1 信息的存储
大多数的计算机使用8位的块,或者说是字节(byte),作为最小的可寻址内存单位,而不是访问内存中单独的位。机器级程序将内存视为一个非常大的字节数组,我们称为虚拟内存,内存的每个字节都由一个唯一的数字来标识,即称为地址;所有可能的地址空间的集合就是虚拟地址空间。
顾名思义,虚拟地址空间只是一个展现给机器级程序的概念性映像。实际的实现(第九章:虚拟内存)是将DRAM、闪存、磁盘存储器、特殊硬件和操作系统软件结合起来,位程序提供一个看上去统一的字节数组。
1.1 十六进制
在机器世界当中是二进制的,而二进制和十六进制之间的转换比较简单直接,因此在讨论中我们通常不会去说二进制与十进制的转换。
- 在C语言中,十六进程以
0x或者0X开头,字符A~F代表10~15。1
int a =0xa8;
- 在C++中,延续了C的这个特点。同时
cout对象有相应的十六进制输出方式
| ostream成员函数 | 说明 |
|---|---|
flags(fmtfl) |
当前格式状态全部替换为 fmtfl。注意,fmtfl
可以表示一种格式,也可以表示多种格式。 |
precision(n) |
设置输出浮点数的精度为 n。 |
width(w) |
指定输出宽度为 w 个字符。 |
fill(c) |
在指定输出宽度的情况下,输出的宽度不足时用字符 c 填充(默认情况是用空格填充)。 |
setf(fmtfl, mask) |
在当前格式的基础上,追加 fmtfl 格式,并删除
mask 格式。其中,mask 参数可以省略。 |
unsetf(mask) |
在当前格式的基础上,删除 mask 格式。 |
其中,对于上表中 flags() 函数的 fmtfl
参数、setf() 函数中的 fmtfl 参数和
mask 参数以及 unsetf() 函数 mask
参数,可以选择下表中列出的这些值。
| 标 志 | 作 用 |
|---|---|
ios::boolapha |
把 true 和 false 输出为字符串 |
ios::left |
输出数据在本域宽范围内向左对齐 |
ios::right |
输出数据在本域宽范围内向右对齐 |
ios::internal |
数值的符号位在域宽内左对齐,数值右对齐,中间由填充字符填充 |
ios::dec |
设置整数的基数为 10 |
ios::oct |
设置整数的基数为 8 |
ios::hex |
设置整数的基数为 16 |
ios::showbase |
强制输出整数的基数(八进制数以 0 开头,十六进制数以 0x 打头) |
ios::showpoint |
强制输出浮点数的小点和尾数 0 |
ios::uppercase |
在以科学记数法格式 E 和以十六进制输出字母时以大写表示 |
ios::showpos |
对正数显示“+”号 |
ios::scientific |
浮点数以科学记数法格式输出 |
ios::fixed |
浮点数以定点格式(小数形式)输出 |
ios::unitbuf |
每次输出之后刷新所有的流 |
1 | int a=oxa8; |
1.2 字数据大小
每台计算机都有有一个字长(word),指明指针数据的标称大小,因为虚拟地址是以这样的一个字来编码的,所有字长决定的最重要的系统参数就是虚拟地址空间的最大空间,也就是说一个字长位m位的机器,虚拟地址空间的范围为\(0\)~\(2^{(m-1)}\),即32为系统来说,器虚拟内存空间最大为4G,而64位最大可为16EB.
