1、pytorch简介
pytorch是一个基于Python的科学计算包,PyTorch 的设计遵循tensor→variable(autograd)→nn.Module 三个由低到高的抽象层次,分别代表高维数组(张量)、自动求导(变量)和神经网络(层/模块),而且这三个抽象之间联系紧密,可以同时进行修改和操作。它主要有两个用途:
- 类似于Numpy但是能利用GPU加速
- 一个非常灵活和快速用于深度学习的研究平台
2、基本数据结构:Tensor
Tensor在pttorch中负责存储基本数据,ptyTorch针对Tensor也提供了丰富的函数和方法,所以pyTorch中的Tensor与Numpy的数组具有极高的相似性。Tensor是一种高级的API。
Tensor即张量,张量是Pytorch的核心概念,pytorch的计算都是基于张量的计算,是PyTorch中的基本操作对象,可以看做是包含单一数据类型元素的多维矩阵。从使用角度来看,Tensor与NumPy的ndarrays非常类似,相互之间也可以自由转换,只不过Tensor还支持GPU的加速
| 数据类型 | CPU Tensor | GPU Tensor |
|---|---|---|
| 32位浮点 | torch.FloatTensor |
torch.cuda.FloatTensor |
| 64位浮点 | torch.DoubleTensor |
torch.cuda.DoubleTensor |
| 16位半精度浮点 | N/A |
torch.cuda.HalfTensor |
| 8位无符号整型 | torch.ByteTensor |
torch.cuda.ByteTensor |
| 8位有符号整型 | torch.charTensor |
torch.cuda.charTensor |
| 16位有符号整型 | torch.ShortTensor |
torch.cuda.ShortTensor |
| 32位有符号整型 | torch.IntTensor |
torch.cuda.IntTensor |
| 64位有符号整型 | torch.LongTensor |
torch.cuda.LongTensor |
pytorch不支持str类型
2.1 Tensor的创建
1 | torch.tensor(data, |
data:数据,可以是list,也可以是numpydtype:数据类型,默认和data一致device:tensor所在的设备requires_grad:是否需要梯度,默认False,在搭建神经网络时需要将求导的参数设为Truepin_memory:是否存于锁页内存,默认False
还有其他的按数值创建的方法,这里只列举一个: 1
2
3
4
5
6torch.zeros(*size,
out=None,
dtype=None,
layout=torch.strided,
device=None,
requires_grad=False) -> Tensorsize:张量的形状,如(3,3) - layout
:这个是内存中的布局形式,有strided和sparse_coo等 -
out:表示输出张量,就是再把这个张量赋值给别的一个张量,但是这两个张量时一样的,指的同一个内存地址
- device:所在的设备,gpu/cpu -
requires_grad:是否需要梯度
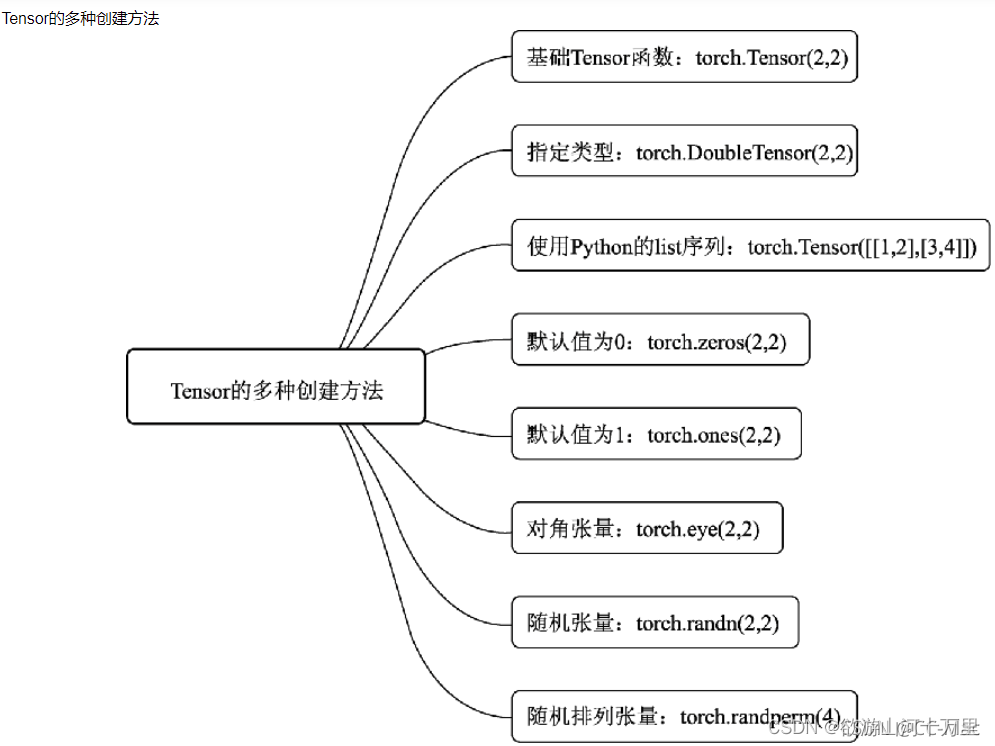
1 | #使用特定类型构造函数创建 |
2.2 张量的尺寸
可以使用shape属性或者size()方法查看张量在每一维的长度.
1
2t=torch.randn(2,2)
print(t.shape,t.size())1
torch.Size([2, 2]) torch.Size([2, 2])
也能使用可以使用view()方法改变张量的尺寸。如果view()方法改变尺寸失败,可以使用reshape()方法
1
2b=torch.FloatTensor([[1,2,3],[4,5,6]])
m=b.view(3,2) #将2*3转为3*21
m=b.reshape(3,2)
2.3 Tensor和numpy数组
可以用numpy方法从Tensor得到numpy数组,也可以用torch.from_numpy从numpy数组得到Tensor。这两种方法关联的Tensor和numpy数组是共享数据内存的,即改变其中一个,另一个也会发生改变。因此如果不需要共享,可以用张量的clone()方法拷贝张量,中断这种关联
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import numpy as np
import torch
#torch.from_numpy函数从numpy数组转为Tensor
arr = np.zeros(3)
tensor = torch.from_numpy(arr)
np.add(arr,1, out = arr) #给arr增加1,tensor也随之改变
print(arr)
print(tensor)
#使用clone
# 可以用clone() 方法拷贝张量,中断这种关联
tensor = torch.zeros(3)
#使用clone方法拷贝张量, 拷贝后的张量和原始张量内存独立
arr = tensor.clone().numpy() # 也可以使用tensor.data.numpy()
#将Torch Tensor转换为Numpy array
a = torch.ones(5)
b = a.numpy()1
2[1. 1. 1.]
