0. 刷题规划
读者在看到这篇文章的时候不应该以本文的讲解顺序进行刷题。正常来说,按模块刷题是最好的,我的刷题是按照数组->链表->树->dp的循环进行,然后对各模块的方法进行总结,比如遇到 - 数组一类的,其可使用的方法最多:二分查找、快慢指针、双指针、滑动窗口、前缀和数组、差分数组等。 - 遇到链表,那么快慢指针是最多的。 - 遇到树,那么递归(广度or深度)是最常用的形式、非递归遍历也要顺序,记住对称性解题方式。 - 遇到动态规划,先分类其是属于哪种形式的dp(线性dp、区间dp、背包dp和状压dp),然后确定dp含义,分析状态转移方程。 - 其他方法,比如**单调栈、单调队列的实现、拓扑排序、归并排序、KMP算法、分治、广度*等算法就就需要在刷题中不断掌握
注意:在解题中一定不要忽略暴力解,许多奇妙的解法就是从暴力解的思路上想出来的,一旦遇到一道不会优解的题,可以先想一想暴力解的思路,有什么地方可以优化暴力解,来达到降低时间复杂度的效果
1. 动态规划类
动态规划的思想就是:如果一个问题能够由子问题一步步递推得来,即当前子问题的解将由上一次子问题的解推出,利用这种特性,使用一个数据结构dp来存储上一次子问题的结果,避免重复计算。
所以动态规划最重要的有三点:
- 确定dp的含义
- 确定dp的初始状态
- 确定dp间的状态转移方程
知道上述三点,问题也就迎刃而解。在算法当中,常见的dp类型有线性dp、区间dp、背包dp和状压dp。下面将对这几个进行讲解。
总结:对于是否使用DP,那么就得看你能不能确定dp数组的含义,以及能够确定状态转移方程。
tips:做了比较多的题,通常许多的字符串dp类型的题目是区间dp,像回文串、编辑距离等待,二数组类型的dp,较多的是线性dp、多状态dp(状压dp)和背包dp类型
1.1 线性DP
打家劫舍
问题:你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
1 | /* |
打家劫舍Ⅱ
你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金。这个地方所有的房屋都 围成一圈 ,这意味着第一个房屋和最后一个房屋是紧挨着的。同时,相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警 。
给定一个代表每个房屋存放金额的非负整数数组,计算你 在不触动警报装置的情况下 ,今晚能够偷窃到的最高金额。
解题思路:与打家劫舍多了一个约束:这个地方所有的房屋都 围成一圈,第一个房屋和最后一个房屋是相连的,需要考虑这种情况
还是使用动态规划:dp[i]表示截至到i+1号房能够偷盗的最大金额,此时需要做两次不同的dp比较,
- 一个是选择
1号房屋,此时就不能选择最后一个房屋- 初始状态:
dp1[0]=nums[0],dp[1]=max(dp1[1],dp1[0]) - 状态转移:
dp1[i]=max(dp1[i-2]+nums[i],d1[i-1]) 1<i<n-1
- 初始状态:
- 另一个是不选择1号屋,此时对最后一个房屋没有要求
- 初始状态:
dp2[1]=nums[1],dp2[2]=max(dp2[1],dp2[2]); - 状态转移:
dp2[i]=max(dp2[i-2]+nums[i],dp2[i-1]) 2<i<n
- 初始状态:
- 最后
max(dp1[n-2],dp2[n-1])
上面的dp数组可省略,因为当前状态只与前两个有关
1 |
|
打家劫舍Ⅲ
小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为 root 。
除了 root 之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。
如果 两个直接相连的房子在同一天晚上被打劫 ,房屋将自动报警。
给定二叉树的 root 。返回 在不触动警报的情况下 ,小偷能够盗取的最高金额 。
解题思路:
使用动态规划+深度搜索:使用分解成子问题的方式来解决,因为一个节点只有选与不选两者可能,选会对其他节点产生影响,那么我们从自低向上的方式来解决,将一颗树分解成多个子树的求解过程,通过子树不断向整颗树递进进行求解,比如对于root,我们向求出其左右子树选与不选时的金额,我们用dp[2]记录,dp_r[0]表示不选择该右节点时右子树能得到的最大金额,dp_r[1]表示选择该右节点时右子树能得到的最大金额,同理dp_l[0]和dp_l[1],那么对于root,它的
dp_root[1]=dp_r[0]+dp_l[0]+root,dp_root[0]=max(dp_r[0],dp_l[1])+max(dp_l[0],dp_l[1]);
因此,解题步骤:
- 构建一个
rootdfs(left,right),返回vector<int> - 每一次递归都要构建
dp[2],dp[0]表示不选择改节点,dp[1]选择 - 初始条件
dp[]=0 - 状态转移条件:
dp[0]=max(dp_r[0],dp_l[1])+max(dp_l[0],dp_l[1]); dp[1]=dp_r[0]+dp_l[0]+root
1 | class Solution { |
最大子数组的和
给你一个整数数组 nums
,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
子数组 是数组中的一个连续部分。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37/*
*动态规划:dp[i][j],表示[i,j]范围的子数组和,我们只需记录出现的最大和即可maxValue
* - 初始条件时dp[i][i]=nums[i]
* - 状态转移条件时dp[i][j]=dp[i][j-1]+nums[j]
*时间复杂度为O(n*n),空间复杂度为O(n*n)
:超时:
*
*优化:空间复杂度为O(1),时间复杂度为为O(n*n):超时
*/
/*
*时间复杂度O(n)解法:dp
*从前往后遍历一下即可,要记录前面包含i-1连续子数组的和sum:
*- 若当前nums[i]>=0,sum>=0,则子数组和为sum+nums[i]
*- 若当前nums[i]>=0,当sum<0,则当前子数组和为nums[i]
*- 若当前nums[i]<0,当sum+nums[i]>=0时,可选择nums[i]继续作为连续子数组
*- 当nums[i]<0,当sum+nums[i]<0时,放弃nums[i],重新以i+1作为开始
- 上面分析总结为动态规划就是,dp[i],i表示以nums[i]为结尾的子数组和的最大值
- 初始条件dp[0]=nums[0]
- 状态转移dp[i]=max(dp[i-1]+nums[i],nums[i])
*/
class Solution {
public:
int maxSubArray(vector<int>& nums) {
int maxValue=nums[0];
vector<int>dp(nums.size(),0);
dp[0]=nums[0];
for(int i=1;i<nums.size();i++){
dp[i]=max(dp[i-1]+nums[i],nums[i]);
if(maxValue<dp[i])
maxValue=dp[i];
}
return maxValue;
}
};
剑指offer 丑数
我们把只包含质因子 2、3 和 5 的数称作丑数(Ugly Number)。求按从小到大的顺序的第 n 个丑数。 >质数:因子除了1和它本身外,无其他因子
思路:优化方法我们只需要考虑2的倍数、3的倍数和5的倍数即可
- 此时需要更改
dp[i]数组含义,dp[i]表示目前得到i+1个丑数是dp[i],这就要保证dp[i]是递增顺序的无重复的 - 初始条件
dp[0]=1 - 难点:为了得到状态转移方程,因为有三个乘积因子2,3,5,如果一股脑不加以判断的添加,会出现非递增存储和重复的结果。比如,从dp[0]于2、3、5相乘后会得到1、2、3、5,之后dp[1]得到1、2、3、5、4、6、10,再dp[2]得到1、2、3、5、4、6、10、6、9、15...明显存在重复和乱序以及重复计算
- 因此可以使用
a、b、c去记录分别要与2、3、5将要相乘的dp[j],能够很好的解决乱序和重复问题,初始时a=b=c=0 - 所以状态转移方程为:
dp[i]=min(min(dp[a]*2,dp[b]*3),dp[c]*5),然后于dp[i]相等的索引即a、b、c进行++ - 直到
dp.size()==n,然后对dp排序去最后一个元素得到第n个丑数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50/*
*动态规划:dp[i]记录数字i是否为丑数,是则为true,
*初始dp[0]=false,dp[1]=true
*状态转移方程dp[i]=dp[i/2]||dp[i/3]||dp[i/5],其中i/2、i/3和i/5必须为整数
*会超时
*优化:我们只需要考虑2的倍数、3的倍数和5的倍数即可
*此时需要更改dp[i]数组含义,dp[i]表示目前得到i+1个丑数是dp[i]
*- 初始条件dp[0]=1
