并查集
在计算机科学中,并查集是一种树型的数据结构,用于处理一些不交集(Disjoint
Sets)的合并及查询问题。有一个联合-查找算法(union-find
algorithm)定义了两个用于此数据结构的操作:
由于支持这两种操作,一个不相交集也常被称为联合-查找数据结构(union-find
data structure)或合并-查找集合(merge-find
set)。其他的重要方法如MakeSet,用于建立单元素集合。有了这些方法,许多经典的划分问题可以被解决。
并查集的引入
并查集的重要思想在于,用集合中的一个元素代表集合。我曾看过一个有趣的比喻,把集合比喻成帮派,而代表元素则是帮主。接下来我们利用这个比喻,看看并查集是如何运作的。
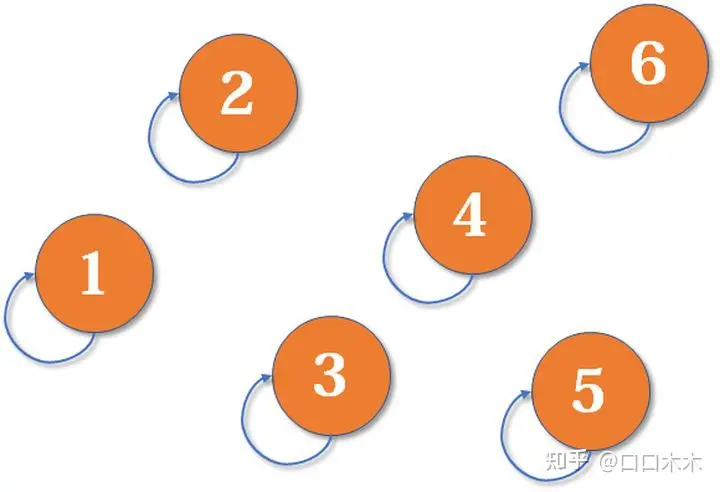
最开始,所有大侠各自为战。他们各自的帮主自然就是自己。(对于只有一个元素的集合,代表元素自然是唯一的那个元素)
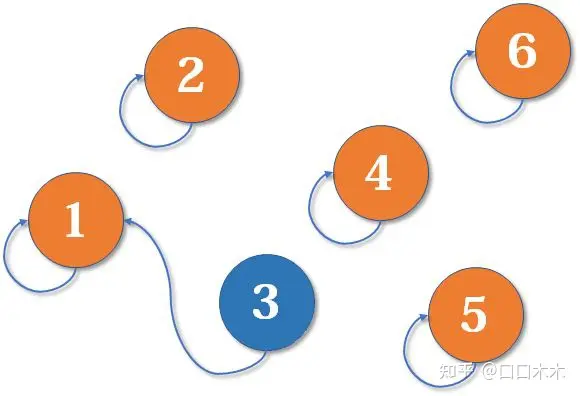
现在1号和3号比武,假设1号赢了(这里具体谁赢暂时不重要),那么3号就认1号作帮主(合并1号和3号所在的集合,1号为代表元素)。
现在2号想和3号比武(合并3号和2号所在的集合),但3号表示,别跟我打,让我帮主来收拾你(合并代表元素)。不妨设这次又是1号赢了,那么2号也认1号做帮主。
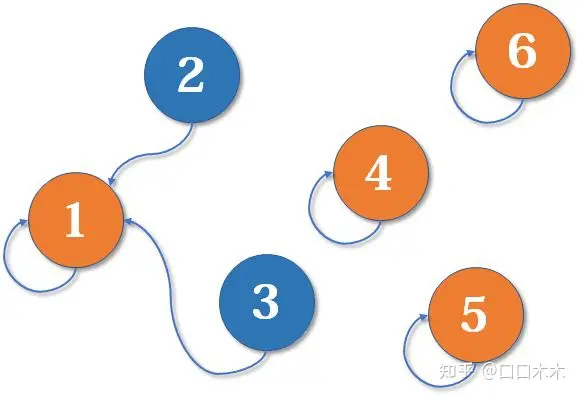
现在我们假设4、5、6号也进行了一番帮派合并,江湖局势变成下面这样:
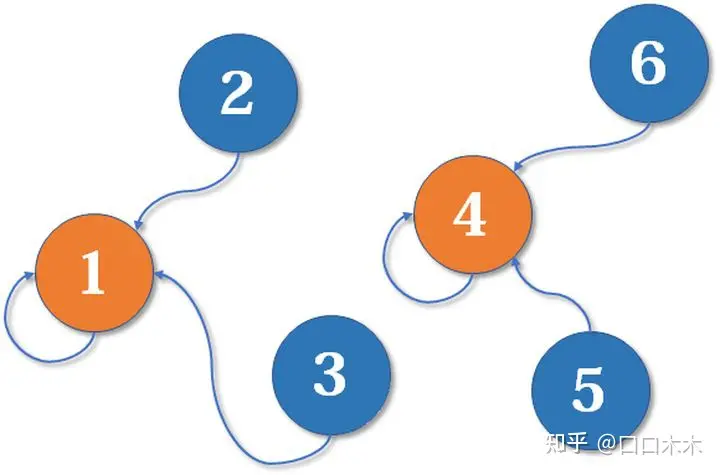
