码:相对于上面三种方式,加验证码的方式可能更精准一些,同样能限制用户的访问频次,但好处是不会存在误杀的情况。
2. SQL的优化
在平常中我是通过这样去优化慢查询的:
首先通过慢查询日志去定位慢SQL语句,使用mysqldumplow工具分析慢查询日志,找到慢SQL
1
mysqldumpslow -s t -t 10 /var/log/mysql/slow.log
使用EXPLAIN分析SQL语句,主要看这条查询语句当中的
TYPE、key、rows、extra字段,其中type观察该SQL语句的访问类型,是否使用索引,好坏层级为system > const > eq_ref > ref > range > index >ALL,如果是all或index的话,说明走了全表扫描,没有走索引或者索引失效,导致查询慢,尝试使用走索引优化,比如建立复合索引,最少优化到range范围,更好的则尽量ref\const接着通过
key得到实际实际的索引,观察返回的记录数rows是否过多,如果过多则限制返回记录数,比如去除不必要的记录或者将查询分割成小范围查询另外一点的话,如果是index,看是否能直接使用索引覆盖,即
using index1
2
3
4
5+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
| id | select_type | table | type | key | rows | Extra |
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+
| 1 | SIMPLE | orders | ALL | NULL | 10000| Using where |
+----+-------------+--------+------+---------------+------+---------+------+--------+-------------+SQL的重新可以从减少查询数据量、减少返回的记录数、拆分复杂查询出发
1 | // 减少数据量 |
为什么大多数场景下连接查询比嵌套子查询好
- 嵌套子查询可能导致内部查询重复执行,并且零时表的生成和管理增加了额外的开销
- 联合查询通过JOIN一次性将两个表的数据关联合并,生成中间结果集,避免了重复执行。
3. 索引的优化
Mysql索引的优化
- 索引类型选择:MySQL支持多种索引类型,有B+tree索引、哈希索引、全文索引(FULLTEXT,Innodb和MyISAm均支持)。可以根据实际需求选择合适的索引类型,比如B+tree索引适用于要求排序、范围查询等场景;如果是经常查询单条记录,用
=情况,在这样的精确匹配查询下,使用哈希索引合适(MEMORY存储引擎)。 - 选择适当的列建立聚簇索引(适当的列是指频繁查询且唯一的字段,这样对于大多数查询来说都避免了回表查询)
- 建立联合索引:选择多个经常结合查询的字段建立联合索引,并且按照最左前缀匹配,选择性高的字段放在前面。后面在查询过程中能狗进行覆盖索引,这样对于大多数查询来说都避免了回表查询。
- 对于字符类型索引,如果经常查询,可以尝试建立前缀索引,按照区分度选择合适的长度建立
另外,当我们看到慢SQL后,不是马上去建立索引,而是看能不能优化SQL。大多数情况下,业务SQL比较复杂,很难优化,因此建立索引要参照下面的规则:
- (1)索引并非越多越好,大量的索引不仅占用磁盘空间,而且还会影响insert,delete,update等语句的性能
- (2)索引需要维护,因此避免对经常更新的表做更多的索引,并且索引中的列尽可能少;对经常用于查询的字段创建索引,避免添加不必要的索引
- (3)数据量少的表尽量不要使用索引,由于数据较少,查询花费的时间可能比遍历索引的时间还要短,索引可能不会产生优化效果
- (4)在条件表达式中经常用到不同值较多的列上创建索引,在不同值很少的列上不要建立索引
- (5)在频繁进行排序或者分组的列上建立索引,如果排序的列有多个,可以在这些列上建立联合索引,联合索引中列顺序按照选择性排列。
4. mysql死锁的排查
- 开启mysql的死锁日志
1
SET GLOBAL innodb_print_all_deadlock=ON;
- 分析死锁日志
- 检查SQL的执行顺序,观察事务是否因不同顺序访问相同资源导致
1
2
3
4
5
6
7事务1:
BEGIN;
UPDATE accounts SET banlance=banlance-100 WHERE Id=1; 锁住了id=1
UPDATE accounts SET banlance=banlance+100 WHERE Id=2; 尝试锁住id=2
事务2
UPDATE accounts SET banlance=banlance-100 WHERE Id=2; 锁住了id=2
UPDATE accounts SET banlance=banlance+100 WHERE Id=2; 尝试锁住id=1 - 检查是是否走索引,无索引或索引不当会导致锁升级为表锁或间隙锁,增大死锁概率
- 检查SQL的执行顺序,观察事务是否因不同顺序访问相同资源导致
在MySQL种有这样的机制,线程发现死锁后,会主动回滚死锁链条中的某一个事务,让其他事务得以继续执行。可将参数innodb_deadlock_detect设置为on,表示开启这个逻辑。但是它有额外负担的。每当一个事务被锁的时候,就要看看它所依赖的线程有没有被别人锁住,如此循环,消耗大。
5. 数据库,如果突然掉电数据写入失败,redo log也来不及落盘,undo log 也没办法,这种情况怎么办?