*- 难点:为了得到状态转移方程,因为有三个乘积因子2,3,5,如果一股脑不加以判断的添加,会出现非递增存储和重复的结果。比如,从dp[0]于2、3、5相乘后会得到1、2、3、5,之后dp[1]得到1、2、3、5、4、6、10,再dp[2]得到1、2、3、5、4、6、10、6、9、15...明显存在重复和乱序以及重复计算
*- 因此可以使用a、b、c去记录分别要与2、3、5将要相乘的dp[j],初始时a=b=c=0
*- 所以状态转移方程为:dp[i]=min(min(dp[a]*2,dp[b]*3),dp[c]*5),然后于dp[i]相等的索引即a、b、c进行++
*直到dp.size()==n,然后对dp排序去最后一个元素得到第n个丑数
*/
class Solution {
public:
/*超时规划
int nthUglyNumber(int n) {
vector<bool> dp;
dp.push_back(false);//dp[0]
dp.push_back(true);//dp[1]
n--;
for(int i=2;n>0;++i)
{
if((i%2==0&&dp[i/2])||(i%3==0&&dp[i/3])||(i%5==0&&dp[i/5])){
dp.push_back(true);
--n;
continue;
}
dp.push_back(false);
}
return dp.size()-1;
}
*/
int nthUglyNumber(int n)
{
vector<int>dp(n,1);
int a=0,b=0,c=0;
for(int i=1;i<n;++i)
{
//得到顺序丑数
int n2=dp[a]*2,n3=dp[b]*3,n5=dp[c]*5;
dp[i]=min(min(n2,n3),n5);
//避免重复丑数
if(n2==dp[i]) ++a;
if(n3==dp[i]) ++b;
if(n5==dp[i]) ++c;
}
return dp[n-1];
}
};
n个骰子的点数
把n个骰子扔在地上,所有骰子朝上一面的点数之和为s。输入n,打印出s的所有可能的值出现的概率。
你需要用一个浮点数数组返回答案,其中第 i 个元素代表这 n 个骰子所能掷出的点数集合中第 i 小的那个的概率。
思路:
n(n>1)个骰子的点数与n-1个骰子的点数有着密切联系,假设f(n-1)是n个骰子的点数概率结果,和为x的概率为f(n-1,x),那么f(n,x)的概率结果是Σf(n-1,x-i)*1/6,其中i=1,...,6;且6(n-1)>=x-i>=(n-1)- 因为只与上一个结果有关,因此可以使用两个数组来完成,第一个是存储
n-1个骰子的概率结果,第二个依据n-1来构建
算法过程:
- 因此上面的思想是动态规划:使用
dp1[i],表示k-1个骰子的概率结果,dp[i]为k个骰子的概率结果 - 初始条件:
dp1[1]=dp1[2]=..=dp1[6]=1/6 - 状态转移方程
dp[j]=Σdp1[j-i]*1/6其中6(k-1)>j-i>=(k-1)和i=1,...,6 - 更新
dp1=dp,继续上述步骤,直到k>n
1 | class Solution { |
单词拆分
给你一个字符串s和一个字符串列表 wordDict
作为字典。请你判断是否可以利用字典中出现的单词拼接出 s 。
思路:
遍历s的字符串进行拼接,查看该子串是否在wordDict中,子串的状态会被上一个状态所影响,因此可采用动态规划的思想来解决(比如"catsandog"和["c","cats","an","dog"])
解题步骤:
- 动态规划+哈希:使用
dp[i]表示字符串从[1,i]是否可有wordDict构成,是则为true,否则为false - 初始状态:
dp[0]=true,表示空串,是能够表示的, - 状态转移方程:
dp[i+1]=dp[j]&&(s[j,i] in wordDict?),其中j取值满足i-j<=20(或者也可得到wordDict字符串的最大长度,以此达到剪枝的目的) - 其中从字典中查找
s[j,i]会消耗大多是时间,我们可将wordDict放在哈希上,使查找的时间复杂度为O(1) - 因此以上时间复杂度为
O(n*n),空间复杂度为O(n)
1 | class Solution { |
接雨水
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
题解思路:
暴力方法: 对每一个遍历得到的柱子,分别遍历得到其左右的柱子的最大值,可得当前位置可接雨水
min(height[l],height[h])-height[i],此时时间复杂度为O(n*n,不能接受动态规划类型: 上面暴力方法中,为了得到当前位置可接雨水数量,要遍历左右两边,存在大量的重复计算,可以使用两个数组
leftmax[i]和rightmax[i]来记录当前位置i左右两边的最高柱子高度,其中leftmax[max]在计算中更新,right[max]事前全部准备好,此时时间复杂度为O(n),空间复杂度为O(n)- 即
leftmax[i]和rightmax[i]来记录当前位置i左右两边的最高柱子高度 - 初始条件为
leftmax[0]=height[0],leftmax为倒叙遍历后的最大值情况 - 状态转移方程是leftmax[i]=max(height[i,leftmxa[i-1]]),根据比较记录
sum=min(leftmax[i],rightmax[i])-height[i]
- 即
双指针类型: 上面的动态规划由于要存储左右最大值使得空间复杂度为
O(n),进一步分析可知可使用双指针,其中l为左指针,h为右指针,我们发现存水多少取决于左右最大值较小的那一个,那么无论最大那个多大,都不是它决定,而是较小的决定。- 所有我们定义
leftmax,rightmax,来记录左右指针目前走过区域的最大值,其中l只会向右走,h只会向左走 - 更新策略是用
height[l],height[h]更新leftmax、rightmax - 当
height[l]>height[h]时,可以肯定lefmax>rightmax,因此可接雨水是rightmax-height[h],此时--h; - 当
height[l]<=height[h]时,可以肯定lefmax<=rightmax,因此可接雨水是leftmax-height[l],此时++l; -当l>h时退出,累计的雨水即为所求
- 所有我们定义
1 | lass Solution { |
最佳买股票时机含冷冻期
给定一个整数数组prices,其中第 prices[i] 表示第 i 天的股票价格
。
设计一个算法计算出最大利润。在满足以下约束条件下,你可以尽可能地完成更多的交易(多次买卖一支股票):
- 卖出股票后,你无法在第二天买入股票 (即冷冻期为 1 天)。
- 注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)
解题思路:
因为多了个冷冻期的约束,这表示对于卖出股票后,后续能否买入,要看是否处于冷冻期
动态规划:使用二维dp解决,dp[i][j]中,其中第一维度表示到第i天能够得到最大利润,p[i][0]表示目前没持有股票且不处于冷冻期的最大利润;p[i][1]表示未持有股票且处于冷冻期,这表示在第i天卖出;dp[i][2]表示持有一个股票时的最大利润
- 初始条件:
dp[0][0]=0,dp[0][1]=0,dp[0][2]=-prices[0] - 状态转移方程:
dp[i][0]=max(dp[i-1][0],dp[i-1][1]);dp[i][1]=dp[i-1][2]+prices[i];dp[i][2]=max(dp[i-1][2],dp[i-1][0]-prices[i])
总结:像这样对于中间状态有多个不同的情况,在运用动态规划的时候,单个维度dp无法表示,通常可以扩展到二维,定义二维度含义表示(比如打家劫舍Ⅲ也是一样的道理)
1 | class Solution { |
最长递增序列
给你一个整数数组nums
,找到其中最长严格递增子序列的长度。
子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7]
是数组 [0,3,1,6,2,2,7]的子序列。
解题思路:利用动态规划的思想一步步求解并优化
方法一:
dp[i]数组存储表示以nums[i]结尾的最长递增子序列,那么对于该dp有
- 初始状态:
dp[0]=1 - 状态转移:以当前位置逆序方式进行查找,直到找到第一个
nums[j]<nums[i],那么dp[i]=1+dp[j],没找到则dp[i]=1
上面的方法一的时间复杂度为O(n*n),原因是对于当前的nums[i],我们都必须逆序在[0,i-1]去寻找第一个满足nums[j]<nums[i]的元素。
方法二:
基于上面的思想,为了优化时间复杂度,能否对逆序寻找进行优化呢,使复杂度降为O(N)或者O(nlogn),O(n)算法就必须使得查找为O(1),这是比较难办到的。而对于O(nlogn)来说,是较容易,想优化到logn复杂度,那么不是二分就是归并了,这里我们重定义dp数组的意义,使得寻找遍历能够使用二分法。
由于题意只要求返回最大长度,因为我们只需一个maxL来记录当前遍历到nums[i]时的最大长度,我们用dp[]来有序记录当前的最长子序列数组,对于得到的nums[i],器更新策略如下:
- 对
nums[i]先确定其插入位置,使用二分方法,初始lo=0,hi=maxL, - 经过二分后确定插入位置为更新后的
lo,另dp[lo]=nums[i] - 判断
lo==maxL?,若是则说明当前的nums[i]在此时的递增子序列的末尾,则++maxL
时间复杂度为O(nlogn)
1 | class Solution { |
粉刷房子
假如有一排房子,共 n 个,每个房子可以被粉刷成红色、蓝色或者绿色这三种颜色中的一种,你需要粉刷所有的房子并且使其相邻的两个房子颜色不能相同。
当然,因为市场上不同颜色油漆的价格不同,所以房子粉刷成不同颜色的花费成本也是不同的。每个房子粉刷成不同颜色的花费是以一个 n x 3 的正整数矩阵costs
来表示的。
例如,costs[0][0] 表示第 0
号房子粉刷成红色的成本花费;costs[1][2] 表示第 1
号房子粉刷成绿色的花费,以此类推。
请计算出粉刷完所有房子最少的花费成本。
解题思路:
由于粉刷房子只有三种颜色可选择,却要求相邻房子不能相同,要求满足上面条件的最小花费,这是一个多中间值的dp问题,因此可以使用二维动态规划
使用动态规划:dp[i][j],其中i为[0:n-1]表示第i栋方正,j为[0:2]表示颜色,0为红色,1为蓝色,2为绿色,dp[i][j]即表示满足相邻方正不同色情况下,到[0:i]栋房子的粉刷策略的最低消费,最后一个房子以j颜色结尾。所以:
- 初始状态:
dp[0][0]=costs[0][0],dp[0][1]=costs[0][1],dp[0][2]=costs[0][2] - 状态转移方程:
dp[i][0]=costs[i][0]+min(dp[i-1][1],dp[i-1][2]);``dp[i][1]=costs[i][1]+min(dp[i-1][0],dp[i-1][2]);``dp[i][2]=costs[i][2]+min(dp[i-1][1],dp[i-1][0])
时间复杂度为O(n),空间复杂度为O(n),由于只与上一个状态有关,因此空间复杂度可优化至O(1)
1 | class Solution { |
1.2 区间DP
最长回文子串
问题:给你一个字符串s,找到s中最长的回文子串。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37string longestPalindrome(string s) {
//dp[i][j]:表示s[i]是否等于s[j],相等且回文则置为true,否则为false
//初始条件:dp[i][i]=true;
//状态转移方程:
//①若i和j是相邻的即i+1=j且s[i]==s[j],则dp[i][j]=true
//②若不相邻,则判断内侧是否为true,若dp[i+1][j-1]=true&&s[i]==s[j],则dp[i][j]=true
//通过增加两变量记录当前回文串的最长长度Maxlen,初始为1,以及记录回文串的下标开始index_min,初始为最后一个元素
//算法的时间复杂度为O(n*n)
int len=s.size();
if(len==0||len==1)
return s;
vector<vector<bool>> dp(len,vector<bool>(len,false));
for(int i=0;i<len;i++)
dp[i][i]=true;
int Maxlen=1,index_min=len-1;
for(int i=len-2;i>=0;i--)
{
for(int j=i+1;j<len;j++)
{
if(s[i]==s[j])//如果两元素相等
{
if(j==i+1)//如果相邻
dp[i][j]=true;
else //不相邻,判断两元素内部是否为回文串
if(dp[i+1][j-1])
dp[i][j]=true;
if(dp[i][j]&&Maxlen<j-i+1)//更新Maxlen和index_min
{
Maxlen=j-i+1;
index_min=i;
}
}
}
}
string ret=s.substr(index_min,Maxlen);
return ret;
}
最长回文子序列
给你一个字符串 s ,找出其中最长的回文子序列,并返回该序列的长度。
子序列定义为:不改变剩余字符顺序的情况下,删除某些字符或者不删除任何字符形成的一个序列。
1 | class Solution { |
最长公共子序列
给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
例如,"ace" 是 "abcde"
的子序列,但"aec" 不是 "abcde"的子序列。
两个字符串的 公共子序列 是这两个字符串所共同拥有的子序列。
解法一:
暴力解:以text1的text1[i]作为开头,得到以它开头的最长公共子序列,最后得到最长序列,时间复杂度为O(nmm)
解法二: 暴力解的时间复杂度较高,其原因是进行了一些不必要的比较,使用动态规划来优化。该题可以由子问题一步一步构建而来。
最长公共子序列是典型的二维dp例题,需要记住这个思想:
- 给出
dp[i][j],其中行数为1+text1.size(),列数为1+text2.size() - 那么定义
dp[i][j]其表示text1[0:i-1]和text2[0:j-1]的最长公共子序列,那么对于更新,则有 - 初始状态
dp[0][0:m]=0,dp[0:n][0]=0 - 状态转移方程:
- 当
text1[i-1]==text2[j-1],那么此时dp[i][j]=1+dp[i-1][j-1](写对角线) - 当
text1[i-1]!=text2[j-1],对于dp[i][j]的取值分析,我们需要考虑text1[0:i-2]和text2[0:j-1]的最长公共子序列(上)text1[0:i-1]和text2[0:j-2]的最长公共子序列(左)
- 由于之前已经计算过两者,因此
dp[i][j]取它们两者较大者即可,即dp[i][j]=max(dp[i][j-1],dp[i-1][j])
- 当
1 | class Solution { |
该题与编辑距离有共同相似处。
编辑距离
给你两个单词
word1和word2, 请返回将word1转换成word2所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
思路
借鉴于官方题解,更加清晰得描述解题思路: 使用动态规划来解决,尝试使用由前一个子问题推导得到下一个子问题的答案,最终回到最终解。
分析:
当我们直到word1的前i-1和j-1字符的最小编辑距离,如何利用它们得到前i和j字符的最小编辑记录。
假如用A=horse和B=ros作为例子,我们因为有三种操作,因此也就得比较三种操作得到最小值:
在单词
A中插入一个字符:如果我们知道horse到ro的编辑距离为a(即horse经过a步就能变为ro,dp[i][j-1]=a),那么显然horse到ros的编辑距离不会超过a + 1。这是因为经过dp[i][j-1]后,在单词A的末尾添加字符s,就能在a + 1次操作后将horse和ros变为相同的字符串;在单词 A中删除一个字符:如果我们知道
hors到ros的编辑距离为b,即dp[i-1][j]=b,那么显然horse到ros的编辑距离不会超过b + 1,原因是只需要多删除一个e即可;在A中替换一个单词,如果我们知道
hors到ro的编辑距离为c,那么显然horse到ros的编辑距离不会超过c + 1,原因是因为A中加入了e,而B中加入了s,因此在e替换为s时,需要额外加1个操作上,如果相等,那么dp[i][j]=dp[i-1][j-1]
因此基于上述分析: -
当A[i]==B[i]时,dp[i][j]=min(dp[i][j-1]+1,dp[i-1][j]+1,dp[i-1][j-1])
-
当A[i]!=B[i]时,dp[i][j]=min(dp[i][j-1],dp[i-1][j],dp[i-1][j-1])+1
步骤
- 定义
dp[i][j],表示word1的前i个字符与word2的前j个字符的最小编辑距离。 - 初始化
dp[0][i]=i,dp[i][0]=i,当另一个字符串为空时,最小编辑距离当然时另一个字符串得长度 - 状态转移方程:
- 当
A[i]==B[i]时,dp[i][j]=min(dp[i][j-1]+1,dp[i-1][j]+1,dp[i-1][j-1]) - 当
A[i]!=B[i]时,dp[i][j]=min(dp[i][j-1],dp[i-1][j],dp[i-1][j-1])+1
- 当
1 | class Solution { |
交错字符串
给定三个字符串 s1、s2、s3,请你帮忙验证 s3
是否是由 s1 和 s2交错 组成的。
两个字符串s 和 t交错
的定义与过程如下,其中每个字符串都会被分割成若干 非空 子字符串:
s = s1 + s2 + ... + snt = t1 + t2 + ... + tm|n - m| <= 1- 交错 是
s1 + t1 + s2 + t2 + s3 + t3 + ...或者t1 + s1 + t2 + s2 + t3 + s3 + ...