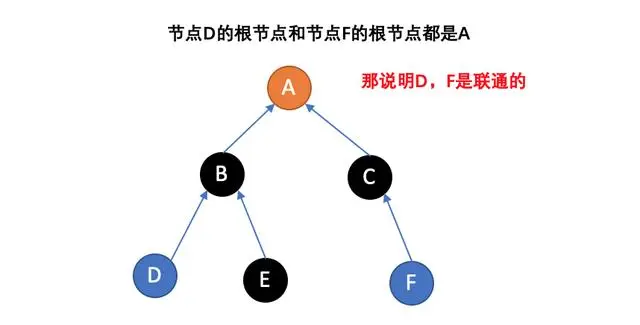
现在假设2号想与6号比,跟刚刚说的一样,喊帮主1号和4号出来打一架(帮主真辛苦啊)。1号胜利后,4号认1号为帮主,当然他的手下也都是跟着投降了。好了,比喻结束了。如果你有一点图论基础,相信你已经觉察到,这是一个树状的结构,要寻找集合的代表元素,只需要一层一层往上访问父节点(图中箭头所指的圆),直达树的根节点(图中橙色的圆)即可。根节点的父节点是它自己。我们可以直接把它画成一棵树:
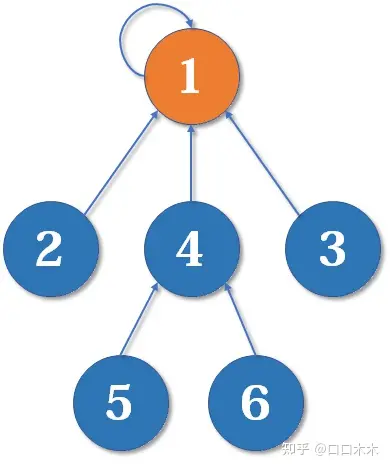
用这种方法,我们可以写出最简单版本的并查集代码。
初始化
1
2
3
4
5
6
| void init(int n){
vector<int> fa(n+1,0);
for(int i = 1;i<=n; ++i){
fa[i]=i;
}
}
|
假如有编号为1, 2, 3, ...,
n的n个元素,我们用一个数组fa[]来存储每个元素的父节点(因为每个元素有且只有一个父节点,所以这是可行的)。一开始,我们先将它们的父节点设为自己。
查询
1
2
3
4
5
6
| int find(int& x){
if(fa[x] == x) return x;
else{
return find(fa[x]);
}
}
|
我们用递归的写法实现对代表元素的查询:一层一层访问父节点,直至根节点(根节点的标志就是父节点是本身)。要判断两个元素是否属于同一个集合,只需要看它们的根节点是否相同即可。
合并
1
2
3
| void merge(int i, int j) {