64位机器先后兼容,可运行32位机器编码程序,因此对于下面的伪指令编译
1
2
3
4//32、64均可运行
gcc -m32 prog.c
//只能在64运行
gcc -m64 prog.c
值得一提的是各基础类型在不同机器的字节数:
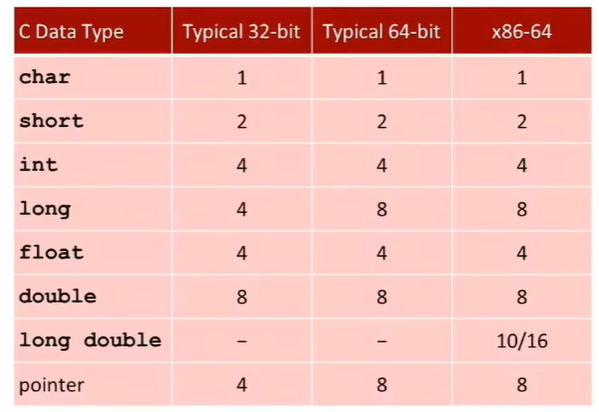
int不管在哪个机器上都是4字节- 而
long在32位位4字节,在64位上位8字节 - 另外为了克服这种在不同机器上字节长度不同的区别,IOS引入了数据大小固定,不随编译器设置带来的变化的类型,如
int32_t和int64_t等等 - 指针为4字节
1.3 寻址和字节顺序
对于跨域多字节的程序对象,必须有两个规则:
- 这个对象的地址是什么:在几乎所有的机器上,多字节对象都被存储为连续的字节序列,对象的地址为所使用字节中最小的地址。
- 这个对象在内存中是如何排列这些字节的:排列ijie有两个通用的规则,一个是大端(网络字节序),一个是小端(主机序);大端字节序在内存中按从最高有效位到最低有效位存储;而小端字节序在内存中按照从最低有效位到最高有效位存储
- 现有一个int型变量,位于初始地址为
0x100,它的十六进制值为0x01234567,则大小端存储如下:
- 现有一个int型变量,位于初始地址为
试用一个程序来输出类型位int、float和void*的字节表示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
typedef unsigned char* byte_pointer;
void show_bytes(byte_pointer start,size_tlen){
size_t i;
for(i=0;i<len;i++)
printf("%2.x ",start[i]); //%2.x表示整数必须用两个16进制输出
printf("\n");
}
void show_int(int x){
show_bytes((byte_pointer)&x,sizeof(int));
}
void show_float(float x){
show_bytes((byte_pointer)&x,sizeof(float));
}
void show_pointer(void*x){
show_bytes((byte_pointer)&x,sizeof(void*));
}
//客户端
int main()
{
int val=12345;
float fval=(float)val;
int *pval=&val;
show_int(val);
show_float(fval);
show_pointer(pval);
}1
2
339 30 00 00
00 e4 40 46
74 f5 cf 38 a3int是采用了小端字节序,float也是使用了小端,但数值比较奇怪,而指针的值是每次都可能会不一样的。
对于int和float的值,看起来很不一样,但是我们把它按位展开,则发现下面有些许相似,如*号处:

这是IEEE单精度标准化的结果
1.4 表示字符串
C语言中字符串编码为一个以null(值为0)字符结尾的字符数组。并且每个字符都以标准编码来表示,如ASCII码。比如,我们若以字符串"12345"来运行show_bytes,得到的结果会是31 32 33 34 35 00。
1
2
3//0~9的数字x的ascii码正好对应0x3x,终止字符对应0x00
const char* s = "12345";
show_bytes((byte_pointer)s, sizeof(s));1
31 32 33 34 35 00
