1. Numpy概述
1.1 概念
Python本身含有列表和数组,但对于大数据来说,这些结构是有很多不足的。由于列表的元素可以是任何对象,因此列表中所保存的是对象的指针。对于数值运算来说这种
结构比较浪费内存和CPU资源。至于数组对象,它可以直接保存
数值,和C语言的一维数组比较类似。但是由于它不支持多维,在上面的函数也不多,因此也不适合做数值运算。Numpy提供了两种基本的对象:ndarray(N-dimensional Array Object)和
ufunc(Universal Function Object)。ndarray是存储单一数据类型的多维数组,而ufunc则是能够对数组进行处理的函数。
1.2 功能
- 创建n维数组(矩阵)
- 对数组进行函数运算,使用函数计算十分快速,节省了大量的时间,且不需要编写循环,十分方便
- 数值积分、线性代数运算、傅里叶变换
- ndarray快速节省空间的多维数组,提供数组化的算术运算和高级的 广播功能
1.3 对象
- NumPy中的核心对象是
ndarray ndarray可以看成数组,存放 同类元素- NumPy里面所有的函数都是围绕ndarray展开的
ndarray 内部由以下内容组成:
- 一个指向数据(内存或内存映射文件中的一块数据)的指针。
- 数据类型或 dtype,描述在数组中的固定大小值的格子。
- 一个表示数组形状(shape)的元组,表示各维度大小的元组。形状为(row×col)
1.4 数据类型
numpy 支持的数据类型比 Python
内置的类型要多很多,基本上可以和C语言的数据类型对应上。主要包括int8、int16、int32、int64、uint8、uint16、uint32、uint64、float16、float32、float64
1.5 数组属性
| 属性 | 说明 |
|---|---|
ndarray.ndim |
秩,即轴的数量或维度的数量 |
ndarray.shape |
数组的维度(n×m),对于矩阵,n 行 m 列 |
ndarray.size |
数组元素的总个数,相当于 .shape 中 n*m 的值 |
ndarray.dtype |
ndarray 对象的元素类型 |
ndarray.itemsize |
ndarray 对象中每个元素的大小,以字节为单位 |
ndarray.flags |
ndarray对象的内存信息 |
ndarray.real |
ndarray元素的实部 |
ndarray.imag |
ndarray元素的虚部 |
ndarray.data |
包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性。 |
2. 具体操作
2.1 Numpy的创建
2.1.1 利用列表生成数组
1 | import numpy as np |
2.1.2 利用random模块生成数组
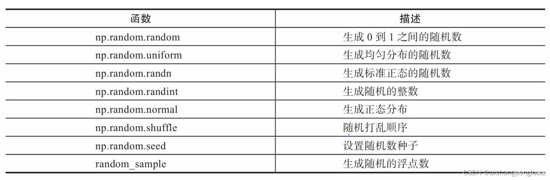
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19import numpy as np
#0到1标准正态分布
arr1 = np.random.randn(3, 3)
#0到1均匀分布
arr2 = np.random.rand(3, 3)
#均匀分布的随机数(浮点数),前两个参数表示随机数的范围,第三个表示生成随机数的个数
arr3 = np.random.uniform(0, 10, 2)
#均匀分布的随机数(整数),前两个参数表示随机数的范围,第三个表示生成随机数的个数
arr4 = np.random.randint(0, 10, 3)
print(f'arr1 : {arr1}\narr2 : {arr2}\narr3 : {arr3}\narr4 : {arr4}')
out :
# arr1 : [[-0.31637952 -0.08258995 1.43866984]
# [-0.11216775 0.43881134 0.11745847]
# [-1.1770306 -0.97657465 2.2368878 ]]
# arr2 : [[0.16350611 0.4467384 0.9465067 ]
# [0.1882318 0.40261184 0.93577701]
# [0.56243911 0.69179631 0.83407725]]
# arr3 : [4.41402883 6.03259052]
# arr4 : [9 7 7]
2.1.3 创建特定形状数组
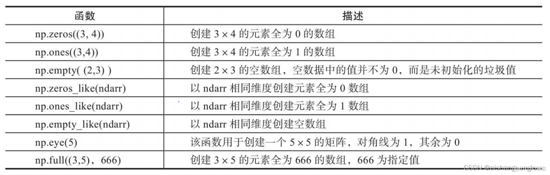
1
2
3
4
5
6
7
8
9
10
11
12
13
14mport numpy as np
#未初始化的数组
arr1 = np.empty((2,3))
#数组元素以 0 来填充
arr2 = np.zeros((2, 3))
#数组元素以 1 来填充
arr3 = np.ones((2, 3))
#数组以指定的数来进行填充,这里举例3
arr4 = np.full((2, 3), 3)
#生成单位,对角线上元素为 1,其他为0
arr5 = np.eye(2)
#二维矩阵输出矩阵对角线的元素,一维矩阵形成一个以一维数组为对角线元素的矩阵
arr6 = np.diag(np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]))
