1. torch
包 torch 包含了多维张量的数据结构以及基于其上的多种数学操作。另外,它也提供了多种工具,其中一些可以更有效地对张量和任意类型进行序列化。
它有 CUDA 的对应实现,可以在 NVIDIA GPU 上进行张量运算(计算能力>=2.0)。
1.1 Tensor张量
1.1.1 torch.numel
torch.numel(input)->int,返回 input
张量中的元素个数。
- 参数: input (Tensor)为输入张量对象
1
2
3a = torch.randn(1,2,3,4,5)
torch.numel(a)
120
1.2 创建操作
1.2.1 torch.eye
torch.eye(n, m=None, out=None),返回一个 2
维张量,对角线位置全 1,其它位置全 0
n (int )– 行数m (int, optional)– 列数.如果为 None,则默认为 nout (Tensor, optinal)- Output tensor
返回值: 对角线位置全 1,其它位置全 0 的 2 维张量 返回值类型: Tensor
1
2
3
4
5torch.eye(3)
1 0 0
0 1 0
0 0 1
[torch.FloatTensor of size 3x3]
1.2.2 from_numpy
torch.from_numpy(ndarray) → Tensor。将 numpy.ndarray
转换为 pytorch 的 Tensor。返回的张量 tensor 和 numpy的 ndarray
共享同一内存空间。修改一个会导致另外一个也被修改。返回的张量不能改变大小。
1
2
3
4
5
6
7a = numpy.array([1, 2, 3])
t = torch.from_numpy(a)
t
torch.LongTensor([1, 2, 3])
t[0] = -1
a
array([-1, 2, 3])
1.2.3 torch.linspace
torch.linspace(start, end, steps=100, out=None) → Tensor返回一个
1 维张量,包含在区间 start 和 end 上均匀间隔的
step 个点。 输出 1 维张量的长度为
start (float)– 序列的起始点end (float)– 序列的最终值steps (int)– 在 start 和 end 间生成的样本数out (Tensor, optional)– 结果张量1
2
3
4
5
6
7torch.linspace(3, 10, steps=5)
3.0000
4.7500
6.5000
8.2500
10.0000
[torch.FloatTensor of size 5]
1.2.4 torch.ones
torch.ones(*sizes, out=None) → Tensor.返回一个全为 1
的张量,形状由可变参数 sizes 定义。 参数:
sizes (int...)– 整数序列,定义了输出形状out (Tensor, optional)– 结果张量1
2
3
4torch.ones(2, 3)
1 1 1
1 1 1
[torch.FloatTensor of size 2x3]
1.2.5 torch.rand
torch.rand(*sizes, out=None) → Tensor返回一个张量,包含了从区间[0,1)的均匀分布中抽取的一组随机数,形状由可变参数sizes
定义。 参数:
sizes (int...)– 整数序列,定义了输出形状out (Tensor, optinal)- 结果张量1
2
3
4
5
6torch.rand(4)
0.9193
0.3347
0.3232
0.7715
[torch.FloatTensor of size 4]
1.2.6 torch.randn
torch.randn(*sizes, out=None) → Tensor.返回一个张量,包含了从标准正态分布(均值为
0,方差为 1,即高斯白噪声)中抽取一组随机数,形状由可变参数 sizes 定义。
参数:
sizes (int...)– 整数序列,定义了输出形状out (Tensor, optinal)- 结果张量1
2
3
4torch.randn(2, 3)
1.4339 0.3351 -1.0999
1.5458 -0.9643 -0.3558
[torch.FloatTensor of size 2x3]
1.2.7 torch.randperm
torch.randperm(n, out=None) → LongTensor.给定参数
n,返回一个从 0 到 n-1 的随机整数排列。 参数:
n (int)– 上边界(不包含)1
2
3
4
5
6torch.randperm(4)
2
1
3
0
[torch.LongTensor of size 4]
1.2.8 torch.arange
torch.arange(start, end, step=1, out=None) → Tensor。返回一个
1 维张量,长度为
floor((end−start)/step)。包含从start到end,以
step 为步长的一组序列值(默认步长为 1)。 参数:
start (float)– 序列的起始点end (float)– 序列的终止点step (float)– 相邻点的间隔大小1
2
3
4
5torch.arange(1, 4)
1
2
3
[torch.FloatTensor of size 3]
1.2.9 torch.range