1.5 计算机中的正数和负数是怎么表示的
计算机中数据都有二进制位来存储,目前大多数的计算机都是以补码的形式去存储计算机。正数我们一般都称为正树,正常表示,而负数则采用补码的形式来表达。对于有符号位的数字,最高位为符号位,0为正,1为负
- 正数数:如6,比特为存储为
0110,其计算公式是\(2^2+2^1\) - 负数:如-7,其在计算这样存储
1001,其计算公式为\(-2^7+2^0\),这就是补码的表达方式
负数使用补码来存储,是因为在进行算术运算是与正数没有区别,遵循同一个规则。 也可以这样说有符号数以补码形式存储,只不过非负数得补码是它本身
补码得取反很有意思: 1
2
3
4
5
6
7 int a = INT_MIN;
int b = -a;
int c = -10;
int d = -c;
输出:
-2147483648 -2147483648 -10 10
//对于TMIN得取反还是它本身,其他得正常取反
1.6 算术右移和逻辑右移
在计算机中对左移没有做什么要求,其逻辑左移移总是正确的。但对于右移,则会有相应的算术右移和逻辑右移
- 对于无符号数,我们应当总是采用逻辑右移,如果我们采用了算术右移对
1010右移一位:\(1010----->1101\),然而实际应该是0101 - 对于有符号数,C语言标准没有明确定义使用哪种右移方式,但是一般而言都采用算术右移。
- 比如说-6,补码表示是\(1010\),算术右移一位成\(1101\)为-3,没有错,再右移一位成\(1110\)为-2,但实际上为-1,因此实际上计算机的对负数的算术右移,都会添加一个偏移量。
- 如:\(1010\)加上\(0001\)偏移量得\(1011\),右移得\(1101\),右移再加一个偏移量得\(1110\),右移得\(1111\),此时为
-1正常
1.7 布尔运算
以下操作是按位运算:
&代表位逻辑运算AND|代表位逻辑运算OR^代表位逻辑运算异或~代表位逻辑运算非y>>x对数字y右移x位,相当于\(y/2^x\)y<<x对数字y左移x位,相当于\(y*2^x\)从位运算比普通运算效率更高,位运算能够高效率的完成数值的计算,因为机器本身就是基于二进制的存储和计算,所有的数值或者对象最终都要转化为二进制,对象的话,可能需要一些编解码的动作,位运算主要是针对数据运算的,把人们熟悉的数字转化为机器熟悉的数字,其中又牵扯到原码,反码和补码,补码的出现是为了减低机器运算的复杂度,把减法转变为加法,可以这么说机器运算只有加法和移位,乘法最终是通过加法和移位操作完成的,而除法首先转变为乘法。
交换两个数字,不使用中间变量:
1
2
3a^=b; //a=a^b;
b^=a; //b=a^b^b=a
a^=b; //a=a^b^a=b
1.8 无符号和有符号的转换
有符号数如-8:1000 \[计算方式:-2^4+0*2^3+2*2^1+0*2^0\]
在C/C++中,会有无符号类型的定义,因此当涉及都无符号和有符号整型的转换时,我们必须知道计算机的工作低层原理:
- 计算机中有符号数和无符号数之间的转换规则:数值可能发送了改变,但是位模式不变
- 即在转换当中位不会改变,
-8变为+8:10001
2
3
4int f = INT_MIN;//32位:100000...000
unsigned o = f;//32位:100000...000
输出:
-2147483648 2147483648
无符号有符号转换发送的场景 - 无符号与有符号进行比较,有符号的会向无符号整型提升,此时不安全(向上转换)
- 强制类型转换的时候
2
3
4
5
6
unsigned o = 0;
if (f > o)