tensor([1., 1., 1.], dtype=torch.float64)
2.4 Tensor操作
Tensor同样跟python一样支持切片、合并分割操作和相应的数学运算 ######
2.4.1 索引切片
切片时支持缺省参数和省略号。可以通过索引和切片对部分元素进行修改。
1
2t=torch.randn(5,6)
m=t[0:-1:2,1:-1:3] #表示从第一行到最后一行每隔一行取一行,从第二列到最后一列每隔两列取一列
2.4.2 合并分割
- 可以用
torch.cat()方法和torch.stack()方法将多个张量合并, - 可以用
torch.split()方法把一个张量分割成多个张量。 torch.cat()和torch.stack()有略微的区别,torch.cat()是连接,不会增加维度,而torch.stack()是堆叠, 会增加维度
1 | a=torch.tensor([[1,2],[3,4]]) |
输出: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19tensor([[ 1, 2],
[ 3, 4],
[ 5, 6],
[ 7, 8],
[ 9, 10],
[11, 12]])
tensor([[[ 1, 2],
[ 3, 4]],
[[ 5, 6],
[ 7, 8]],
[[ 9, 10],
[11, 12]]])
tensor([[1, 2],
[3, 4]]) tensor([[5, 6],
[7, 8]]) tensor([[ 9, 10],
[11, 12]])
2.5 Tensor的运算操作
张量数学运算主要有:标量运算,向量运算,矩阵运算。
2.5.1 标量运算
加减乘除乘方,以及三角函数,指数,对数等常见函数,逻辑比较运算符等都是标量运算符。标量运算符的特点是对张量实施逐元素运算。有些标量运算符对常用的数学运算符进行了重载,并且支持类似numpy的广播特性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147#例1-3-1 张量的数学运算-标量运算
import torch
import numpy as np
a = torch.tensor([[1.0,2],[-3,4.0]])
b = torch.tensor([[5.0,6],[7.0,8.0]])
a+b #运算符重载
out:
tensor([[ 6., 8.],
[ 4., 12.]])
a-b
out:
tensor([[ -4., -4.],
[-10., -4.]])
a*b
out:
tensor([[ 5., 12.],
[-21., 32.]])
a/b
out:
tensor([[ 0.2000, 0.3333],
[-0.4286, 0.5000]])
a**2
out:
tensor([[ 1., 4.],
[ 9., 16.]])
a**(0.5)
out:
tensor([[1.0000, 1.4142],
[ nan, 2.0000]])
a%3 #求模
out:
tensor([[1., 2.],
[-0., 1.]])
a//3 #地板除法
out:
tensor([[ 0., 0.],
[-1., 1.]])
a>=2 # torch.ge(a,2) #ge: greater_equal缩写
out:
tensor([[False, True],
[False, True]])
(a>=2)&(a<=3)
out:
tensor([[False, True],
[False, False]])
(a>=2)|(a<=3)
out:
tensor([[True, True],
[True, True]])
a==5 #torch.eq(a,5)
out:
tensor([[False, False],
[False, False]])
torch.sqrt(a)
out:
tensor([[1.0000, 1.4142],
[ nan, 2.0000]])
a = torch.tensor([1.0,8.0])
b = torch.tensor([5.0,6.0])
c = torch.tensor([6.0,7.0])
d = a+b+c
print(d)
out:
tensor([12., 21.])
print(torch.max(a,b))
out:
tensor([5., 8.])
print(torch.min(a,b))
out:
tensor([1., 6.])
x = torch.tensor([2.6,-2.7])
print(torch.round(x)) #保留整数部分,四舍五入
print(torch.floor(x)) #保留整数部分,向下归整
print(torch.ceil(x)) #保留整数部分,向上归整
print(torch.trunc(x)) #保留整数部分,向0归整
out:
tensor([ 3., -3.])
tensor([ 2., -3.])
tensor([ 3., -2.])
tensor([ 2., -2.])
x = torch.tensor([2.6,-2.7])
print(torch.fmod(x,2)) #作除法取余数
print(torch.remainder(x,2)) #作除法取剩余的部分,结果恒正
out:
tensor([ 0.6000, -0.7000])
tensor([0.6000, 1.3000])
# 幅值裁剪
x = torch.tensor([0.9,-0.8,100.0,-20.0,0.7])
y = torch.clamp(x,min=-1,max = 1)
z = torch.clamp(x,max = 1)
print(y)
print(z)
out:
tensor([ 0.9000, -0.8000, 1.0000, -1.0000, 0.7000])
tensor([ 0.9000, -0.8000, 1.0000, -20.0000, 0.7000])
2.5.2 向量运算
向量运算符只在一个特定轴上运算,将一个向量映射到一个标量或者另外一个向量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88#例1-3-2 张量的数学运算-向量运算
import torch
#统计值
a = torch.arange(1,10).float()
print(torch.sum(a))
print(torch.mean(a))
print(torch.max(a))
print(torch.min(a))
print(torch.prod(a)) #累乘
print(torch.std(a)) #标准差
print(torch.var(a)) #方差
print(torch.median(a)) #中位数
out:
tensor(45.)
tensor(5.)
tensor(9.)
tensor(1.)
tensor(362880.)
tensor(2.7386)
tensor(7.5000)
tensor(5.)