torch.range(start, end, step=1, out=None) → Tensor。返回一个
1 维张量,有
floor((end−start)/step)+1个元素。包含在半开区间[start, end)从
start开始,以 step 为步长的一组值。 step 是两个值之间的间隔,即
xi+1=xi+step
警告:建议使用函数 torch.arange()
start (float)– 序列的起始点end (float)– 序列的最终值step (int)– 相邻点的间隔大小1
2
3
4
5
6>>>torch.range(1, 4)
1
2
3
4
[torch.FloatTensor of size 4]
1.2.10 torch.tensor
1 | torch.tensor(data, |
data:数据,可以是list,也可以是numpydtype:数据类型,默认和data一致device:tensor所在的设备requires_grad:是否需要梯度,默认False,在搭建神经网络时需要将求导的参数设为Truepin_memory:是否存于锁页内存,默认False
1.2.11 torch.zeros
返回一个全为标量 0 的张量,形状由可变参数 sizes 定义。 1
2
3
4
5
6torch.zeros(*size,
out=None,
dtype=None,
layout=torch.strided,
device=None,
requires_grad=False) -> Tensorsize:张量的形状,如(3,3) - layout
:这个是内存中的布局形式,有strided和sparse_coo等 -
out:表示输出张量,就是再把这个张量赋值给别的一个张量,但是这两个张量时一样的,指的同一个内存地址
- device:所在的设备,gpu/cpu -
requires_grad:是否需要梯度
1.3 Tensor的常用操作
对于tensor数据我们经常会进行切片、索引、降维、升维、连接等操作。这里介绍一下我们经常用到的。
1.3.1 torch.cat
torch.cat(inputs, dimension=0) → Tensor。在给定维度上对输入的张量序列
seq 进行连接操作。torch.cat()可以看做
torch.split()和 torch.chunk()的反操作。
inputs (sequence of Tensors)– 可以是任意相同 Tensor 类型的 python 序列dimension (int, optional)– 沿着此维连接张量序列。1
2
3
4
5
6
7
8
9
10
11
12
13
14#沿着0维合并
x = torch.randn(2, 3)
x
0.5983 -0.0341 2.4918
1.5981 -0.5265 -0.8735
[torch.FloatTensor of size 2x3]
torch.cat((x, x, x), 0)
0.5983 -0.0341 2.4918
1.5981 -0.5265 -0.8735
0.5983 -0.0341 2.4918
1.5981 -0.5265 -0.8735
0.5983 -0.0341 2.4918
1.5981 -0.5265 -0.8735
[torch.FloatTensor of size 6x3]
1.3.2 torch.chunk
torch.chunk(tensor, chunks, dim=0)。在给定维度(轴)上将输入张量进行分块儿。
tensor (Tensor)– 待分块的输入张量chunks (int)– 分块的个数dim (int)– 沿着此维度进行分块
1.3.3 torch.split
torch.split(tensor, split_size, dim=0)。将输入张量分割成相等形状的
chunks(如果可分)。
如果沿指定维的张量形状大小不能被split_size整分,
则最后一个分块会小于其它分块。
tensor (Tensor)– 待分割张量split_size (int)– 单个分块的形状大小dim (int)– 沿着此维进行分割
1.3.4 torch.squeeze
torch.squeeze(input, dim=None, out=None)。当未给定dim时,将输入张量形状中维度为1
去除并返回。
如果输入是形如(A×1×B×1×C×1×D),那么输出形状就为:(A×B×C×D)
当给定 dim 时 , 那 么 挤 压 操 作 只 在 给 定 维 度 上 。 例 如 ,
输 入 形 状为: (A×1×B), squeeze(input, 0)
将会保持张量不变,只有用
squeeze(input, 1),形状会变成(A×B)。
注意: 返回张量与输入张量共享内存,所以改变其中一个的内容会改变另一个。 参数:
input (Tensor)– 输入张量dim (int, optional)– 如果给定,则 input 只会在给定维度挤压out (Tensor, optional)– 输出张量1
2
3
4
5
6
7
8
9
10
11
12x = torch.zeros(2,1,2,1,2)
x.size()
(2L, 1L, 2L, 1L, 2L)
y = torch.squeeze(x)
y.size()
(2L, 2L, 2L)
y = torch.squeeze(x, 0)
y.size()
(2L, 1L, 2L, 1L, 2L)
y = torch.squeeze(x, 1)
y.size()
(2L, 2L, 1L, 2L)
1.3.5 torch.stack[source]