fa[find(i)] = find(j);
}
|
合并操作也是很简单的,先找到两个集合的代表元素,然后将前者的父节点设为后者即可。当然也可以将后者的父节点设为前者,这里暂时不重要。本文末尾会给出一个更合理的比较方法。
路径压缩(发生在查询时)
随着merge次数的增加,形成的并查集可能会成为一条长长的链,随着链越来越长,我们想要从底部找到根节点的时间复杂度会成为线性。
怎么解决呢?我们可以使用路径压缩的方法。既然我们只关心一个元素对应的根节点,那我们希望每个元素到根节点的路径尽可能短,最好只需要一步,那么这就是我们的路径压缩:
思想是:在查询的过程中,把沿途的的每个节点的父节点都设为根节点,下一次查询时就可以以\(O(1)\)获得根节点
1
2
3
4
5
6
7
| int find(int& x){
if(fa[x]==x) return x;
else{
fa[x] = find(fa[x]);
return fa[x];
}
}
|
按秩合并
有些人可能有一个误解,以为路径压缩优化后,并查集始终都是一个
菊花图 (只有两层的树的俗称)。但其实,由于路径压缩只在
查询 时进行,也只压缩
一条路径,所以并查集最终的结构仍然可能是比较复杂的。例如,现在我们有一棵较复杂的树需要与一个单元素的集合合并:
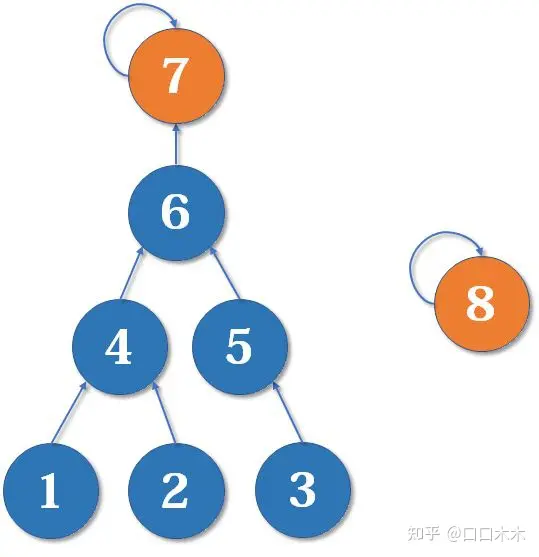 假如这时我们要merge(7,8),如果我们可以选择的话,是把7的父节点设为8好,还是把8的父节点设为7好呢?
假如这时我们要merge(7,8),如果我们可以选择的话,是把7的父节点设为8好,还是把8的父节点设为7好呢?