分析
分析该题可知,当前s3的前i+j个元素能否由s1和s2说交错组成,由s3的前i+j-1个元素能否由s1和s2交错组成所决定,因此该题可以用动态规划来解决。我们用dp[i][j],表示s3的前i+j个元素是否能被s1的前i个元素和s2的前j个元素交错组成,可组成则为true,否则为false,那么分析就有:
- 初始状态:
dp[0][0] = true - 状态转移方程:
dp[i][j] = (dp[i-1][j]&&s1[i-1]==s3[i+j-1])||(dp[i][j-1]&&s2[j-1]==s3[i+j-1])
1 | class Solution { |
1.3 背包DP
1.4 状压DP
1.5 剑指offer62 圆圈中最后剩余的数字
1、约瑟夫问题: 这个问题实际上是约瑟夫问题,这个问题描述是 >N个人围成一圈,第一个人从1开始报数,报M的将被杀掉,下一个人接着从1开始报。如此反复,最后剩下一个,求最后的胜利者。
2、问题转化 既然约塞夫问题就是用人来举例的,那我们也给每个人一个编号(索引值),每个人用字母代替
下面这个例子是N=8 m=3的例子
我们定义F(n,m)表示最后剩下那个人的索引号,因此我们只关系最后剩下来这个人的索引号的变化情况即可
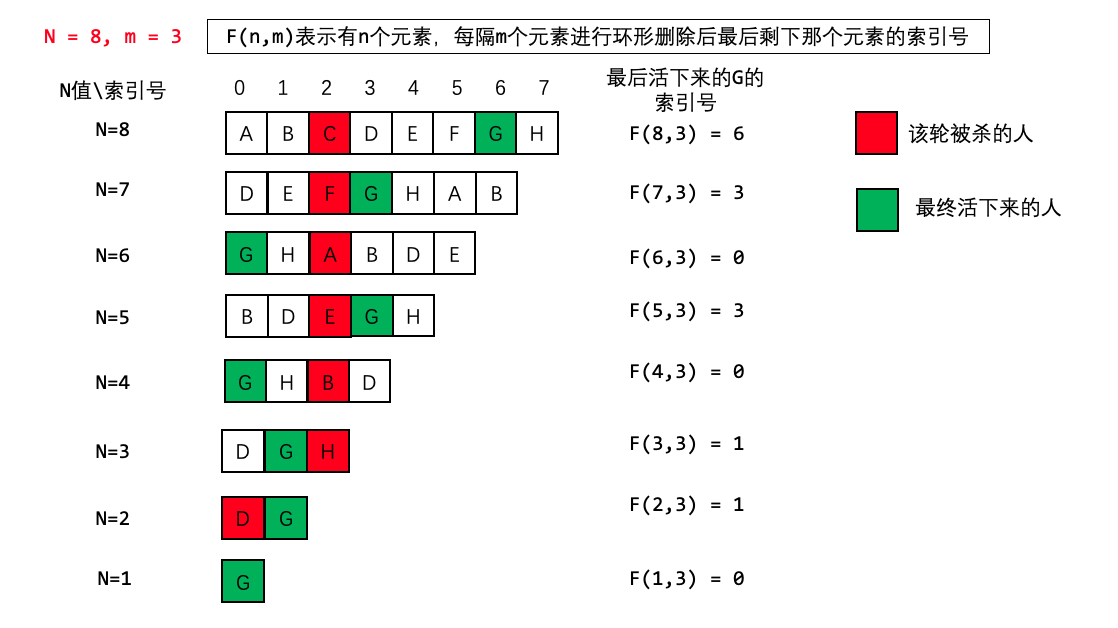 从8个人开始,每次杀掉一个人,去掉被杀的人,然后把杀掉那个人之后的第一个人作为开头重新编号
从8个人开始,每次杀掉一个人,去掉被杀的人,然后把杀掉那个人之后的第一个人作为开头重新编号
- 第一次C被杀掉,人数变成7,D作为开头,(最终活下来的G的编号从6变成3)
- 第二次F被杀掉,人数变成6,G作为开头,(最终活下来的G的编号从3变成0)
- 第三次A被杀掉,人数变成5,B作为开头,(最终活下来的G的编号从0变成3)
- 以此类推,当只剩一个人时,他的编号必定为0!(重点!)
3、反推(动态规划的思想)
现在我们知道了G的索引号的变化过程,那么我们反推一下 从N = 7
到N = 8 的过程
如何才能将N = 7 的排列变回到N = 8 呢?
我们先把被杀掉的C补充回来,然后右移m个人,发现溢出了,再把溢出的补充在最前面
神奇了 经过这个操作就恢复了N = 8的排列了!
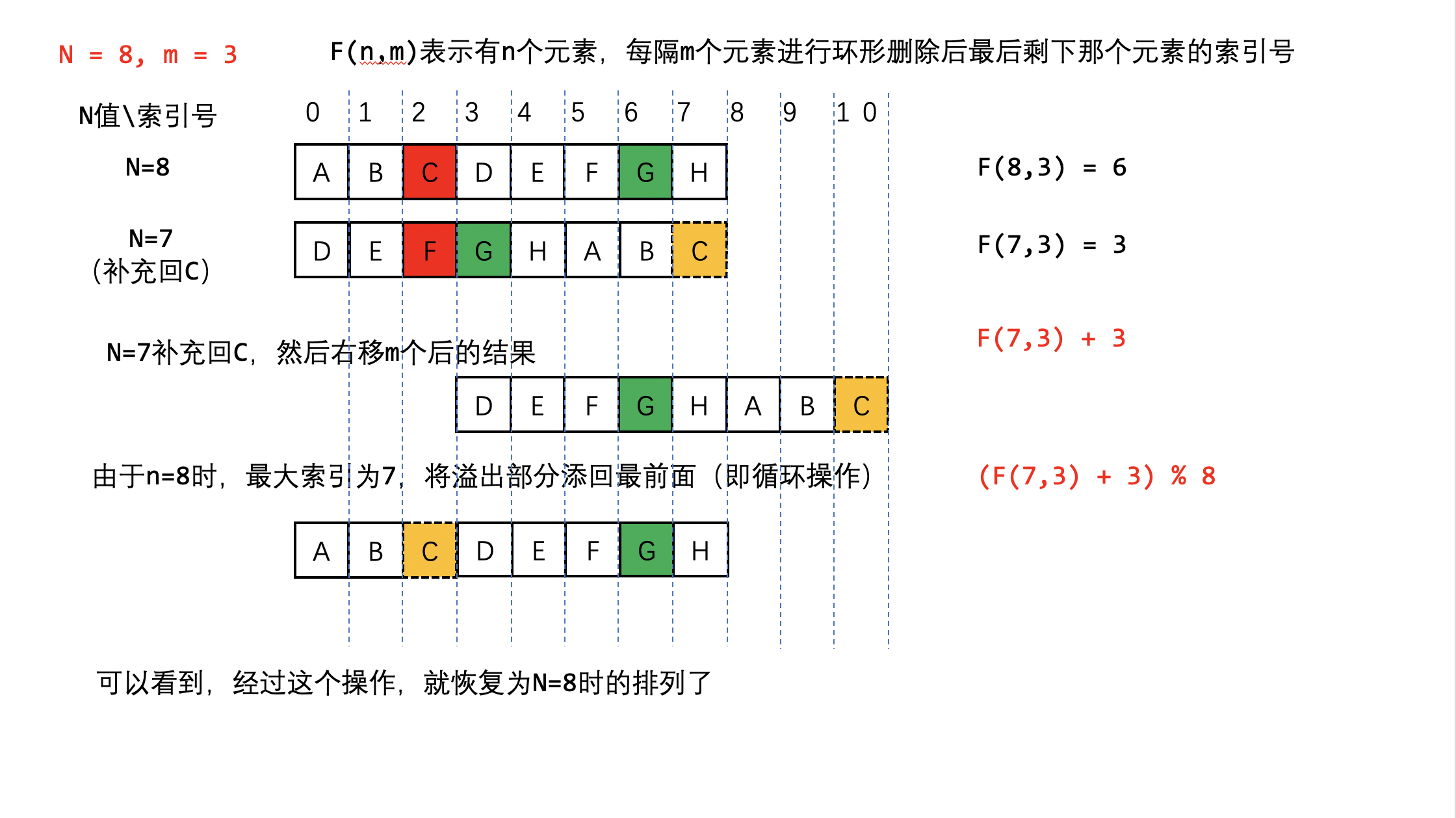 因此我们可以推出递推公式\(f(8,3) = [f(7, 3) + 3] % 8\)
进行推广泛化,即$ f(n,m) = [f(n-1, m) + m] % n$
因此我们可以推出递推公式\(f(8,3) = [f(7, 3) + 3] % 8\)
进行推广泛化,即$ f(n,m) = [f(n-1, m) + m] % n$ 1
2
3
4
5
6
7
8
9class Solution {
public:
int lastRemaining(int n, int m) {
int ans=0;
for(int i(2);i<=n;++i)
ans=(ans+m)%i;
return ans;
}
};
2. 树类
引用leetcode上星晴大佬的笔记
- 引言:
力扣上很多树的题目都是可以用递归很快地解决的,而这一系列递归解法中蕴含了一种很强大的递归思维:对称性递归(symmetric recursion) 什么是对称性递归?就是对一个对称的数据结构(这里指二叉树)从整体的对称性思考,把大问题分解成子问题进行递归,即不是单独考虑一部分(比如树的左子树),而是同时考虑对称的两部分(左右子树),从而写出对称性的递归代码
题型分类: 可以用对称性递归解决的二叉树问题大多是判断性问题(bool类型函数),这一类问题又可以分为以下两类:
- 1、不需要构造辅助函数。这一类题目有两种情况:
- 第一种是单树问题,且不需要用到子树的某一部分(比如根节点左子树的右子树),只要利用根节点左右子树的对称性即可进行递归。
- 第二种是双树问题,即本身题目要求比较两棵树,那么不需要构造新函数。该类型题目如下: 100.相同的树 226.翻转二叉树 104.二叉树的最大深度 110.平衡二叉树 543.二叉树的直径 617.合并二叉树 572.另一个树的子树 965.单值二叉树
- 2、需要构造辅助函数。这类题目通常只用根节点子树对称性无法完全解决问题,必须要用到子树的某一部分进行递归,即要调用辅助函数比较两个部分子树。形式上主函数参数列表只有一个根节点,辅助函数参数列表有两个节点。该类型题目如下: 101.对称二叉树 剑指offer26.s树的子结构
- 1、不需要构造辅助函数。这一类题目有两种情况:
解题模板 下面给出二叉树对称性递归的解题模板
1、递归结束条件:特殊情况的判断 如果是单树问题,一般来说只要进行以下判断:
如果是双树问题(根节点分别为p,q),一般来说进行以下判断:1
2
3if(!root) return true/false;
if(!root->left) return true/false/递归函数;
if(!root->right) return true/false/递归函数;。当然也不完全是这些情况,比如有的需要加上节点值的判断,需要具体问题需要具体分析1
2if(!p && !q)return true/false;
if(!p || !q)return true/false;2、返回值
- 通常对称性递归的返回值是多个条件的复合判断语句
- 可能是以下几种条件判断的组合:
- 节点非空的判断
- 节点值比较判断
- (单树)调用根节点左右子树的递归函数进行递归判断
- (双树)调用两棵树的左右子树的递归函数进行判断
2.1 二叉树
2.1.1 I-从上到下打印二叉树(层次遍历)
【剑指offer】从上到下打印出二叉树的每个节点,同一层的节点按照从左到右的顺序打印。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
//使用队列实现这种遍历
class Solution {
public:
vector<int> levelOrder(TreeNode* root) {
queue<TreeNode*> myqueue;
vector<int>ret;
if(root==NULL)
return ret;
ret.push_back(root->val);
if(root->left)
myqueue.push(root->left);
if(root->right)
myqueue.push(root->right);
while(!myqueue.empty())
{
TreeNode* tmp=myqueue.front();
ret.push_back(tmp->val);
myqueue.pop();
if(tmp->left)
myqueue.push(tmp->left);
if(tmp->right)
myqueue.push(tmp->right);
}
return ret;
}
};1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48/*通过两个栈存储来实现,一个是奇数层的队列,一个为偶数层栈
*不同的是入栈的方式不同:
*- 如果把第一层认为是奇数层,那么对于奇数栈来说,它从左向右遍历,则必须左子树先入栈
*- 对于偶数栈来说,从右往左遍历,则必须右子树先入栈
*/
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
stack<TreeNode*> evenS;
stack<TreeNode*> oddS;
vector<vector<int>> ret;
if(root==NULL)
return ret;
oddS.push(root);
while(!oddS.empty()||!evenS.empty())
{
TreeNode* cur=NULL;
vector<int> tmp;
while(!oddS.empty())
{
cur=oddS.top();
oddS.pop();
tmp.push_back(cur->val);
if(cur->left)
evenS.push(cur->left);
if(cur->right)
evenS.push(cur->right);
}
if(!tmp.empty())
{
ret.push_back(tmp);
continue;
}
while(!evenS.empty())
{
cur=evenS.top();
evenS.pop();
tmp.push_back(cur->val);
if(cur->right)
oddS.push(cur->right);
if(cur->left)
oddS.push(cur->left);
}
ret.push_back(tmp);
}
return ret;
}
};
2.1.3 树的子结构
【剑指offer】输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构)
B是A的子结构, 即
A中有出现和B相同的结构和节点值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14例如:
给定的树 A:
3
/ \
4 5
/ \
1 2
给定的树 B:
4
/
1
返回 true,因为 B 与 A 的一个子树拥有相同的结构和节点值。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26//对称性