#指定维度计算统计值
b = a.view(3,3)
print(b)
print(torch.max(b,dim = 0))
print(torch.max(b,dim = 1))
out:
tensor([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]])
torch.return_types.max(
values=tensor([7., 8., 9.]),
indices=tensor([2, 2, 2]))
torch.return_types.max(
values=tensor([3., 6., 9.]),
indices=tensor([2, 2, 2]))
#cum扫描
a = torch.arange(1,10)
print(torch.cumsum(a,0))
print(torch.cumprod(a,0))
print(torch.cummax(a,0).values)
print(torch.cummax(a,0).indices)
print(torch.cummin(a,0))
out:
tensor([ 1, 3, 6, 10, 15, 21, 28, 36, 45])
tensor([ 1, 2, 6, 24, 120, 720, 5040, 40320, 362880])
tensor([1, 2, 3, 4, 5, 6, 7, 8, 9])
tensor([0, 1, 2, 3, 4, 5, 6, 7, 8])
torch.return_types.cummin(
values=tensor([1, 1, 1, 1, 1, 1, 1, 1, 1]),
indices=tensor([0, 0, 0, 0, 0, 0, 0, 0, 0]))
#torch.sort和torch.topk可以对张量排序
a = torch.tensor([[9,7,8],[1,3,2],[5,6,4]]).float()
print(torch.topk(a,2,dim = 0),"\n")
print(torch.topk(a,2,dim = 1),"\n")
print(torch.sort(a,dim = 1),"\n")
out:
torch.return_types.topk(
values=tensor([[9., 7., 8.],
[5., 6., 4.]]),
indices=tensor([[0, 0, 0],
[2, 2, 2]]))
torch.return_types.topk(
values=tensor([[9., 8.],
[3., 2.],
[6., 5.]]),
indices=tensor([[0, 2],
[1, 2],
[1, 0]]))
torch.return_types.sort(
values=tensor([[7., 8., 9.],
[1., 2., 3.],
[4., 5., 6.]]),
indices=tensor([[1, 2, 0],
[0, 2, 1],
[2, 0, 1]]))
2.5.3 矩阵运算
矩阵必须是二维的,类似torch.tensor([1,2,3])这样的不是矩阵。矩阵运算包括:矩阵乘法,矩阵转置,矩阵逆,矩阵求迹,矩阵范数,矩阵行列式,矩阵求特征
值,矩阵分解等运算 1
2
3
4
5#例1-3-3 张量的数学运算-矩阵运算
import torch
#矩阵乘法
a = torch.tensor([[1,2],[3,4]])
b = torch.tensor([[5,6],[7,8]]a@b,也可以函数torch.matmul(a,b)或者`torch.mm(a,b)
1 | a@b |
输出: 1
2
3
4
5
6tensor([[19, 22],
[43, 50]])
tensor([[19, 22],
[43, 50]])
tensor([[19, 22],
[43, 50]])
2. 矩阵转置:转置直接使用其成员函数t()
1
2
3
4
5a.t()
out:
tensor([[1., 3.],
[2., 4.]])
3.
逆矩阵:求逆使用Tensorde1inverse()函数。矩阵逆,必须为浮点类型
1
2
3
4
5torch.inverse(a)
out:
tensor([[-2.0000, 1.0000],
[ 1.5000, -0.5000]], dtype=torch.float64)
4. 矩阵求Tr 1
2
3
4
5a = torch.tensor([[1.0,2],[3,4]])
print(torch.trace(a))
out:
tensor(5.)
5. 矩阵求范数 1
2
3
4torch.norm(a)
out:
tensor(5.4772)
6. 矩阵行列式 1
2
3
4torch.det(a)
out:
tensor(-2.0000)
7. 矩阵特征值和特征向量 1
2
3k=torch.tensor([[1,2],[-5,4]],dtype=float)
L_complex,V_complex=torch.linalg.eig(k)
print(L_complex,V_complex)
8. 矩阵QR分解:将一个方阵分解为一个正交矩阵q和上三角矩阵r。QR分解实际上是对矩阵a实施Schmidt正交化得到q
1 | a=torch.tensor([[1,2],[3,4]],dtype=float) |
9.
矩阵svd分解:svd分解可以将任意一个矩阵分解为一个正交矩阵u,一个对角阵s和一个正交矩阵v.t()的乘积,svd常用于矩阵压缩和降维
1
2u,s,v=torch.linalg.svd(a)
print(u,"\n",s,"\n",v)1
2
3
4
5tensor([[-0.4046, -0.9145],
[-0.9145, 0.4046]], dtype=torch.float64)
tensor([5.4650, 0.3660], dtype=torch.float64)
tensor([[-0.5760, -0.8174],
[ 0.8174, -0.5760]], dtype=torch.float64)
2.6 广播机制
Pytorch的广播规则和numpy是一样的:
1、如果张量的维度不同,将维度较小的张量进行扩展,直到两个张量的维度都一样。
2、如果两个张量在某个维度上的长度是相同的,或者其中一个张量在该维度上的长度为1, 那么我们就说这两个张量在该维度上是相容的。
3、如果两个张量在所有维度上都是相容的,它们就能使用广播。
4、广播之后,每个维度的长度将取两个张量在该维度长度的较大值。
5、在任何一个维度上,如果一个张量的长度为1,另一个张量长度大于1,那么在该维度上,就好像是对第一个张量进行了复制。 torch.broadcast_tensors可以将多个张量根据广播规则转换成相同的维度。
1 | #例 1-3-4 广播机制 |
3. 其他基础知识
上面介绍了pytorch的数据结构Tensor以及Tensor的一些操作函数,这里介绍深度学习必须用到的微分求导和动态计算图。
3.1 自动微分机制
神经网络通常依赖反向传播求梯度来更新网络参数,求梯度过程通常是一件非常复杂而容易出错的事情。而深度学习框架可以帮助我们自动地完成这种求梯度运算。这就是Pytorch的自动微分机制是指:
-
Pytorch一般通过反向传播backward()方法实现这种求梯度计算。该方法求得的梯度将存在对应自变量张量的grad·属性下。 - 除此之外,也能够调用torch.autograd.grad()`函数来实现求梯度计算。
3.1.1 backward方法求导数
1 | torch.autograd.backward( |
tensor:表示用于求导的张量,如loss,gradient: 设置梯度权重,在计算矩阵的梯度时会用到,也是一个tensor,shape和前面的tensor保持一致retain_graph:表示保存计算图,由于pytorch采用了动态图机制,在每一次反向传播之后,计算图都会被释放掉。如果不想释放,就设置这个参数为Truecreate_graph:创建导数计算图,用于高阶求导
注:tensor类的backward()函数内部调用了torch.autograd.backward()
backward()方法通常在一个标量张量上调用,该方法求得的梯度将存在对应自变量张量的grad属性下。如果调用的张量非标量,则要传入一个和它同形状的gradient参数张量,改张量是设置梯度权重的。相当于用该gradient参数张量与调用张量作向量点乘,得到的标量结果再反向传播。
下面分别介绍标量和非标量的反向传播:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31#标量的反向传播
def test():
#f=ax**2+bx+c
x=torch.tensor(1.0,requires_grad=True)
a=torch.tensor(1.0)
b=torch.tensor(-2.0)
c=torch.tensor(5.6)
y=a*torch.pow(x,2)+b*x+c
y.backward()
dy_dx=x.grad
print(dy_dx)
输出:
tensor(0.)
#非标量的反向传播
def test1():
# f=ax**2+bx+c
x=torch.tensor([[0.0,1.0],[5.0,2.0]],requires_grad=True)
a = torch.tensor(1.0)
b = torch.tensor(-2.0)
c = torch.tensor(5.6)
y = a * torch.pow(x, 2) + b * x + c
gradient = torch.tensor([[1.0, 1.0], [1.0, 1.0]])
y.backward(gradient=gradient)
dy_dx=x.grad
print(dy_dx)
输出:
tensor([[-2., 0.],
[ 8., 2.]])