torch.stack(sequence, dim=0)。沿着一个新维度对输入张量序列进行连接。
序列中所有的张量都应该为相同形状。
参数:
sqequence (Sequence)– 待连接的张量序列dim (int)– 插入的维度。必须介于 0 与 待连接的张量序列数之间。
1.3.6 torch.transpose
torch.transpose(input, dim0, dim1, out=None) → Tensor。交换维度
dim0 和 dim1。
输出张量与输入张量共享内存,所以改变其中一个会导致另外一个也被修改。
input (Tensor)– 输入张量dim0 (int)– 转置的第一维dim1 (int)– 转置的第二维1
2
3
4
5x = torch.randn(2, 3)
x
0.5983 -0.0341 2.4918
1.5981 -0.5265 -0.8735
[torch.FloatTensor of size 2x3]
1.3.7 torch.unsqueeze
torch.unsqueeze(input, dim, out=None)。返回一个新的张量,对输入的制定位置插入维度1
注意:
返回张量与输入张量共享内存,所以改变其中一个的内容会改变另一个。如果
dim 为负,则将会被转化 dim+input.dim()+1
参数:
tensor (Tensor)– 输入张量dim (int)– 插入维度的索引out (Tensor, optional)– 结果张量
1 | x = torch.Tensor([1, 2, 3, 4]) |
2. nn模块
首先应该知道在nn模块当中有两个重要的,分别是torch.nn.Module和nn.functional。torch.nn.Module是所有网络的基类。你的模型也应该继承这个类。
##### 2.1 一般函数 ###### 2.1.1 nn.ModuleList()
将submodules保存在一个list中。ModuleList
可以像一般的 Python list 一样被索引。而且 ModuleList 中包含的 modules
已经被正确的注册,对所有的 module method
可见。它与Sequential()相似,只是为了集成一些操作便于管理。
1
2
3
4
5
6
7
8
9
10
11
12
13for out_channel in vgg_out_channels:
#M为最大池化操作
if out_channel == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
#其他为卷积,输出为指定值,刚开始为3通道
else:
conv2d = nn.Conv2d(in_channel, out_channel, 3, 1, 1)
layers += [conv2d, nn.ReLU(inplace=True)]
in_channel = out_channel
self.vgg = nn.ModuleList(layers)
使用:
feats = self.vgg[idx](feats)
2.1.2 nn.Sequential()
torch.nn.Sequential是一个Sequential容器,模块将按照构造函数中传递的顺序添加到模块中。另外,也可以传入一个有序模块。具体理解如下:
1
2
3
4
5self.covn1=nn.Sequential(nn.Conv2d(96, 96, 3, 1, 1), nn.BatchNorm2d(96), nn.ReLU(inplace=True),
nn.Conv2d(96, 32, 3, 1, 1), nn.BatchNorm2d(32), nn.ReLU(inplace=True))
使用:
features=self.covn1(features)
2.1.3 torch.nn.Parameter()
torch.nn.Parameter继承torch.Tensor,其作用将一个不可训练的类型为Tensor的参数转化为可训练的类型为parameter的参数,并将这个参数绑定到module里面,成为module中可训练的参数。
1
torch.nn.Parameter(Tensor data, bool requires_grad)
2.2 卷积函数和层次常用
2.2.1 Conv1d
1 | torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, |
2.2.2 Conv2d
1 | torch.nn.Conv2d(in_channels, |
in_channels(int)– 输入信号的通道out_channels(int)– 卷积产生的通道kerner_size(int or tuple)- 卷积核的尺寸stride(int or tuple, optional)- 卷积步长padding(int or tuple, optional)- 输入的每一条边补充 0 的层数dilation(int or tuple, optional)– 定义了卷积核处理数据时各值的间距。换句话说,相比原来的标准卷积,扩张卷积多了一个超参数称之为dilation rate(扩张率),指的是kernel各点之间的间隔数量,正常的卷积核的dilation为1。groups(int, optional)– 从输入通道到输出通道的阻塞连接数bias(bool, optional)- 如果 bias=True,添加偏置