/*
*两个树的结构相同,则根节点相同,左右子树的结构也要相同
*/
class Solution {
public:
bool isSubStructure(TreeNode* A, TreeNode* B) {
//如果任一子树为空,返回false
if(!A||!B)
return false;
//如不为空,则可判断以根节点为根,以根节点的左子树为根,或者以根节点的右子树为根,
//三者中只要满足一个与B相同,则可认为B是A的子结构
return hasSameDfs(A,B)||isSubStructure(A->left,B)||isSubStructure(A->right,B);
}
bool hasSameDfs(TreeNode*A,TreeNode*B)
{
//递归退出条件1:B为NULL时,说明B可全部由A表示
if(!B)
return true;
//条件2是:A为NULL,但B不为NULL,说明A不能完全表示B;或者值不相等
if(!A||A->val!=B->val)
return false;
//上面都不满足,则说明当前A->val==B->val,继续比较
return hasSameDfs(A->left,B->left)&&hasSameDfs(A->right,B->right);
}
};
2.1.4 树的镜像(翻转二叉树)
请完成一个函数,输入一个二叉树,该函数输出它的镜像。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18/*
*对称递归:在递归中交换左右子树,无需
*/
class Solution {
public:
TreeNode* mirrorTree(TreeNode* root) {
if(!root)
return root;
//交换左右子树
TreeNode* tmp=root->left;
root->left=root->right;
root->right=tmp;
//对称递归
mirrorTree(root->left);
mirrorTree(root->right);
return root;
}
};
2.1.5 重建二叉树
入某二叉树的前序遍历和中序遍历的结果,请构建该二叉树并返回其根节点。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。
思路:自顶向下构造
- 二叉树的中序遍历中根节点将数组分为左右子树,前序遍历的结果第一个元素总是当前分支的根,因此可构造一个辅助函数
TreeNode* build(preorder,inorder,preB,preE,inB,inE) preB、preE表示当前要构建根节点及其子树的所有节点的始末位置,inB、inP则表示中序遍历的- 递归构造规律
- 用前序结果的第一个
preorder[preB]构造根节点 - 在中序遍历中寻找该根节点位置Incur,此时知道中序遍历的
[inB,Incur-1](Incur-1>=inB)为左子树,对应于前序遍历的[preB+1,PreB+Incur-inB](PreB+Incur-inB>=preB+1) - 同理中序遍历的
[Incur+1,inE]为右子树,对应于前序遍历的[preB+Incur-inB+1,preE]
- 用前序结果的第一个
- 终止条件
if(preB>preE) return NULL;
- 优化
- 优化:在构造的第二步中每次都要寻找中序遍历的根节点,导致时间复杂度为
O(n*n),用unorder_map来存储,时间复杂度为O(n)
- 优化:在构造的第二步中每次都要寻找中序遍历的根节点,导致时间复杂度为
1 | /* |
2.1.6 序列化二叉树
请实现两个函数,分别用来序列化和反序列化二叉树。
你需要设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
思路:
- 上面的重建二叉树利用了前序遍历和中序遍历的分布性质,但前提是数中不存在相同的值,此题并未说明值保证不同,因此无法使用前序和中序的性质。
- 可考虑层序遍历来构造,在序列化中构造含空的层序遍历结果,然后用该层序遍历能够还原出二叉树
- 在下方程序中最聪明的就是用
ostringstream\istringstream来记录层序结果,然后构造节点数组,最关键的是index
1 | class Codec { |
2.2 二叉搜索树
二叉搜索树具有左子树比根节点小,右子树比根节点大的特点。
2.2.1 不同的二叉搜索树
给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。
解法一:递归+记忆
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29/下面这个方法更上面的递归是一样的,只不过优化了重复计算
//发现存在许多的重复计算,用unordered_map来存储n与子树数量的计算过的结果,后续可以直接用
*/
class Solution{
unordered_map<int,int> result;
public:
int numTrees(int n)
{
if(n==0||n==1)
return 1;
//如果存在已经计算的结果,直接使用
if(result.find(n)!=result.end())
return result[n];
long count=0;
//还是使用递归,当以i为根节点时,计算其左右子树各有多少种类,此时m*n即可得到以i为根时的种类
for(int i=1;i<=n;++i)
{
//以i为根时的总数
//左子树有多少种
long leftnums=numTrees(i-1);
//右子树有多少种
long rightnums=numTrees(n-i);
//相乘就是以节点i为根的种类数
count+=leftnums*rightnums;
}
result[n]=count;
return count;
}
};解法二:动态规划
2.2.2 二叉搜索树的最近公共祖先节点
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉搜索树:
root = [6,2,8,0,4,7,9,null,null,3,5],寻找2、4的最近祖先,那么2就是最近的公共祖先
思路:自顶向下的搜索(循环和递归均可)
- 树为二叉搜索树,那么又左子树小于根节点,右子树大于根节点的规则,可有这样几种情况
p->val>root->val&&q->val>root->val,说明p、q都位于右子树,此时最近的公共祖先必不是root,向右前进p->val<root->cal&&q->val<root->val,说明p、q都位于左子树,此时最近的公共祖先必不是root,向左前进- 若有任一
p或q的val值等于root->val,那么root必然是最近祖先节点 - 当
p\q分别位于root的左右子树时,root为最近的祖先节点
1 | class Solution { |
2.2.3 二叉树的最近公共祖先
这是二叉搜索树的最近公共祖先的升级版本。不具有二叉搜索树的大小性质。
题目:给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
思路:因为节点一定在树上且唯一,那么在不同分支找到的节点一定是不同的即分别是p、q
- 情况总结,若
root是它们的最近公共祖先,那么有以下3种情况:p、q分别位于root的左右子树 (2)p==root,q位于root的左子树或者右子树(3)q==root,p位于root的左子树或者右子树(4)
- 退出条件:
root==NULL,return NULL;root==p,return root;root==q,return root(1) - 递归规则:用
isleft记录root左子树的遍历结果;isright记录root右子树的遍历结果,因此采用的是自底向上的回溯,因此返回的一定是最近的祖先节点。
1 | class Solution { |
2.2.4 二叉搜索树的后续遍历
输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历结果。如果是则返回
true,否则返回
false。假设输入的数组的任意两个数字都互不相同。
思路:后序遍历的结果由[左|右|根]的特点,由根节点一知,很容易构造根节点,关键点是如何确定左右分界处。二叉搜索树中,左子树均小于根节点,右子树均大于根节点,因此可通过遍历比较来确定其左右子树的分界线 解法1: 算法步骤:
- 构造一辅助函数
verify(postorder,int b,int e),b、e分别表示当前树的后序遍历范围 - 通过由前往后的遍历确定左右子树分界点,当
postorder[i]>postorder[e]时,即可确定[b,i-1]为左子树节点,[i,e-1]为右子树节点 - 继续遍历
[i,e-1]范围,确定在该范围不存在小于postorder[e]的元素,则进入下一个递归 - 递归退出条件:
b>=e,return true; - 上述算法时间复杂度为\(O(n^2)\),空间复杂度为\(O(n)\),原因是,每一次递归为确定分界处,需要遍历数组,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18class Solution {