2.1.4 linspace
此函数类似于arange()函数。在此函数中,指定了范围之间的均匀间隔数量,而不是步长。用法如下
1
numpy.linspace(start, stop, num, endpoint, retstep, dtype)
start 序列的起始值 - stop
序列的终止值,如果endpoint为true,该值包含于序列中 - num
要生成的等间隔样例数量,默认为50 - endpoint
序列中是否包含stop值,默认为ture - retstep
如果为true,返回样例,以及连续数字之间的步长 - dtype
输出ndarray的数据类型
2.2 查找和搜索
Numpy可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样,设置start, stop 及 step 参数
2.2.1 切片操作
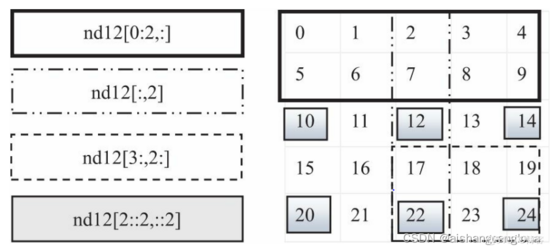
2.2.2 元素查找定位
Numpy库中提供了where函数来查找满足条件元素的索引,表示如下:
np.where(condition, x, y): 满足条件(condition),输出x,不满足输出ynp.where(condition): 输出满足条件 (即非0) 元素的坐标
1 | a=np.array([2,4,6,8,10,12]).reshape(2,3) |
输出: 1
[6 8 10 12]
2.2.3 高级索引
如果一个ndarray是非元组序列,数据类型为整数或布尔值的ndarray,或者至少一个元素为序列对象的元组,我们就能够用它来索引ndarray。高级索引始终返回数据的副本。使用方法
1
2
3
4
5
6
import numpy as np
x = np.array([[1, 2], [3, 4], [5, 6]])
y = x[[0,1,2], [0,1,0]]
print y1
[1,4,5]
(0,0),(1,1),(2,0)位置,得到`x[0,0],x[1,1],x[2,0]等就是输出结果
2.3 删除
np.delete(arr, index, axis=None)
- 第一个参数:要处理的矩阵,
- 第二个参数,处理的位置,下标
- 第三个参数,0表示按照行删除,1表示按照列删除,默认为0
- 返回值为删除后的剩余元素构成的矩阵
1 | m=np.delete(a,[0],0) |
2.4 numpy的拼接和分割
2.4.1 拼接
下面的图列举了常见的用于数组或向量 合并的方法。
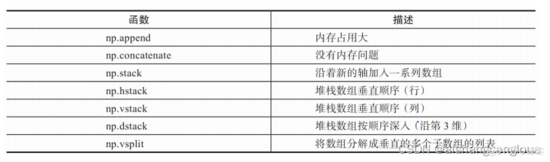
append、concatenate以及stack都有一个axis参数,用于控制数组的合 并方式是按行还是按列。- 对于
append和concatenate,待合并的数组必须有相同的行数或列数 stack、hstack、dstack,要求待合并的数组必须具有相同的形状
2.4.2 分割
- 水平分割:
np.split(arr,n,axis=1) 或 np.hsplit(arr,n):按列分成n份。返回一个list - 垂直分割:
np.split(arr,n,axis=0)或np.vsplit(arr,n):按行分成n份,返回一个list
1 | splitTes=np.split(a,2,0) |
2.5 维度变换
在机器学习以及深度学习的任务中,通常需要将处理好的数据以模型能
接收的格式输入给模型,然后由模型通过一系列的运算,最终返回一个处理
结果。然而,由于不同模型所接收的输入格式不一样,往往需要先对其进行
一系列的变形和运算,从而将数据处理成符合模型要求的格式。在矩阵或者
数组的运算中,经常会遇到需要把多个向量或矩阵按某轴方向合并,或展平
(如在卷积或循环神经网络中,在全连接层之前,需要把矩阵展平)的情
况。下面介绍几种常用的数据变形方法。

2.5.1 reshape
不会改变数组内额元素,返回一个指定的shap维度的数组,按原顺序放置元素
1
2#三行四列,如果单指定行数或列数,另一个参数可设置为-1
x=np.arange(12).reshape(3,4)
2.5.2 resize
改变向量的维度,同reshape作用 1
2
3#二行五列
arr=np.arange(10)
arr.resize(2,5)
2.5.3 转置
将矩阵转置 1
2arr=np.nrange(12).reshape(3,4)
print(arr.T)
2.5.4 向量展平
将多维数组转为一维数组,不会产生数组的副本 1
arr=arr.ravel()
2.5.5 向量展平之flatten
把矩阵转换为向量,这种需求经常出现在卷积网络与全连接层之间
1
2arr = np.arange(8).reshape(2, 4)
arr.flatten() # out : array([0, 1, 2, 3, 4, 5, 6, 7])
2.5.6 squeeze
这是一个降维的函数,把矩阵中为1维的维度去掉 1
2
3arr = np.arange(8).reshape(2, 4, 1)
arr.shape # out : (2, 4, 1)
arr.squeeze().shape # out : (2, 4)
2.5.7 transpose
对高维矩阵进行轴对换,这个在深度学习中经常使用,比如把图片中表
示颜色顺序的RGB改为GBR。 1
2
3arr = np.arange(12).reshape(2, 6, 1)
arr.shape # out : (2, 6, 1)