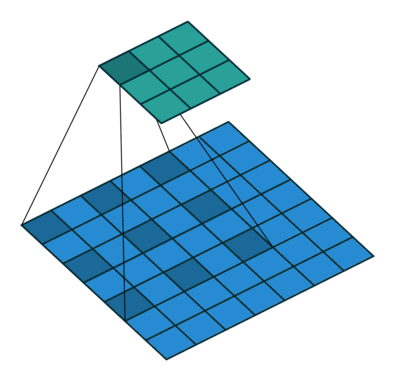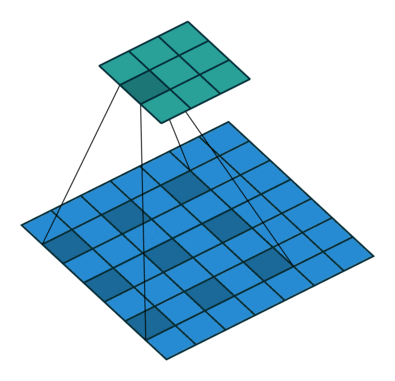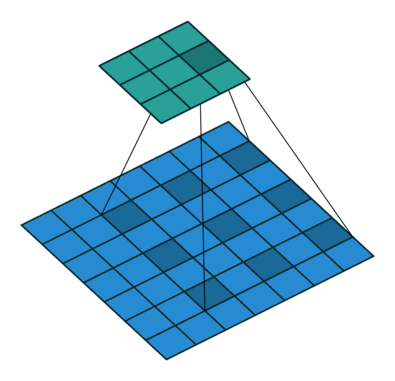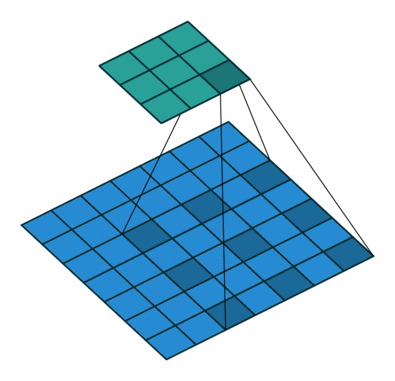 上图是一个扩张率为2,尺寸为 3×3
的空洞卷积,感受野与5×5的卷积核相同,而且仅需要9个参数。在相同的计算条件下,空洞卷积提供了更大的感受野,获得更为丰富的上下文信息。
上图是一个扩张率为2,尺寸为 3×3
的空洞卷积,感受野与5×5的卷积核相同,而且仅需要9个参数。在相同的计算条件下,空洞卷积提供了更大的感受野,获得更为丰富的上下文信息。
2.2.3 Conv3d
三维卷积层,
输入的尺度是(N, C_in,D,H,W),输出尺度(N,C_out,D_out,H_out,W_out)
1
2torch.nn.Conv3d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1,
groups=1, bias=True)
2.2.4 ConvTranspose1d
1 | torch.nn.ConvTranspose1d(in_channels, out_channels, kernel_size, stride=1, padding=0, |
1 维的解卷积操作(transposed convolution operator,注意改视作操作可视作解卷积操作,但并不是真正的解卷积操作) 该模块可以看作是 Conv1d 相对于其输入的梯度,有时(但不正确地)被称为解卷积操作
注意:由于内核的大小,输入的最后的一些列的数据可能会丢失。因为输入和输出是不是完全的互相关。因此,用户可以进行适当的填充(padding 操作)。
2.2.5 ConvTranspose2d
1 | torch.nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, |
2 维的转置卷积操作(transposed convolution operator,注意改视作操作可视作解卷积操作,但并不是真正的解卷积操作) 该模块可以看作是 Conv2d 相对于其输入的梯度,有时(但不正确地)被称为解卷积操作。
2.2.6 nn.Linear
对输入数据做线性变换:$y=Ax+b#,也是我们MLP中使用的函数
1
torch.nn.Linear(in_features, out_features, bias=True)
in_features - 每个输入样本的大小 -
out_features - 每个输出样本的大小 - bias -
若设置为 False,这层不会学习偏置。默认值:True
2.2.7 Dropout
随机以概率p将输入张量中部分元素设置为 0。对于每次前向调用,被置 0
的元素都是随机的 1
torch.nn.Dropout(p=0.5, inplace=False)
p - 将元素置 0
的概率。默认值:0.5 - in-place - 若设置为
True,会在原地执行操作。默认值:False
2.3 池化函数
2.3.1 MaxPool2d
对于输入信号的输入通道,提供 2 维最大池化(max
pooling)操作。如果输入的大小是(N,C,H,W),那么输出的大小是(N,C,H_out,W_out)。即只会改变矩阵大小,不会改变通道数量。
1
nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
kernel_size(int or tuple) - max
pooling的窗口大小 - stride(int or tuple, optional) - max
pooling的窗口移动的步长。默认值是kernel_size -
padding(int or tuple, optional) - 输入的每一条边补充0的层数
- dilation(int or tuple, optional) –
每个点之间的间隙,空洞卷积会用到 - return_indices -
如果等于True,会返回输出最大值的序号,对于上采样操作会有帮助 -
ceil_mode -
如果等于True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取整的操作
2.3.2 MaxUnpool2d
Maxpool2d的逆过程,不过并不是完全的逆过程,因为在 maxpool2d
的过程中,一些值的已经丢失。 MaxUnpool2d 的输入是 MaxPool2d
的输出,包括最大值的索引,并计算所有 maxpool2d
过程中非最大值被设置为零的部分的反向 1
torch.nn.MaxUnpool2d(kernel_size, stride=None, padding=0)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27>>> pool = nn.MaxPool2d(2, stride=2, return_indices=True)
>>> unpool = nn.MaxUnpool2d(2, stride=2)
>>> input = Variable(torch.Tensor([[[[ 1, 2, 3, 4],
... [ 5, 6, 7, 8],
... [ 9, 10, 11, 12],
... [13, 14, 15, 16]]]]))
>>> output, indices = pool(input)
>>> unpool(output, indices)
Variable containing:
(0 ,0 ,.,.) =
0 0 0 0
0 6 0 8