public:
bool verify(vector<int>& postorder,int b,int e)
{
if(b>=e)
return true;
int index=0,i=b;
while(postorder[i]<postorder[e])
++i;
index=i;
while(i<e&&postorder[i]>postorder[e])
++i;
return i==e&&verify(postorder,b,index-1)&&verify(postorder,index,e-1);
}
bool verifyPostorder(vector<int>& postorder) {
return verify(postorder,0,postorder.size()-1);
}
};
解法二:
- 我们发现是可以通过记录根节点的大小即当前节点的上下界将比较推迟到当前递归,这样就避免了数组的遍历使得时间复杂度为\(O(n)\)。
左子树<根节点,右子树>根节点,那么引入辅助函数vrify(postorder,ma,mi),其中ma为上界,mi为下限。刚开设设为INT_MAX和-INT_MIN- 取最后一个元素val,比较其值时候在该范围内,不在直接返回
false - 若在,则删除最后一个元素,进入下一轮递归
- 必须先对右子树递归,并更新其下限在
val;然后在左子树递归中,更新其上界在val - 当数组为空时,说明符合搜索时的后序遍历,返回
true;否则返回false1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16bool verify(vector<int>& postorder,int MA,int MI)
{
if(postorder.empty())
return postorder.empty();
int curr=postorder[postorder.size()-1];
if(curr<=MI||curr>=MA)
return postorder.empty();
postorder.erase(postorder.end()-1,postorder.end());
verify(postorder,MA,curr);
verify(postorder,curr,MI);
return postorder.empty();
}
bool verifyPostorder(vector<int>& postorder) {
return verify(postorder,INT_MAX,-INT_MAX);
}
};
2.3 平衡二叉树
平衡二叉树又称为AVL树,它的设计是为了防止在二叉搜索树中退化成链表的一种数据结果,特点:
- 规定左右子树的的深度差不能超过1,即平衡因子
|bf|<=1 - 左子树值小于根节点,右子树大于
2.3.1 平衡二叉树判断
输入一棵二叉树的根节点,判断该树是不是平衡二叉树。如果某二叉树中任意节点的左右子树的深度相差不超过1,那么它就是一棵平衡二叉树。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31*
*解法1:自顶向上(暴力解),得到每个节点左右深度,当>1时返回-1,由于存在大量的重复计算
*时间复杂度为O(n*n)
*
*解法2:自低向上,规避了重复计算,时间复杂度为O(n)
*借辅助函数height(root)计算节点的深度,返回两种情况
返回值:
- 当节点root 左 / 右子树的深度差 ≤1 :则返回当前子树的深度,即节点 root 的左 / 右子树的深度最大值 +1
( max(left, right) + 1 );
- 当节点root 左 / 右子树的深度差 >2 :则返回 −1 ,代表 此子树不是平衡树 。
终止条件
root=NULL return 0
leftheight==-1||rightheight==-1||abs(leftheight,rightheight)>1 return -1
*/
class Solution {
public:
bool isBalanced(TreeNode* root) {
return height(root)>=0;
}
int height(TreeNode* root)
{
if(root==NULL)
return 0;
int leftheight=height(root->left);
int rightheight=height(root->right);
if(leftheight==-1||rightheight==-1||abs(leftheight-rightheight)>1)
return -1;
else
return 1+max(leftheight,rightheight);
}
};
3. 链表类
3.1 两数相加
给你两个 非空
的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。请你将两个数相加,并以相同形式返回一个表示和的链表。你可以假设除了数字
0 之外,这两个数都不会以 0 开头。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {
ListNode* head=l1;
int jingwei=0;
ListNode* prio;
while(l1&&l2)
{
l1->val=l1->val+l2->val+jingwei;
prio=l1;
jingwei=0;
if(l1->val>9)
{
l1->val-=10;
jingwei=1;
}
l1=l1->next;
l2=l2->next;
}
if(l1&&!l2)
{
l1->val+=jingwei;
jingwei=0;
while(l1&&l1->val>9)
{
prio=l1;
jingwei=1;
l1->val-=10;
l1=l1->next;
if(l1){
l1->val+=jingwei;
jingwei=0;
}
}
}
else if(!l1&&l2)
{
prio->next=l2;
l1=l2;
l1->val+=jingwei;
jingwei=0;
while(l1&&l1->val>9)
{
prio=l1;
jingwei=1;
l1->val-=10;
l1=l1->next;
if(l1){
l1->val+=jingwei;
jingwei=0;
}
}
}
if(jingwei)
{
prio->next=new ListNode(jingwei,NULL);
}
return head;
}
};
3.2 删除链表倒数第N个节点
1 | class Solution { |
3.3 合并K个有序链表
给你一个链表数组,每个链表都已经按升序排列。请你将所有链表合并到一个升序链表中,返回合并后的链表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
//使用分治的思想,分别两两合并
//使用递归实现:
//递归退出条件为:一是传入的只有一个链表另一个为NUL,二是传入的均为NULL,直接返回
//程序结构:mergeKList为主调用,不做其他功能,merge递归入口,当达到底层是使用mergeTwoList
return merge(lists,0,lists.size()-1);
}
ListNode* mergeTwoList(ListNode* a,ListNode* b)
{
if(NULL==a||NULL==b)
return NULL==a?b:a;
ListNode* head=NULL;
if(a->val>b->val){
head=b;
b=b->next;
}
else
{
head=a;
a=a->next;
}
ListNode* tempNode=head;
while(a&&b)
{
if(a->val>b->val)
{
tempNode->next=b;
b=b->next;
}
else{
tempNode->next=a;
a=a->next;
}
tempNode=tempNode->next;
}
if(a)
tempNode->next=a;
else
tempNode->next=b;
return head;
}
ListNode* merge(vector<ListNode*>& lists,int l,int r)
{
int m=(r+l)/2;
if(r==l)
return lists[r];
else if(r<l)
return NULL;
else
return mergeTwoList(merge(lists,l,m),merge(lists,m+1,r));
}
};
3.4 两两交换链表中的节点
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
//使用双指针,前一指针比后一指针快一步,然后交换指向即可
//为方便,在链表头部添加一节点pHead
ListNode* front=NULL,*back=NULL,*pHead=new ListNode();
pHead->next=head;
if(head==NULL||head->next==NULL)
return head;
back=head;
front=head->next;
ListNode* ret=pHead;