当然是后者。因为如果把7的父节点设为8,会使树的
深度(树中最长链的长度)加深,原来的树中每个元素到根节点的距离都变长了,之后我们寻找根节点的路径也就会相应变长。虽然我们有路径压缩,但路径压缩也是会消耗时间的。而把8的父节点设为7,则不会有这个问题,因为它没有影响到不相关的节点。
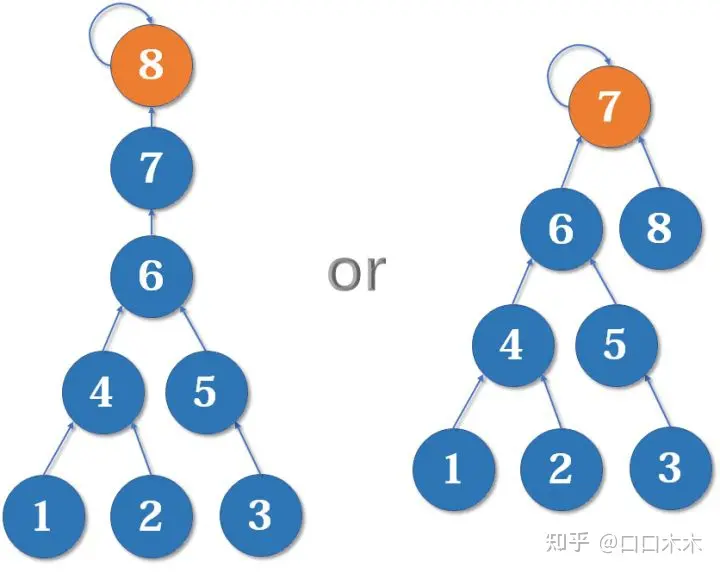
这启发我们:我们应该把简单的树往复杂的树上合并,而不是相反。因为这样合并后,到根节点距离变长的节点个数比较少。
我们用一个数组rank[]记录每个根节点对应的树的深度(如果不是根节点,其rank相当于以它作为根节点的子树的深度)。一开始,把所有元素的rank(秩)设为1。合并时比较两个根节点,把rank较小者往较大者上合并。路径压缩和按秩合并如果一起使用,时间复杂度接近O(n),但是会破坏rank的准确性。
初始化(按秩合并)
1
2
3
4
5
6
7
| void init(int n){
vector<int> fa(n+1,0);
vector<int> rank(n+1,1);
for(int i = 1;i<=n:==i){
fa[i]=i;
}
}
|
合并
1
2
3
4
5
6
7
8
9
10
11
12
| void merge(int i,int j){
int x=find(i),y=find(j);
if(rank[x]<=rank[y]){
fa[x] = y;
}
else{
fa[y] = x;
}
if(rank[x]==rank[y]&&x!=y){
rank[y]++;
}
}
|
总结
- 并查集主要解决的分组管理一类的问题,如果问题能抽象成组与组之间的问题,一般情况下可考虑并查集,并查集的常见思路
是否在一个组; 在一个组的条件;
路径和组在图中都属于连通域,上述组均可替换为路径,问题不变;
- 并查集的主要难点:
Union时,有的问题已经告诉了分组的信息,有的问题则需要自行挖掘;
一般情况下,并查集底层为一个1d数组,有的问题需要对元素进行编号或者转化与之对应;
在不清楚并查集中到底会存放多少数据时,底层也可以map;
并查集功能是Union也就是将两个组合并成一个组,对于拆分的情况,可以逆序思考问题,例如leetcode803
打砖块
根据问题,也可在并查集底层使用其他数据结构,帮助解决问题;
例题
等式方程的可满足性
题目
给定一个由表示变量之间关系的字符串方程组成的数组,每个字符串方程
equations[i]
的长度为4,并采用两种不同的形式之一:"a==b" 或
"a!=b"。在这里,a 和 b
是小写字母(不一定不同),表示单字母变量名。
只有当可以将整数分配给变量名,以便满足所有给定的方程时才返回true,否则返回
false。
分析
分析题目可知,可组等式方程或有关系或无关系,那么因此对所有的方程进行管理,该背景下可考虑使用并查集解决:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| lass UnionFind {
private:
vector<int> parent(26,0);
public:
UnionFind() {
parent.resize(26);
iota(parent.begin(), parent.end(), 0);
}
int find(int index) {
if (index == parent[index]) {
return index;
}
parent[index] = find(parent[index]);
return parent[index];
}
void unite(int index1, int index2) {
parent[find(index1)] = find(index2);
}
};
class Solution {
public:
bool equationsPossible(vector<string>& equations) {
UnionFind uf;
for (const string& str: equations) {
if (str[1] == '=') {
int index1 = str[0] - 'a';
int index2 = str[3] - 'a';
uf.unite(index1, index2);
}
}
for (const string& str: equations) {
if (str[1] == '!') {
int index1 = str[0] - 'a';
int index2 = str[3] - 'a';
if (uf.find(index1) == uf.find(index2)) {
return false;
}
}
}
return true;
}
};
|
参考文献: >并查集