0 0 0 0
0 14 0 16
[torch.FloatTensor of size 1x1x4x4]
>>>
>>> unpool(output, indices, output_size=torch.Size([1, 1, 5, 5]))
Variable containing:
(0 ,0 ,.,.) =
0 0 0 0 0
6 0 8 0 0
0 0 0 14 0
16 0 0 0 0
0 0 0 0 0
[torch.FloatTensor of size 1x1x5x5]
class torch.nn.MaxUnpool3d(kernel_size, stride=None, padding=0)
2.3.3 AvgPool2d
对信号的输入通道,提供 2 维的平均池化(average pooling
)。输入信号的大小(N,C,H,W),输出大小(N,C,H_out,W_out)和池化窗口大小(kH,kW)的关系是
1
2torch.nn.AvgPool2d(kernel_size, stride=None, padding=0, ceil_mode=False,
count_include_pad=True)
2.3.4 AdaptiveMaxPool2d
对输入信号,提供 1 维的自适应最大池化操作
对于任何输入大小的输入,可以将输出尺寸指定为H,但是输入和输出特征的数目不会变化
1
torch.nn.AdaptiveMaxPool2d(output_size, return_indices=False)
output_size: 输出信号的尺寸
return_indices: 如果设置为 True,会返回输出的索引。对 nn.MaxUnpool1d 有用,默认值是 False
2.4 归一化函数
2.4.1 BatchNorm2d
对于所有的batch中样本的同一个channel的数据元素进行标准化处理,即如果有C个通道,无论batch中有多少个样本,都会在通道维度上进行标准化处理,一共进行C次。
\[ y={{x-mean(x)}\over{\sqrt{var(x)+eps}}}×γ+β \]
- 在训练时,该层计算每次输入的均值与方差,并进行移动平均。移动平均默认的动量值为 0.1。
- 在验证时,训练求得的均值/方差将用于标准化验证数据。
1 | torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True) |
num_features: 来自期望输入的特征数,该期望输入的大小为batch_size × num_features × height × widtheps: 为保证数值稳定性(分母不能趋近或取 0),给分母加上的值。默认为 1e-5。momentum: 动态均值和动态方差所使用的动量。默认为 0.1。affine: 一个布尔值,当设为 true,给该层添加可学习的仿射变换参数。
momentum的作用:BatchNorm2d里面存储均值(running_mean)和方差(running_var)更新时的参数。
\[
x_{new}=(1-momentum)*x_{old}+momentum*x_{obser}
\] 其中\(x_{old}\)为BatchNorm2d里面的均值(running_mean)和方差(running_var),\(x_{0bser}\)为当前观测值(样本)的均值或方差,\(x_{new}\)更新后的均值或方差(最后需要重新存储到BatchNorm2d中),momentum为更新参数
2.5 functional模块
2.5.1 interpolate()函数
torch.nn.functional.interpolate实现插值和上采样。上采样,在深度学习框架中,可以简单的理解为任何可以让你的图像变成更高分辨率的技术即矩阵升维。
最简单的方式是重采样和插值:将输入图片input
image进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值bilinear等插值方法对其余点进行插值。
1
torch.nn.functional.interpolate(input, size=None, scale_factor=None, mode='nearest', align_corners=None)
input (Tensor) – 输入张量
size (int or Tuple[int] or Tuple[int, int] or Tuple[int, int, int])– 输出大小.scale_factor (float or Tuple[float])– 指定输出为输入的多少倍数。如果输入为tuple,其也要制定为tuple类型mode (str)– 可使用的上采样算法,有’nearest’, ‘linear’, ‘bilinear’, ‘bicubic’ , ‘trilinear’和’area’. 默认使用’nearest
2.6 nn.Module
注意下面的这些函数都是Module这个类的成员函数,不同于上面的一般函数为全局函数。下面的modle都指代模型对象
2.6.1 parameter()
model.parameters(),这个是成员函数,指获取该模型的所有参数,一般我们再把模型参数传递给优化器是会使用到。
1
2params = model.parameters()
optimizer = torch.optim.Adam(params, config.TRAIN['learning_rate'])
2.6.2 add_module(name, module)