while(front!=NULL)
{
//交换
back->next=front->next;
front->next=back;
pHead->next=front;
//更新
pHead=back;
if(back->next!=NULL){
back=back->next;
front=back->next;
}
else
{
front=NULL;
back=NULL;
}
}
return ret->next;
}
};
3.5 K个一组翻转链表
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
1 | /** |
3.6 环形链表II
给定一个链表的头节点head,返回链表开始入环的第一个节点。
如果链表无环,则返回 null。
分析:
假设链表有环,分为两部分a和b,a为无环长度,b为有环长度,使用快慢指针fast、slow进行遍历,快指针步长为2,慢指针步长为1
-
那么当有环时,快慢指针必定会相遇,另快指针走过节点为f,慢指针为s,则第一次相遇后有f=2s,f=s+nb,
-
所以f=2nb,此时另slow从头节点重写走,fast从f处变成慢指针走,当他们走a步时再次相遇,此时就是环的入口节点
1 | class Solution { |
4. 字符串类
字符串也是数组类型,因此与数组一样,类型繁多。
4.1 N字形变换
将一个给定字符串 s 根据给定的行数 numRows
,以从上往下、从左到右进行 Z 字形排列。如输入字符串为
PAYPALISHIRING 行数为 4 时,排列如下: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38输入:s = "PAYPALISHIRING", numRows = 4
输出:"PINALSIGYAHRPI"
解释:
P I N
A L S I G
Y A H R
P I
//对于numRows有这样的一个规律:
//按规定第一列取s的前numRows个字符,即i=0.....numRows
//对于i行后面的列每隔(numRows-1)*2+i取一个,直到(numrow-1)*2*j>s.size()为止,j>=1
//同时对于第i行,在取s[(numRow-1)*2*j+i]时,
//前面应该还有当(numRows-1)*2*j+i-2i!=(numRows-1)*2*(j-1)+i时添加一个字符为s[(numsRow-1)*2*j+i-2i]
//或者只需排除第一行和最后一行即可
//时间复杂度为O(N),空间复杂度为O(N)
class Solution {
public:
string convert(string s, int numRows) {
string ret="";
if(numRows==1)
return s;
for(int i=0;i<numRows&&i<s.size();i++) //第i行存储
{
ret+=s[i];
int gapDistance=(numRows-1)*2;
for(int j=1;gapDistance*j-i<s.size();j++)//寻找下一个位置
{
if(i!=0&&i!=numRows-1) //判断是不是第一行或者最后一行,不是则进入
{
ret+=s[gapDistance*j-i];
}
if(gapDistance*j+i<s.size())
ret+=s[gapDistance*j+i];
}
}
return ret;
}
};
4.2 字符串最大公因子
对于字符串
s和t,只有在s = t + ... + t(t 自身连接 1 次或多次)时,我们才认定 “t 能除尽 s”。 给定两个字符串str1和str2。返回 最长字符串x,要求满足x能除尽str1且x能除尽str2
思路:
给定了str1和str2,设其长度为n和m,这道题需要记住的两个性质
如果存在一个符合要求的字符串
X,那么也一定存在一个符合要求的字符串X',它的长度为str1和str2长度的最大公约数。如果
str1和str2拼接后等于str2和str1拼接起来的字符串(注意拼接顺序不同),那么一定存在符合条件的字符串 X,str1和str2由X拼接而成
有了该性质以及方法二的性质,我们就可以先判str1 和
str2拼接后是否等于 str2 和str1
拼接起来的字符串,如果等于直接输出长度为
gcd(len1,len2)的前缀串即可,否则返回空串。
1 | class Solution { |
4.3 最长回文子串(Manacher算法解决)
给你一个字符串 s,找到 s 中最长的回文子串。
如果字符串的反序与原始字符串相同,则该字符串称为回文字符串。
思路:使用Manacher算法以\(O(N)\)时间复杂度解决 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33string longestPalindrome(string s) {
int n=s.size();
string str="@";
for(int i=0;i<n;++i)
str+="#"+s.substr(i,1);
str+="#%";
n=str.size();
vector<int> L(n,0);
int r=0,k=0;
//构造L
for(int i=1;i<n-1;++i){
if(i<r) L[i]=min(L[(k*2)-i],r-i);
else L[i]=0;
//执行暴力匹配
while(str[i-L[i]-1]==str[i+L[i]+1]) ++L[i];
//更新k,r
int R=L[i]+i;
if(R>r){
r=R,k=i;
}
}
//找最长回文串
int Max=0,idx=0;
for(int i=0;i<n;++i){
if(L[i]>Max){
Max=L[i];
idx=i;
}
}
int start=(idx-Max)>>1;
return s.substr(start,Max);
}
Manacher算法解决回文串一类题目,KMP算法解决字符串匹配一类题目,注意,要明白L数组和next数组的含义
4.4 重复的子字符串
给定一个非空的字符串 s ,检查是否可以通过由它的一个子串重复多次构成
分析:果长度为n的字符串s是字符串
t=s+s的子串,并且s在t中的起始位置不为0 或 n,那么可证明s由子串s'`构成。那么这样就可以利用KMP算法来解答此题
1 | class Solution { |
4.5 最小覆盖子串
给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 "" 。
思路:
可尝试使用滑动窗口思路解决,先用哈希Hash记录t的字母出现次数,之后对s进行滑动窗口排查
l,r表示窗口的左右边界,该问题现在转化为求最满足题意得最小窗口- 当
t出现在窗口内,++l - 当
t不在窗口内,++r
对于t是否出现在窗口,必须使用一个数据结构来记录当前窗口出现字母,在right右移的时候能够判断该字符是否是t当中的字符,并且判断加入这个字符后当前窗口是否满足t,满足则进入left右移;对于left右移,能够判断当前窗口移除该字符后,是否破坏满足条件,若破坏了就必须能够知道破坏后的窗口缺了多少个什么字符才能再次满足·
- 使用哈希
need记录t中各字符出现的次数。 - 使用
count来指示当前窗口还有多少各字符为满足。count==0时说明满足 - 再使用一个哈希来
windows来记录窗口中出现t中字符的数量,当windows于need一一对应时,则认为当前窗口满足了
1 | class Solution { |
5. 双指针类
5.1 无重复字符的最长子串
问题:给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
示例: 输入: s = "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
1 | int lengthOfLongestSubstring(string s) { |
5.2 盛最多水的容器
问题:给定一个长度为n的整数数组height。有n条垂线,第i条线的两个端点是(i, 0)和(i, height[i])。找出其中的两条线,使得它们与x轴共同构成的容器可以容纳最多的水。返回容器可以储存的最大水量。。
1 | int maxArea(vector<int>& height) { |
5.3 三数之和
算法思路:
- 1、特判,对于数组长度
n,如果数组为null或者数组长度小于3,返回[] - 2、对数组进行排序。
- 3、遍历排序后数组:
- 若
nums[i]>0:因为已经排序好,所以后面不可能有三个数加和等于0,直接返回结果。 - 对于重复元素:跳过,避免出现重复解
- 令左指针
L=i+1,右指针R=n-1,当L<R时,执行循环:- 当
nums[i]+nums[L]+nums[R]==0,执行循环,判断左界和右界是否和下一位置重复,去除重复解。并同时将 L,R 移到下一位置,寻找新的解 - 若和大于0,说明
nums[R]太大,R左移 - 若和小于0,说明
nums[L]太小,L右移
- 当
- 若
1 | vector<vector<int>> threeSum(vector<int>& nums) { |
5.4 最接近的三数之和
给你一个长度为 n 的整数数组 nums 和 一个目标值 target。请你从 nums