注:非标量的反向传播也可以用标量的反向传播实现,如下只需加一句z = torch.sum(y*gradient),然后以z.backward()即可
1
2
3
4z = torch.sum(y*gradient)
z.backward()
x_grad = x.grad
print(x_grad)
3.1.2 利用autograd.grad方法求导数
torch.autograd.grad()这个方法的功能也是求梯度,可以实现高阶的求导。
1
2
3
4
5
6
7
8
9torch.autograd.grad(
outputs: Union[torch.Tensor, Sequence[torch.Tensor]],
inputs: Union[torch.Tensor, Sequence[torch.Tensor]],
grad_outputs: Union[torch.Tensor, Sequence[torch.Tensor], NoneType] = None,
retain_graph: Union[bool, NoneType] = None,
create_graph: bool = False,
only_inputs: bool = True,
allow_unused: bool = False,
) -> Tuple[torch.Tensor, ...]outputs:用于求导的张量; -
inputs: 需要梯度的张量; -
create_graph:创建导数计算图,用于高阶求导 -
retain_graph:保存计算图 -
grad_outputs:多梯度权重
1 | #例2-1-2 利用autograd.grad方法求导数 |
3.1.3 利用自动微分和优化器求最小值
1 | #例2-1-3 利用自动微分和优化器求最小值 |
注:优化器后续讲解
3.2 动态计算图
Pytorch的计算图由节点和边组成,节点表示张量或者Function,边表示张量和Function之间的依赖关系。Pytorch中的计算图是动态图。
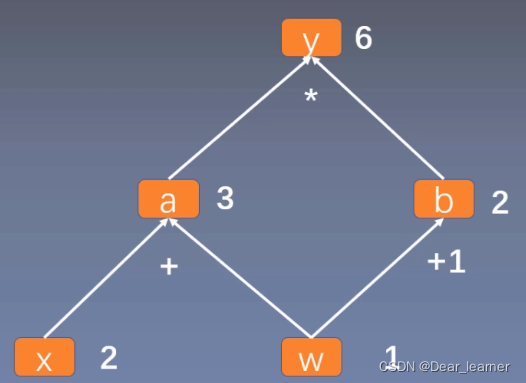 从上面可以看出\(y = a × b\),而\(a = w + x, b = w + 1\),只要给出\(x\)和\(w\)的值,即可根据计算图得出\(y\)的值。上图中用求y对w的导数,根据求导规则,如下:
\[
{δy\over δw}={δy\over δa}{δa\over δw}+{δy \over δb}{δb \over δw}\\
=b*1+a*1\\
=b+a\\
=(w+1)+(x+w)\\
=2*w+x+1\\
=2*1+2+1\\
=5
\] 体现到计算图中,就是根节点 y 到叶子节点 w 有两条路径 y -> a
-> w和y ->b ->
w。根节点依次对每条路径的叶子节点求导,一直到叶子节点w,最后把每条路径的导数相加即可
从上面可以看出\(y = a × b\),而\(a = w + x, b = w + 1\),只要给出\(x\)和\(w\)的值,即可根据计算图得出\(y\)的值。上图中用求y对w的导数,根据求导规则,如下:
\[
{δy\over δw}={δy\over δa}{δa\over δw}+{δy \over δb}{δb \over δw}\\
=b*1+a*1\\
=b+a\\
=(w+1)+(x+w)\\
=2*w+x+1\\
=2*1+2+1\\
=5
\] 体现到计算图中,就是根节点 y 到叶子节点 w 有两条路径 y -> a
-> w和y ->b ->
w。根节点依次对每条路径的叶子节点求导,一直到叶子节点w,最后把每条路径的导数相加即可
 在tensor中包含一个
在tensor中包含一个is_leaf(叶子节点)属性,叶子节点就是用户创建的节点,在上面的例子中,\(x\) 和\(w\)
是叶子节点,其他所有节点都依赖于叶子节点。叶子节点的概念主要是为了节省内存,在计算图中的一轮反向传播结束之后,非叶子节点的梯度是会被释放的。
只有叶子节点的梯度保留了下来,而非叶子的梯度为空,如果在反向传播之后仍需要保留非叶子节点的梯度,可以对节点使用retain_grad=True
1
2
3
4
5#查看是否是叶子节点
print(w.is_leaf, x.is_leaf, a.is_leaf, b.is_leaf)
###result
True True False False
3.2.1 何为动态
这里的动态主要有两重含义:
第一层含义是:计算图的正向传播是立即执行的。无需等待完整的计算图创建完毕,每条语句都会在计算图中动态添加节点和边,并立即执行正向传播得到计算结果。
第二层含义是:计算图在反向传播后立即销毁。下次调用需要重新构建计算图。如果在程序中使用了
backward()方法执行了反向传播,或者利用torch.autograd.grad()方法计算了梯度,那么创建的计算图会被立即销毁,释放存储空间,下次调用需要重新创建
1 | #例2-2-1 计算图的正向传播是立即执行的 |
3.2.1 动态图机制
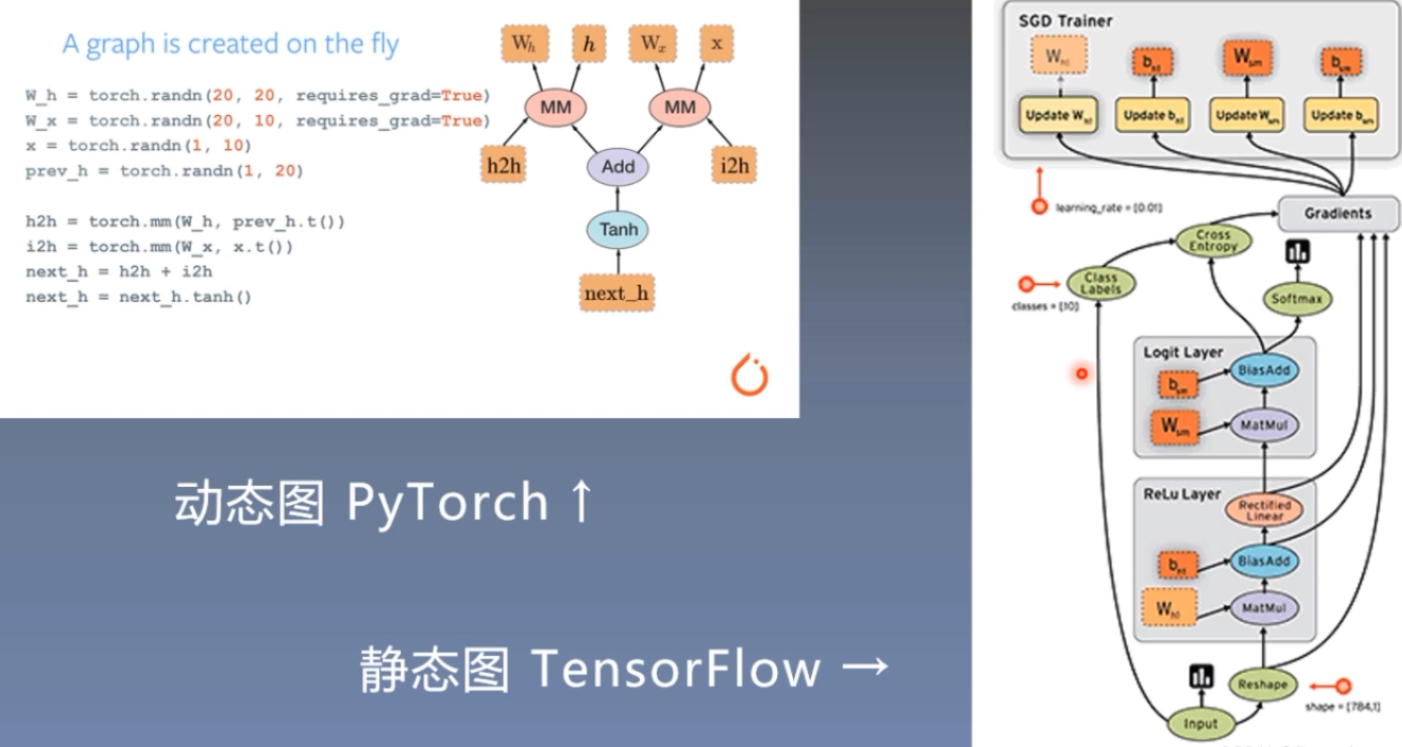
pytroch采用的是动态图机制,而tensorflow采用的是静态图机制。静态图是先搭建,后运算;动态图是运算和搭建同时进行,也就是可以先计算前面节点的值,再根据这些值搭建后面的计算图。优点是灵活,易调节,易调试。
4. 数据的读取
机器学习的五大模块分别是:数据、模块、损失函数、优化器和迭代训练。这里我们介绍数据模块,要对模型进行训练必须要有数据,怎么讲数据读取进来存储是我们要解决的问题。数据模块又可分为以下几部分:
- 数据的收集:
Image、label - 数据的划分:
train、test、valid - 数据的读取:
DataLoader,有两个子模块,Sampler和Dataset,Sampler是对数据集生成索引,DataSet是根据索引读取数据 - 数据预处理:
torchvision.transforms模块
Pytorch通常使用Dataset和DataLoader这两个工具类来构建数据管道:
Dataset定义了数据集的内容,它相当于一个类似列表的数据结构,具有确定的长度,能够用索 引获取数据集中的元素。DataLoader定义了按batch加载数据集的方法,它是一个实现了__iter__方法的可迭代对象,每次迭代输出一个batch的数据。DataLoader能够控制batch的大小,batch中元素的采样方法,以及将batch结果整理成模型所需 输入形式的方法,并且能够使用多进程读取数据。在绝大部分情况下,用户只需实现
Dataset的__len__方法和__getitem__方法,就可以轻松构 建自己的数据集,并用默认数据管道进行加载
4.1 DataLoader和DataSet概述
4.1.1 获取一个batch数据的步骤