arr.transpose(1, 2, 0).shape # out : (6, 1, 2)
2.6 矩阵运算
2.6.1 对于元素相乘
对应元素相乘(Element-Wise Product)是两个矩阵中对应元素乘积。
np.multiply函数用于数组或矩阵对应元素相乘,输出与相乘数组或矩阵的大
小一致。 1
2
3a = np.array([[1,0],[0,1]])
b = np.array([[4,1],[2,2]])
np.multiply(a, b) # 等效于a * b,out : array([[4, 0], [0, 2]])
2.6.2 点积
点积运算(Dot Product)又称为内积,在Numpy用np.dot或者np.matmul表示
1
2
3a = np.array([[1,0],[0,1]])
b = np.array([[4,1],[2,2]])
np.dot(a, b) # 等效于np.matmul(a, b) out : array([[4, 1], [2, 2]])
2.6.3 行列式
计算行列式的值 1
2arr = np.array([[1,2], [3,4]])
np.linalg.det(arr) # out : -2.0000000000000004
2.6.4 求逆
求逆 1
2arr = np.array([[1,2], [3,4]])
np.linalg.inv(arr) # out : array([[-2. , 1. ], [ 1.5, -0.5]])
2.6.5 特征值和特征向量
1 | A = np.random.randint(-10,10,(4,4)) |
2.7 numpy- Matplotlib
Matplotlib 是 Python 的绘图库。 它可与 NumPy
一起使用,提供了一种有效的 MatLab 开源替代方案。
它也可以和图形工具包一起使用,如 PyQt 和 wxPython。 1
from matplotlib import pyplot as plt
pyplot()是
matplotlib库中最重要的函数,用于绘制 2D 数据。
以下脚本绘制方程y = 2x + 5:
1 | import numpy as np |
3.pandas概述
Pandas是Python的一个大数据处理模块。Pandas使用一个二维的数据结构DataFrame来表示表格式的数据,相比较于Numpy,Pandas可以存储混合的数据结构,同时使用NaN来表示缺失的数据,而不用像Numpy一样要手工处理缺失的数据,并且Pandas使用轴标签来表示行和列。它具有:
- 便捷的数据处理能力
- 独特的数据结构
- 读取文件方便
- 封装了
matplotlib的画图和numpy的计算
3.1 pandas的数据结构
Pandas有三种主要数据结构Series、DataFrame、Panel。
Series是带有标签的一维数组,可以保存任何数据类型(整数,字符串,浮点数,Python对象等),轴标签统称为索引(index)。DataFrame是带有标签的二维数据结构,具有index(行标签)和columns(列标签)。如果传递index或columns,则会用于生成的DataFrame的index或columns。Panel是一个三维数据结构,由items、major_axis、minor_axis定义。items(条目),即轴0,每个条目对应一个DataFrame;major_axis(主轴),即轴1,是每个DataFrame的index(行);minor_axis(副轴),即轴2,是每个DataFrame的columns(列)。
3.2 Series
Series是能够保存任何类型数据(整数,字符串,浮点数,Python对象等)的一维标记数组,轴标签统称为index(索引)。series是一种一维数据结构,每一个元素都带有一个索引,其中索引可以为数字或字符串。Series结构名称:
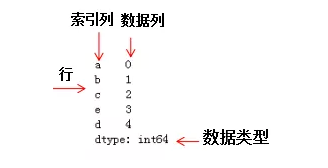
3.2.1 构造对象
Series的构造函数如下: 1
pandas.Series( data, index, dtype, copy)
data:构建Series的数据,可以是ndarray,list,dict,constants。
- index:索引值必须是唯一的和散列的,与数据的长度相同。
如果没有索引被传递,默认为np.arange(n)。 -
dtype:数据类型,如果没有,将推断数据类型。 -
copy:是否复制数据,默认为false。
1 | import pandas as pd |
使用ndarray作为数据时,传递的索引必须与ndarray具有相同的长度。
如果没有传递索引值,那么默认的索引是range(n),其中n是数组长度,即[0,1,2,3…. range(len(array))-1] - 1]。
3.2.2 Series数据的访问
Series中的数据可以使用有序序列的方式进行访问。 1
2
3
4
5
6
7
8
9
10
11
12
13
14import pandas as pd
if __name__ == "__main__":
s = pd.Series([1, 2, 3, 4, 5], index=['a', 'b', 'c', 'd', 'e'])
print(s[0])
print(s[-1])
print(s[-3:])