该函数是一个成岩函数。将一个 child module 添加到当前
modle。 被添加的 module 可以通过
name 属性来获取 1
2
3
4
5
6
7
8
9add_module(name, module)
例子:
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.add_module("conv", nn.Conv2d(10, 20, 4))
#self.conv = nn.Conv2d(10, 20, 4) 和上面这个增加 module 的方式等价
model = Model()
2.6.3 children()
该函数返回当前模型子模块的迭代器。 1
2
3
4
5
6
7
8
9
10
11
12
13import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.add_module("conv", nn.Conv2d(10, 20, 4))
self.add_module("conv1", nn.Conv2d(20 ,10, 4))
model = Model()
for sub_module in model.children():
print(sub_module)
输出:
Conv2d(10, 20, kernel_size=(4, 4), stride=(1, 1))
Conv2d(20, 10, kernel_size=(4, 4), stride=(1, 1))
2.6.4 cpu(device_id=None)和cuda(device_id=None)
cpu(device_id=None)和cuda(device_id=None)将所有的模型参数(parameters)和
buffers 赋值给CPU或者GPU 1
2
3
4
5
6modle=modle.cuda()
for i, (images, gts, depths) in enumerate(train_loader, start=1):
optimizer.zero_grad()
images = images.cuda()
gts = gts.cuda()
depths=depths.cuda()to()函数: 1
2device = torch.device("cuda")
images, gts, depths, = images.to(device), gts.to(device), depths.to(device)
2.6.5 eval()和train模式
eval()将模型设置成 evaluation 模式仅仅当模型中有 Dropout
和 BatchNorm
是才会有影响;train()将模型设置为训练模式,会有优化操作,即梯度下降和反向传播算法。
2.6.6 state_dict (dict)
state_dict是一个简单的python的字典对象,将每一层与它的对应参数建立映射关系.(如model的每一层的weights及偏置等等)。注意只有那些参数可以训练的layer才会被保存到模型的state_dict中,如卷积层,线性层等等
state_dict是在定义了model或optimizer之后pytorch自动生成的,可以直接调用.常用的保存state_dict的格式是".pt"或'.pth'的文件,即下面命令的 PATH="./***.pt"1
torch.save(model.state_dict(), PATH)
load_state_dict也是model或optimizer之后pytorch自动具备的函数,可以直接调用1
2
3model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
model.eval()
2.6.7 modules()
返回一个包含 当前模型 所有模块的迭代器。 1
2
3
4
5
6
7
8
9
10for module in model.modules():
print(module)
输出:
Model (
(conv): Conv2d(10, 20, kernel_size=(4, 4), stride=(1, 1))
(conv1): Conv2d(20, 10, kernel_size=(4, 4), stride=(1, 1))
)
Conv2d(10, 20, kernel_size=(4, 4), stride=(1, 1))
Conv2d(20, 10, kernel_size=(4, 4), stride=(1, 1))modules()返回的 iterator
不止包含子模块,还有父模块。这是和 children()的不同。
2.6.8 named_children()
返回包含模型当前子模块的迭代器,yield
模块名字和模块本身。 1
2
3for name, module in model.named_children():
if name in ['conv4', 'conv5']:
print(module)name_modules
2.7 激活函数
2.7.1 ReLU
对输入运用修正线性单元函数\({ReLU}(x)=
max(0, x)\), 1
torch.nn.ReLU(inplace=False)
2.7.2 Sigmoid
对每个元素运用 Sigmoid 函数,Sigmoid 定义如下:\(f(x)=1/(1+e^{−x})\) 1
torch.nn.Sigmoid
2.7.3 Softmax
对 n 维输入张量运用 Softmax
函数,将张量的每个元素缩放到(0,1)区间且和为 1。 1
torch.nn.Softmax