让我们考虑一下从一个数据集中获取一个batch的数据需要哪些步骤。 (假定数据集的特征和标签分别表示为张量 \(X\) 和 \(Y\) ,数据集可以表示为 \((X,Y)\) , 假定batch大小为\(m\) )
- 首先我们要确定数据集的长度\(n\) ,假设$ n = 1000$ 。
- 然后我们从\(0\) 到\(n-1\)的范围中抽样出\(m\)个数(batch大小)。假定\(m=4\), 拿到的结果是一个列表,类似: \(indices = [1,4,8,9]\)
- 接着我们从数据集中去取这 m 个数对应下标的元素。 拿到的结果是一个元组列表,类似: \(samples = [(X[1],Y[1]),(X[4],Y[4]),(X[8],Y[8]), (X[9],Y[9])]\)
- 最后我们将结果整理成两个张量作为输出。 拿到的结果是两个张量,类似$ batch = (features,labels)$其中 \(features = torch.stack([X[1],X[4],X[8],X[9]]) labels = torch.stack([Y[1],Y[4],Y[8],Y[9]])\)
4.1.2 Dataset和DataLoader的功能分工
上述第a个步骤确定数据集的长度是由
Dataset的__len__方法实现的。第b个步骤从\(0\) 到\(n-1\)的范围中抽样出 m 个数的方法是由
DataLoader的sampler和batch_sampler参数指定的。sampler参数指定单个元素抽样方法,一般无需用户设置,程序默认在DataLoader的参数shuffle=True时采用随机抽样,shuffle=False时采用顺序抽样。batch_sampler参数将多个抽样的元素整理成一个列表,一般无需用户设置,默认方法在DataLoader的参数drop_last=True时会丢弃数据集最后一个长度不能被batch大小整除的批次,在drop_last=False时保留最后一个批次。第c个步骤的核心逻辑根据下标取数据集中的元素 是由
Dataset的__getitem__方法实现的。第d个步骤的逻辑由
DataLoader的参数collate_fn指定。一般情况下也无需用户设置。
4.2 使用Dataset创建数据集
Dataset创建数据集常用的方法有以下几个:
- 使用
torch.utils.data.TensorDataset根据Tensor创建数据集(numpy的array,Pandas的DataFrame需要先转换成Tensor)。
- 使用
- 使用
torchvision.datasets.ImageFolder根据图片目录创建图片数据集。1
2
3
4
5
6
7
8
9
10dataset=torchvision.datasets.ImageFolder(
root, transform=None,
target_transform=None,
loader=<function default_loader>,
is_valid_file=None)
root:图片存储的根目录,即各类别文件夹所在目录的上一级目录。
transform:对图片进行预处理的操作(函数),原始图片作为输入,返回一个转换后的图片。
target_transform:对图片类别进行预处理的操作,输入为 target,输出对其的转换。如果不传该参数,即对 target 不做任何转换,返回的顺序索引 0,1, 2…
loader:表示数据集加载方式,通常默认加载方式即可。
is_valid_file:获取图像文件的路径并检查该文件是否为有效文件的函数(用于检查损坏文件)
- 使用
- 继承
torch.utils.data.Dataset创建自定义数据集。
- 继承
- 此外,还可以通过
torch.utils.data.random_split将一个数据集分割成多份,常用于分割训练集,验证集和测试集。
- 此外,还可以通过
- 调用
Dataset的加法运算符( + )将多个数据集合并成一个数据集。
- 调用
1 | #例4-2-1 根据Tensor创建数据集 |
1 | #4-2-2 根据图片目录创建图片数据集 |
1 | #例4-2-3 创建自定义数据集 |
4.3 使用DataLoader加载数据集
DataLoader能够控制batch的大小,batch中元素的采样方法,以及将batch结果整理成模型所需输入形式的方法,并且能够使用多进程读取数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14DataLoader(
dataset,
batch_size=1,
shuffle=False,
sampler=None,
batch_sampler=None,
num_workers=0,
collate_fn=None,
pin_memory=False,
drop_last=False,
timeout=0,
worker_init_fn=None,
multiprocessing_context=None,
)dataset, batch_size, shuffle, num_workers, drop_last这五个参
数,其他参数使用默认值即可。
dataset: 数据集batch_size: 批次大小shuffle: 是否乱序sampler: 样本采样函数,一般无需设置。batch_sampler: 批次采样函数,一般无需设置。num_workers: 使用多进程读取数据,设置的进程数。collate_fn: 整理一个批次数据的函数。pin_memory: 是否设置为锁业内存。默认为False,锁业内存不会使用虚拟内存(硬盘),从锁 业内存拷贝到GPU上速度会更快。drop_last: 是否丢弃最后一个样本数量不足batch_size批次数据。timeout: 加载一个数据批次的最长等待时间,一般无需设置。worker_init_fn: 每个worker中dataset的初始化函数,常用于terableDataset。一般不使用。
1 | #例3-3 使用DataLoader加载数据集 |
5. 数据的预处理模块
transforms是pytorch中常用的图像预处理方法,这个在torchvision计算机视觉工具包中。在安装pytorch时顺便安装了torchvision,在torchvision中,有三个主要的模块:
torchvision.transforms:常用的图像预处理方法,比如:标准化、中心化、旋转、翻转等;torchvision.datasets:常用的数据集的dataset实现,例如:MNIST、CIFAR-10、ImageNet等;torchvision.models:常用的预训练模型,AlexNet、VGG、ResNet等。
5.1 裁剪
5.1.1 随机裁剪:transforms.RandomCrop