# output:
# 1
# 5
# c 3
# d 4
# e 5
# dtype: int64
3.2.3 Series属性
Series.axes:返回行轴标签列表Series.dtype:返回对象的数据类型Series.empty:如果对象为空,返回TrueSeries.ndim:返回底层数据的维数,默认为1Series.size:返回基础数据中的元素数Series.values:将对象作为ndarray返回Series.head():返回前n行Series.tail():返回后n行
1 | import pandas as pd |
3.3 DataFrame
数据帧(DataFrame)是二维的表格型数据结构,即数据以行和列的表格方式排列,DataFrame是Series的容器。
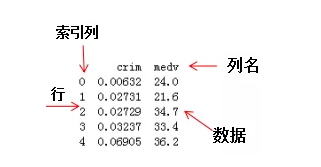 特点:
特点:
- 底层数据列是不同的类型
- 大小可变
- 标记轴(行和列)
- 可以对行和列执行算术运算
3.3.1 DataFrame对象构造
1 | pandas.DataFrame( data, index, columns, dtype, copy) |
data:构建DataFrame的数据,可以是ndarray,series,map,lists,dict,constant和其它DataFrame。index:行索引标签,如果没有传递索引值,索引默认为np.arrange(n)。columns:列索引标签,如果没有传递索列引值,默认列索引是np.arange(n)。dtype:每列的数据类型。copy:如果默认值为False,则此命令(或任何它)用于复制数据。
1 | import pandas as pd |
3.3.2 DataFrame属性
DataFrame.T:转置行和列DataFrame.axes:返回一个列,行轴标签和列轴标签作为唯一的成员。DataFrame.dtypes:返回对象的数据类型DataFrame.empty:如果NDFrame完全为空,返回TrueDataFrame.ndim:返回轴/数组维度的大小DataFrame.shape:返回表示DataFrame维度的元组DataFrame.size:返回DataFrame的元素数DataFrame.values:将对象作为ndarray返回DataFrame.head():返回前n行DataFrame.tail():返回后n行
3.3.3 示例
1 | # 导入库 |
3.4 panel
panel 是三维的数据结构,是DataFrame的容器,Panel的3个轴如下:
items:axis 0,每个项目对应于内部包含的数据帧(DataFrame)。major_axis:axis 1,是每个数据帧(DataFrame)的索引(行)。minor_axis:axis 2,是每个数据帧(DataFrame)的列。
3.4.1 Panel对象构造
1 | pandas.Panel(data, items, major_axis, minor_axis, dtype, copy) |
data:构建Panel的数据,采取各种形式,如ndarray,series,map,lists,dict,constant和另一个数据帧DataFrame。items:axis=0major_axis:axis=1minor_axis:axis=2dtype:每列的数据类型copy:复制数据,默认 - false
1 | import pandas as pd |
3.4.2 Panel数据索引
Panel右三个数据索引,因此可使用它们获取相应的结果,这里使用Items访问Panel可以获取相应的DataFrame
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21import pandas as pd
import numpy as np
if __name__ == "__main__":
data = {'Table1': pd.DataFrame(np.random.randn(4, 3),
index=['rank1', 'rank2', 'rank3', 'rank4'],
columns=['Name', 'Age', 'Score']),
'Table2': pd.DataFrame(np.random.randn(4, 3),
index=['rank1', 'rank2', 'rank3', 'rank4'],
columns=['Name', 'Age', 'Score']
)
}
p = pd.Panel(data)
print(p['Table1'])
# output:
# Name Age Score
# rank1 -1.240644 -0.820041 1.656150
# rank2 1.830655 -0.258068 -0.728560
# rank3 1.268695 1.259693 -1.005151
# rank4 -0.139876 0.611589 2.343394
3.4.3 Panel属性
Panel.T:转置行和列Panel.axes:返回一个列,行轴标签和列轴标签作为唯一的成员。Panel.dtypes:返回对象的数据类型Panel.empty:如果NDFrame完全为空,返回TruePanel.ndim:返回轴/数组维度的大小Panel.shape:返回表示DataFrame维度的元组Panel.size:返回DataFrame的元素数Panel.values:将对象作为ndarray返回