cout << "surprise!!" << endl;
//上面的程序在我们人类开来不应该会输出,但是真正情况是:
surprise!!
1.9 溢出与截断
数据存在溢出情况,这是因为计算机要求不能无限制的为能保存一个数而扩充表示位,如int是4字节,对于溢出的数据会进行截断,因此由于截断的存在导致数据的发送错误。
- 正溢出:由正溢出则会导致数据由正变为负值,如
INT_MAX+1,变为INT_MIN - 负溢出:由正溢出则会导致数据由负值变为正值,如
INT_MIN-1,变为INT_MIN
1.10 浮点数
浮点数不同于上面所讲的整数,由IEEE规定特定的存储方式: \[V=(-1)^s*M*2^E\]
- \(s\)为标符号位:标志当前浮点数是正数还是负数
- \(M\)为尾数:它是一个二进制小数,是frac字段的十进制表示。它的范围在规格化是值在\([1,2-\epsilon]\);在非规格化时值在\([0,1-\epsilon]\)
- \(E\):为阶数,其值位阶码字段\(e_{k-1}e_{k-2}...e_0\)的十进制值

对于单精度float来说,其位分布为:1--8--23 双精度double:位分布为1---11---52
1.10.1 三种形式
- 规格化的值:在规格化下,即
exp的位模式不全为0也不全为1,此时E和M计算方式如下: \[E=e-Bias \] \[M=1+f\]
其中\(Bias=2^{k-1}-1\), \(f为frac的小数区域十进制表示\)
非规格化的值:当阶码字段的位模式均为0,此时处于非规格化。非规格化的作用是补充规格化无法趋近于0的,此时E和M计算方式如下: \[E=1-Bias \] \[M=f\]
特殊值:当阶码位模式均为1时,此时处于特殊值情况:
- 当小数域
frac均为0时,此时表示值位无穷大,当s=0时是\(+∞\),当s=1时是-∞ - 当
frac位非0时,此时结果值被表示位NaN,不是一个数。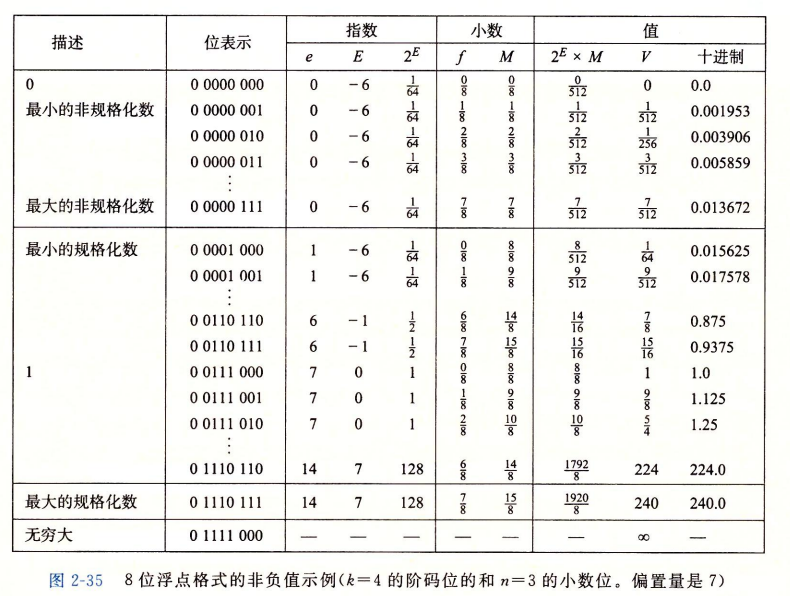
- 当小数域
1.10.2 浮点数与整数的关系
现在来看之前提到过的int和float的关系
它们有相似的区域,这是怎么得来的呢,仔细观察,可由下面推得:
- 首先将int型数字左移13位得到\(1.1000000111001*2^{13}\)
- 由于其\(E=13\),由其计算公式可知,\(e=E+Bias=13+127=140\),处于规格化,符号位为正
- 所以前面的e编码为\(10001100\)
- 将符号位、Exp、frac字段拼接,其中frac中小数点前的1可省略,节约一个位,得到\(01000110010000001110011\)
- 由于单精度,小数区域为23为,在其后面补10个0,得到\(01000110010000001110010000000000\),即如上图所示
1.10.3 浮点数的舍入
因为表示方法限制了浮点数的范围和精度,所以浮点数运算只能近似地表示实数运算。在规范当中有四种舍入方式
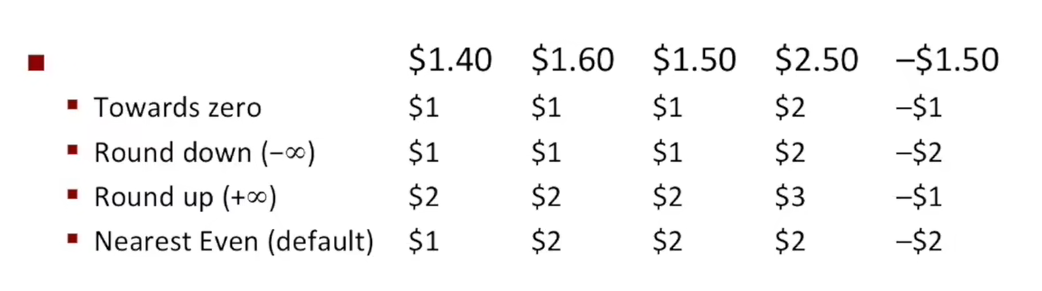
1.10.4 C中的浮点数
C中提供了两种浮点数float和double。挡在int、float和double直接进行强制类型转换时,程序改变数值和位模式的原则如下:
- 从
int转为float,数字不会溢出,但是会被舍入 - 从
int或float转为doubel,能够保留原来的精确的值 - 从
double转为float,值可能会溢出,精度减小,可能会被舍入 -** 从float或double转为int,值会向0舍入,例如1.99将被转换为1**