该函数根据给定的size进行随机裁剪 1
2
3
4
5
6
7transforms.RandomCrop(
size,
padding=None,
pad_if_needed=False,
fill=0,
padding_mode='constant',
)
`padding·:可为int or sequence,此参数是设置填充多少个pixel;若为int,表示图像上下左右均填充int个pixel,例如padding=4,表示图像上下左右均填充4个pixel,若为32×32,则图像填充后为40×40;若为sequence,若为2个数,第一个数表示左右填充多少,第二个数表示上下填充多少;当有四个数时表示左、上、右、下
·pad_if_needed·:若图像小于设定的size,则填充;
fill:表示需要填充的值,默认为0.当值为int时,表示各通道均填充该值,当值为3时,表示RGB三个通道各需要填充的值;
padding_mode:填充模式,有4中填充模式:- 1、
constant:常数填充; - 2、
edge:图像的边缘值填充; - 3、
reflect:镜像填充,最后一个像素不镜像,例如 [1, 2, 3, 4]. -> [3, 2, 1, 2, 3, 4, 3, 2]; - 4、
symmetric:镜像填充,最后一个元素填充,例如:[1, 2, 3, 4] -> [2, 1, 1, 2, 3, 4, 4, 3]
- 1、
5.1.2 中心裁剪transforms.CenterCrop
依据给定的参数进行中心裁剪 1
2
3torchvision.transforms.CenterCrop(size)
size:若为sequence,则为(h, w), 若为int, 则为(int, int)
5.1.3 随机长宽比裁剪transforms.RandomResizedCrop()
随机大小,随机长宽比裁剪原始图片,最后将图片 resize 到设定好的 size
1
2
3
4
5
6torchvision.transforms.RandomResizedCrop(
size,
scale=(0.08, 1.0),
ratio=(0.75, 1.3333333333333333),
interpolation=2,
)size:所需裁减图片尺寸 -
scale:随机 crop 的大小区间,如 scale=(0.08, 1.0),表示随机
crop 出来的图片会在的 0.08 倍至 1 倍之间。 - ratio:
随机长宽比设置
5.1.4 上下左右中心裁剪transforms.FiveCrop()
对图片进行上下左右以及中心裁剪,获得 5 张图片,返回一个 4D-tensor
1
torchvision.transforms.FiveCrop(size)
5.2 翻转和旋转
5.2.1 翻转
1 | #依据概率 p 对 PIL 图片进行水平翻转 |
5.2.2 旋转
依 degrees 随机旋转一定角度 1
2torchvision.transforms.RandomRotation(degrees, resample=False,
expand=False, center=None)degress:(sequence or float or int) ,若为单个数,如
30,则表示在(-30,+30)之间随机旋转;若为sequence,如(30,60),则表示在
30-60 度之间随机旋转; - resample:重采样方法选择,可选
PIL.Image.NEAREST, PIL.Image.BILINEAR,PIL.Image.BICUBIC,默认为最近邻; -
expand: 是否扩大图片,以保持原图信息; -
center: 设置旋转点,默认是中心旋转
5.3 图像变换
5.3.1 resize
重置图像分辨率 1
torchvision.transforms.Resize(size, interpolation=2)
5.3.2 标准化
对数据按通道进行标准化,即先减均值,再除以标准差,注意是 hwc
1
torchvision.transforms.Normalize(mean, std)
5.3.3 转化为Tensor:transforms.ToTensor
将 PIL Image 或者 ndarray 转换为
tensor,并且归一化至[0-1]。注意归一化至[0-1]是直接除以 255,若自己的
ndarray 数据尺度有变化,则需要自行修改。 1
torchvision.transforms.ToTensor()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23#transfomrs.Compose()表示按顺序执行
data_transforms = {
'train':
transforms.Compose([
transforms.Resize([96, 96]),
transforms.RandomRotation(45),#随机旋转,-45到45度之间随机选
transforms.CenterCrop(64),#从中心开始裁剪
transforms.RandomHorizontalFlip(p=0.5),#随机水平翻转 选择一个概率概率
transforms.RandomVerticalFlip(p=0.5),#随机垂直翻转
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),#参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相
transforms.RandomGrayscale(p=0.025),#概率转换成灰度率,3通道就是R=G=B
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])#均值,标准差
]),
'valid':
transforms.Compose([
transforms.Resize([64, 64]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
#使用datasets.ImageFloder()读取数据
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'valid']}
6. pytorch的模型搭建torch.nn模块
机器学习的五大板块之一就是模型,好的模型事半功倍。
6.1 nn.functional 和 nn.Module
Pytorch和神经网络相关的功能组件大多都封装在 torch.nn模块下。
这些功能组件的绝大部分既有函数形式nn.funtional实现,也有类形式nn.Module实现。
其中nn.functional(一般引入后改名为F)有各种功能组件的函数实现,例如: -
激活函数:
F.relu 、F.sigmoid 、F.tanh 、F.softmax
模型层:
F.linear(全连接)、F.conv2d(2d卷积)、F.max_pool2d(2d最大池化)、F.dropout2d、 F.embedding损失函数:
F.binary_cross_entropy 、F.mse_loss 、F.cross_entropy(交叉熵损失函数)
但为了进一步便于对参数进行管理,一般通过继承 nn.Module 转换成为类的实现形式,并直接封装在 nn 模块下,例如:
激活函数:
nn.ReLU 、 nn.Sigmoid 、 nn.Tanh 、nn.Softmax模型层:
nn.Linear 、nn.Conv2d 、nn.MaxPool2d 、nn.Dropout2d 、nn.Embedding损失函数:
nn.BCELoss 、 nn.MSELoss 、 nn.CrossEntropyLoss
实际上nn.Module除了可以管理其引用的各种参数,还可以管理其引用的子模块,功能十分强大
6.2 使用nn.Module来管理参数
在Pytorch中,模型的参数是需要被优化器训练的,因此,通常要设置参数为requires_grad = True的张量。
同时,在一个模型中,往往有许多的参数,要手动管理这些参数并不是一件容易的事情。
Pytorch一般将参数用nn.Parameter来表示,并且用nn.Module来管理其结构下的所有参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44#模型,模型自动生成权值矩阵\卷积核
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # 输入大小 (1, 28, 28)
nn.Conv2d(
in_channels=1, # 灰度图
out_channels=16, # 要得到几多少个特征图
kernel_size=5, # 卷积核大小
stride=1, # 步长
padding=2, # 如果希望卷积后大小跟原来一样,需要设置padding=(kernel_size-1)/2 if stride=1
), # 输出的特征图为 (16, 28, 28)
nn.ReLU(), # relu层
nn.MaxPool2d(kernel_size=2), # 进行池化操作(2x2 区域), 输出结果为: (16, 14, 14)
)
self.conv2 = nn.Sequential( # 下一个套餐的输入 (16, 14, 14)
nn.Conv2d(16, 32, 5, 1, 2), # 输出 (32, 14, 14)
nn.ReLU(), # relu层
nn.Conv2d(32, 32, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2), # 输出 (32, 7, 7)
)
self.conv3 = nn.Sequential( # 下一个套餐的输入 (16, 14, 14)
nn.Conv2d(32, 64, 5, 1, 2), # 输出 (32, 14, 14)
nn.ReLU(), # 输出 (32, 7, 7)
)
self.out = nn.Linear(64 * 7 * 7, 10) # 全连接层得到的结果
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(x.size(0), -1) # flatten操作,结果为:(batch_size, 32 * 7 * 7)
output = self.out(x)
return output
# 实例化
net = CNN()
#损失函数
criterion = nn.CrossEntropyLoss()
#优化器,nn.paarameters管理参数
optimizer = optim.Adam(net.parameters(), lr=0.001) #定义优化器,普通的随机梯度下降算法
6.2 使用nn.Module来管理子模块
一般情况下,我们都很少直接使用
nn.Parameter来定义参数构建模型,而是通过一些拼装一些常用的模型层来构造模型,如上面的CNN类拼接了模型层,自动生成参数值由nn.parameters管理。这些模型层也是继承自nn.Module的对象,本身也包括参数,模型层属于我们要定义的模块的子模块。
nn.Module提供了一些方法可以管理这些子模块。
children(): 返回生成器,包括模块下的所有子模块。named_children():返回一个生成器,只有模块下的所有子模块,以及它们的名字。modules():返回一个生成器,不仅返回模块下的子模块,连子模块下的子模块也会被返回,包括模块本身。named_modules():返回一个生成器,包括模块下的所有各个层级的模块以及它们的名字,包括模块本身。
上面函数返回一个可迭代的生成器,可通过for循环查看返回值。见PyTorch中的modules()和children()相关函数简析
6.3 模型层
深度学习模型一般由各种模型层组合而成,torch.nn中内置了非常丰富的各种模型层。它们都属于nn.Module的子类,具备参数管理功能,如上面提到的nn.Linear、 nn.Flatten、 nn.Dropout, nn.BatchNorm2d、nn.Conv2d、nn.AvgPool2d、nn.Conv1d、nn.ConvTranspose2d、nn.Embedding、nn.GRU、nn.LSTM、nn.Transformer,下面一小结我们将列举pytorch内置的模型层
如果这些内置模型层不能够满足需求,我们也可以通过继承nn.Module基类构建自定义的模型层。实际上,pytorch不区分模型和模型层,都是通过继承nn.Module进行构建。因此,我们只要继承nn.Module基类并实现forward方法即可自定义模型层。
6.4 内置模型层
这里只对相应的模型层做一个简介,详细的API文档查阅官方文档 ######
6.4.1 基础层 - nn.Linear:全连接层。参数个数 =
输入层特征数× 输出层特征数(weight)+ 输出层特征数 (bias)
nn.Flatten:压平层,用于将多维张量样本压成一维张量样本。nn.BatchNorm1d:一维批标准化层。通过线性变换将输入批次缩放平移到稳定的均值和标准差。可以增强模型对输入不同分布的适应性,加快模型训练速度,有轻微正则化效果。一般在激活函数之前使用。可以用afine参数设置该层是否含有可以训练的参数。nn.BatchNorm2d:二维批标准化层。nn.BatchNorm3d:三维批标准化层。nn.Dropout:一维随机丢弃层。一种正则化手段。nn.Dropout2d:二维随机丢弃层。nn.Dropout3d:三维随机丢弃层。nn.Threshold:限幅层。当输入大于或小于阈值范围时,截断之。nn.ConstantPad2d: 二维常数填充层。对二维张量样本填充常数扩展长度。nn.ReplicationPad1d: 一维复制填充层。对一维张量样本通过复制边缘值填充扩展长度。nn.ZeroPad2d:二维零值填充层。对二维张量样本在边缘填充0值.nn.GroupNorm:组归一化。一种替代批归一化的方法,将通道分成若干组进行归一。不受 batch大小限制,据称性能和效果都优于BatchNorm。nn.LayerNorm:层归一化。较少使用。nn.InstanceNorm2d: 样本归一化。较少使用。