针对该问题,我想到有事前的预防措施、事中的高可用架构以及事后的业务层补偿三个方面来解决:
预防措施:避免极端情况的发生:
- 比如使用UPS不间断电源,防止突然断电,提供零时电力完成未提交事物
- BBU电池后备缓存,确保存储设备的缓存数据在断电后仍能写入磁盘
高可用架构设计:考虑容灾和冗余,比如使用MySQL group replication.通过同步或半同步复制,确保事务在多个节点提交后才返回成功,这样即使一个节点宕机了也不影响整体的服务,从节点可以快速接管并恢复服务,
业务层补偿机制:为所有事务生成一个全局的UUID,并在业务层维护一个日志,定时扫描未完成的事务,通过比对数据库的状态与操作日志,触发补偿,达到最终一致性。
MySQL Group Replication基于组复制的概念,并参考了MariaDB Galera Cluster和Percona XtraDB Cluster的设计。它允许数据库服务器组织成一个组,在组内的所有成员之间进行数据复制和同步,以确保数据的一致性和可用性。
- 多主复制:
- MGR支持多主复制模式,即允许多个节点同时处理读写请求,从而提高系统的吞吐量和可靠性。
- 当某个成员执行写操作时,该操作会被记录并复制到组内的其他所有成员。
- 事务一致性:
- 事务的提交必须经过半数以上节点同意方可提交,以确保数据的一致性。
- MGR使用Paxos算法(通过XCom基础设施实现)来确保数据库状态机在节点间的事务一致性。
- 故障检测与自动故障转移:
- MGR具有故障检测机制,当某个成员出现故障时,系统会自动调整组的成员关系。
- 当某个节点发生故障时,Group Replication会自动重新配置集群,确保服务的连续性
6. 布隆过滤器说一下
Linux系统编程_网络
1 TCP/IP协议
TCP/IP协议套件是一个分层联网协议,它包括因特网协议(ip)和位于其上层的各个协议层。
1.1 OSI七层模型和TCP/IP模型
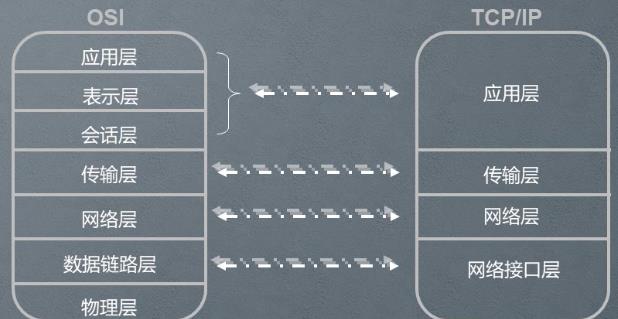 各层协议主要有:
各层协议主要有:
- 应用层协议: FTP(文件传输协议)、HTTP(超文本传输协议)、NFS(网络文件系统)
- 传输层协议: TCP (传输控制协议)、UDP(用户数据报协议)
- 网络层:IP(英特网互联协议)、ICMP(英特网控制报文协议ping) 、IGMP(英特网组管理协议)
- 链路层协议:ARP(地址解析协议 通过ip找mac地址)、RARP:(反向地址解析协议 通过mac找ip)
C++并发编程(一):简介与线程
读者注意:本博客是关于C++11新标准下的并发和多线程编程(C++多线程有C++11、Boost线程库和POSIX多线程三大版本)
- POSIX的线程相关更多的是函数形式,这也理所当然,因此底层是C
- C++标准多线程和Boost线程是类形式,这点要注意。
1 概览
1.1 认识并发
如下图,在单核处理器中我们可看到AB两任务是以“这个任务做一会,再切换到别的任务,再做一会儿”的方式,让任务看起来是并行执行的。这种方式称为“任务切换(task
switching)”。但是,实际上是并发形式的,因为任务切换得太快,以至于无法感觉到任务在何时会被暂时挂起
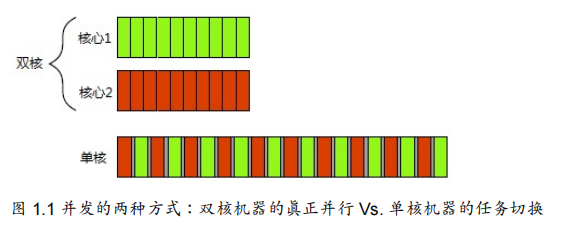 系统每次从一个任务切换到另一个时都需要切换一次上下文(context
switch),任务切换也有时间开销。
系统每次从一个任务切换到另一个时都需要切换一次上下文(context
switch),任务切换也有时间开销。
Linux系统编程_线程
1 线程(熟悉)
进程:程序是存放在存储介质上的一个可执行文件,而进程是程序执行的过程。进程的状态是变化的,其包括进程的创建、调度和消亡。因此程序是静态的,进程是动态的。是CPU分配资源的最小单位
线程:线程(thread)是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。线程是CPU调度的最小单位
1.1 进程和线程的区别
- 进程,直观点说,保存在硬盘上的程序运行以后,会在内存空间里形成一个独立的内存体,这个内存体有自己的地址空间,有自己的堆,上级挂靠单位是操作系统。操作系统会以进程为单位,分配系统资源,所以我们也说,进程是CPU分配资源的最小单位。
Linux系统编程_进程
1 进程概念
1.1 进程和线程的区别
- 进程:程序是存放在存储介质上的一个可执行文件,而进程是程序执行的过程。进程的状态是变化的,其包括进程的创建、调度和消亡。程序是静态的,进程是动态的。是CPU分配资源的最小单位
- 线程:线程(thread)是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。线程是CPU调度的最小单位