6.4.2 卷积网络相关层
nn.Conv1d:普通一维卷积,常用于文本。参数个数 = 输入通道数×卷积核尺寸(如3)×卷积核个数 + 卷积核个数nn.Conv2d:普通二维卷积,常用于图像。参数个数 = 输入通道数×卷积核尺寸(如3乘3)×卷积核个数 + 卷积核个数。通过调整dilation参数大于1,可以变成空洞卷积,增大卷积核感受野。 通过调整groups参数不为1,可以变成分组卷积。分组卷积中不同分组使用相同的卷积核,显著减少参数数量。 当groups参数等于通道数时,相当于tensorflow中的二维深度卷积层tf.keras.layers.DepthwiseConv2D。 利用分组卷积和1乘1卷积的组合操作,可以构造相当于Keras中的二维深度可分离卷积层tf.keras.layers.SeparableConv2D。nn.Conv3d:普通三维卷积,常用于视频。参数个数 = 输入通道数×卷积核尺寸(如3乘3乘3)× 卷积核个数 + 卷积核个数。nn.MaxPool1d: 一维最大池化。nn.MaxPool2d:二维最大池化。一种下采样方式。没有需要训练的参数。nn.MaxPool3d:三维最大池化。nn.AdaptiveMaxPool2d:二维自适应最大池化。无论输入图像的尺寸如何变化,输出的图像尺寸是固定的。 该函数的实现原理,大概是通过输入图像的尺寸和要得到的输出图像的 尺寸来反向推算池化算子的padding,stride等参数。nn.FractionalMaxPool2d:二维分数最大池化。普通最大池化通常输入尺寸是输出的整数 倍。而分数最大池化则可以不必是整数。分数最大池化使用了一些随机采样策略,有一定的 正则效果,可以用它来代替普通最大池化和Dropout层。
nn.AvgPool2d:二维平均池化。nn.AdaptiveAvgPool2d:二维自适应平均池化。无论输入的维度如何变化,输出的维度是固定的。nn.ConvTranspose2d:二维卷积转置层,俗称反卷积层。并非卷积的逆操作,但在卷积核相同的情况下,当其输入尺寸是卷积操作输出尺寸的情况下,卷积转置的输出尺寸恰好是卷积操作的输入尺寸。在语义分割中可用于上采样。nn.Upsample:上采样层,操作效果和池化相反。可以通过mode参数控制上采样策略 为”nearest”最邻近策略或”linear”线性插值策略。nn.Unfold:滑动窗口提取层。其参数和卷积操作nn.Conv2d相同。实际上,卷积操作可以等价于nn.Unfold和nn.Linear以及nn.Fold的一个组合。 其中nn.Unfold操作可以从输入中提取各个滑动窗口的数值矩阵,并将其压平成一维。利用nn.Linear将nn.Unfold的输出和卷积核做乘法后,再使用nn.Fold操作将结果转换成输出图片形状。nn.Fold:逆滑动窗口提取层。
注意:
- 卷积核个数==输出的feature map(activation
map)个数,比如输入是一个\(32x32x3\)的图像,\(3\)表示RGB三通道,每个
filter/kernel是\(5x5x3\),一个卷积核产生一个\(feature map\),下图中,有\(6\)个 \(5x5x3\)的卷积核,故输出\(6\)个feature map(activation map),大小为\(28x28x6\)。
- 参数个数为:卷积核个数*(卷积核大小)+卷积核个数(偏置数)
- 偏置数==卷积核个数
6.4.3 循环网络相关层
nn.Embedding:嵌入层。一种比Onehot更加有效的对离散特征进行编码的方法。一般用于将输入中的单词映射为稠密向量。嵌入层的参数需要学习。nn.LSTM:长短记忆循环网络层【支持多层】。最普遍使用的循环网络层。具有携带轨道,遗忘门,更新门,输出门。可以较为有效地缓解梯度消失问题,从而能够适用长期依赖问题。设置bidirectional = True时可以得到双向LSTM。需要注意的时,默认的输入和输出形状是(seq,batch,feature), 如果需要将batch维度放在第0维,则要设置batch_first参数设置为True。nn.GRU:门控循环网络层【支持多层】。LSTM的低配版,不具有携带轨道,参数数量少于 LSTM,训练速度更快。nn.RNN:简单循环网络层【支持多层】。容易存在梯度消失,不能够适用长期依赖问题。 一般较少使用。nn.LSTMCell:长短记忆循环网络单元。和nn.LSTM在整个序列上迭代相比,它仅在序列上迭代一步。一般较少使用。nn.GRUCell:门控循环网络单元。和nn.GRU在整个序列上迭代相比,它仅在序列上迭代一步。一般较少使用。nn.RNNCell:简单循环网络单元。和nn.RNN在整个序列上迭代相比,它仅在序列上迭代一步。一般较少使用。
6.4.4 Transformer相关层
Transformer网络结构是替代循环网络的一种结构,解决了循环网络难以并行,难以捕捉长期依赖的缺陷。它是目前NLP任务的主流模型的主要构成部分。Transformer网络结构由TransformerEncoder编码器和TransformerDecoder解码器组成。编码器和解码器的核心是MultiheadAttention多头注意力层。
nn.TransformerEncoder:Transformer编码器结构。由多个nn.TransformerEncoderLayer编 码器层组成。nn.TransformerDecoder:Transformer解码器结构。由多个nn.TransformerDecoderLayer解码器层组成。nn.TransformerEncoderLayer:Transformer的编码器层。nn.TransformerDecoderLayer:Transformer的解码器层。nn.MultiheadAttention:多头注意力层。
6.4.5 自定义模型层
如果Pytorch的内置模型层不能够满足需求,我们也可以通过继承nn.Module基类构建自定义的模型层。实际上,pytorch不区分模型和模型层,都是通过继承nn.Module进行构建。
因此,我们只要继承nn.Module基类并实现forward方法即可自定义模型层。
下面是Pytorch的nn.Linear层的源码,我们可以仿照它来自定义模型层