中选出三个整数,使它们的和与 target 最接近。返回这三个数的和。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36class Solution {
public:
int threeSumClosest(vector<int>& nums, int target) {
/*
*使用三数之和的方法:
*1、先对数组进行排序
*2、之后想三数之和一样遍历排序后的数组:
*时间复杂度为O(N*N),空间复杂度为O(1)
*/
sort(nums.begin(),nums.end());
int ret=nums[0]+nums[1]+nums[nums.size()-1];
int len=nums.size();
for(int i=0;i<len;i++)
{
int right=len-1,left=i+1;
while(left<right)
{
//比较ret是否要更新
if(abs(target-(nums[i]+nums[left]+nums[right]))
<abs(target-ret))
ret=nums[i]+nums[left]+nums[right];
//双指针应该向哪边移动
if(target<nums[i]+nums[left]+nums[right]){
right--;
}
else if(target>nums[i]+nums[left]+nums[right]){
left++;
}
else
return target;
}
}
return ret;
}
};
5.5 四数之和
给你一个由 n
个整数组成的数组nums,和一个目标值target
。请你找出并返回满足下述全部条件且不重复的四元组[nums[a], nums[b], nums[c], nums[d]]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46class Solution {
public:
vector<vector<int>> fourSum(vector<int>& nums, int target) {
//解决方法同三数求和一样,使用排序+双指针方法
//只不过此时多加了一层循环,则时间复杂度为O(N^3),
long Target=target;
vector<vector<int>>ret;
if(nums.size()<4)
return ret;
sort(nums.begin(),nums.end());
for(int i=0;i<nums.size()-3;i++)
{
if(nums[i]>0&&Target<1)
return ret;
for(int j=nums.size()-1;j>=i+3;j--)
{
int left=i+1,right=j-1;
while(left<right)
{
long result=(long)nums[i]+(long)nums[j]+
(long)nums[left]+(long)nums[right];
if(Target<result)
right--;
else if(Target>result)
left++;
else{
ret.push_back({nums[i],nums[j],nums[left],nums[right]});
while(right>left&&nums[right]==nums[right-1])
right--;
while(right>left&&nums[left]==nums[left+1])
left++;
right--;
left++;
}
}
//跳过重复
while(j>=i+3&&nums[j]==nums[j-1])
j--;
}
//跳过重复
while(i<nums.size()-3&&nums[i]==nums[i+1])
i++;
}
return ret;
}
};
6. 深度优先搜索类
6.1 括号组合
数字 n
代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的
括号组合。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41/*dfs思路:
*- 1、使用n1\n2记录'('和')'的剩余个数,初始均为n
*- 2、用一个整数k记录目前组合的字符串前面还有多少个'('未形成组合,如"(()"前面还有一个'('未形成组合
*- 3、递归条件:当前字符串前面没有'('可组合只能进入'('递归,前面有'('可组合则'('和')'均可进入
*- 4、到达递归结束时直接将组合成的字符串压入vector即可,退出递归
*/
class Solution {
public:
vector<string> generateParenthesis(int n) {
vector<string> ret;
string s="";
dfsGP(ret,s,n,n,0);
return ret;
}
inline void dfsGP(vector<string>&vec,string s,int n1,int n2,int k)
{
if(n1==0&&n2==0){
vec.push_back(s);
return;
}
if(k==0)
{
s+="(";
dfsGP(vec,s,n1-1,n2,k+1);
}
else
{
if(n1!=0)
{
string s1=s+"(";
dfsGP(vec,s1,n1-1,n2,k+1);
}
if(n2!=0)
{
s+=")";
dfsGP(vec,s,n1,n2-1,k-1);
}
}
}
};
6.2 组合总和
给你一个 无重复元素
的整数数组 candidates
和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target
的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序
返回这些组合。
candidates 中的 同一个 数字可以
无限制重复被选取
。如果至少一个数字的被选数量不同,则两种组合是不同的。
- 方法一:搜索回溯 思路与算法
对于这类寻找所有可行解的题,我们都可以尝试用「搜索回溯」的方法来解决。
- 回到本题,我们定义递归函数
dfs(target,combine,idx)表示当前在candidates数组的第idx位,还剩target要组合,已经组合的列表为combine。 - 递归的终止条件为
target≤0或者candidates数组被全部用完。 - 那么在当前的函数中,每次我们可以选择跳过不用第
idx个数,即执行dfs(target,combine,idx+1)。 - 也可以选择使用第
idx个数,即执行dfs(target−candidates[idx],combine,idx),注意到每个数字可以被无限制重复选取,因此搜索的下标仍为idx。
更形象化地说,如果我们将整个搜索过程用一个树来表达,即如下图呈现,每次的搜索都会延伸出两个分叉,直到递归的终止条件,这样我们就能不重复且不遗漏地找到所有可行解
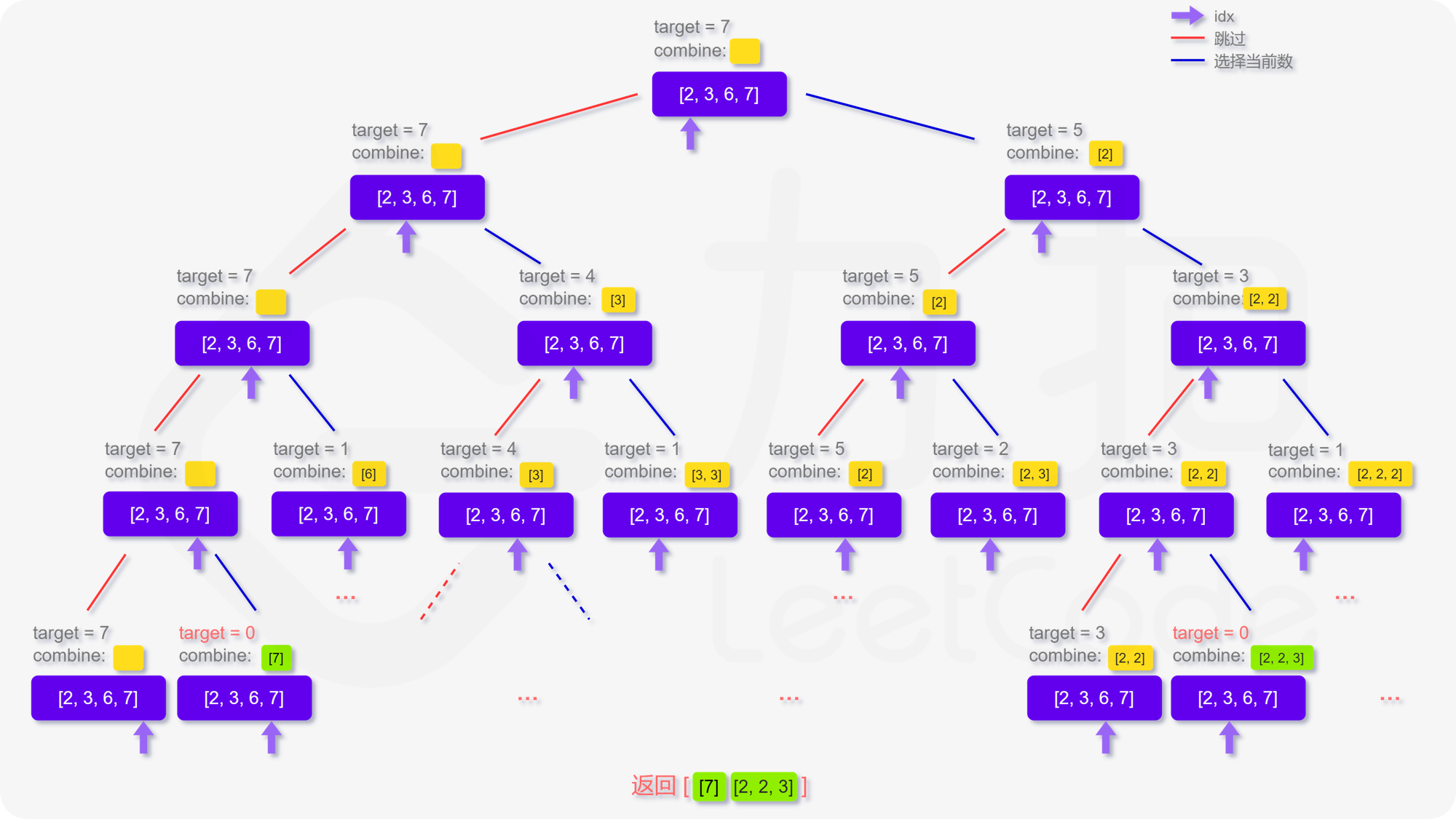
1 | class Solution { |
上面算法没有用到剪枝,利用剪枝可以节省一些时间
6.3 全排列
给定一个不含重复数字的数组 nums ,返回其
所有可能的全排列 。你可以 按任意顺序 返回答案。 1
2输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]n 个数的数组 nums
划分成左右两个部分,左边的表示已经填过的数,右边表示待填的数,我们在回溯的时候只要动态维护这个数组即可。
- 具体来说,假设我们已经填到第
first个位置,那么nums数组中[0,first−1]是已填过的数的集合,[first,n−1]是待填的数的集合。 - 我们肯定是尝试用
[first,n−1]里的数去填第first个数,假设待填的数的下标为i,那么填完以后我们将第i个数和第first个数交换,即能使得在填第first+1个数的时候nums数组的[0,first]部分为已填过的数,[first+1,n−1]为待填的数, - 回溯的时候交换回来即能完成撤销操作。
1 | class Solution { |
7. 广度优先搜索类
8. 数学
8.1 下一个排列
整数数组的一个 排列 就是将其所有成员以序列或线性顺序排列。
- 例如,
arr = [1,2,3],以下这些都可以视作 arr 的排列:[1,2,3]、[1,3,2]、[3,1,2]、[2,3,1]。
整数数组的 下一个排列 是指其整数的下一个字典序更大的排列。更正式地,如果数组的所有排列根据其字典顺序从小到大排列在一个容器中,那么数组的 下一个排列 就是在这个有序容器中排在它后面的那个排列。如果不存在下一个更大的排列,那么这个数组必须重排为字典序最小的排列(即,其元素按升序排列)。
- 例如,
arr = [1,2,3]的下一个排列是[1,3,2]。 - 类似地,
arr = [2,3,1]的下一个排列是[3,1,2]。 - 而
arr = [3,2,1]的下一个排列是[1,2,3],因为[3,2,1]不存在一个字典序更大的排列。
给你一个整数数组 nums,找出nums
的下一个排列。
必须 原地 修改,只允许使用额外常数空间。
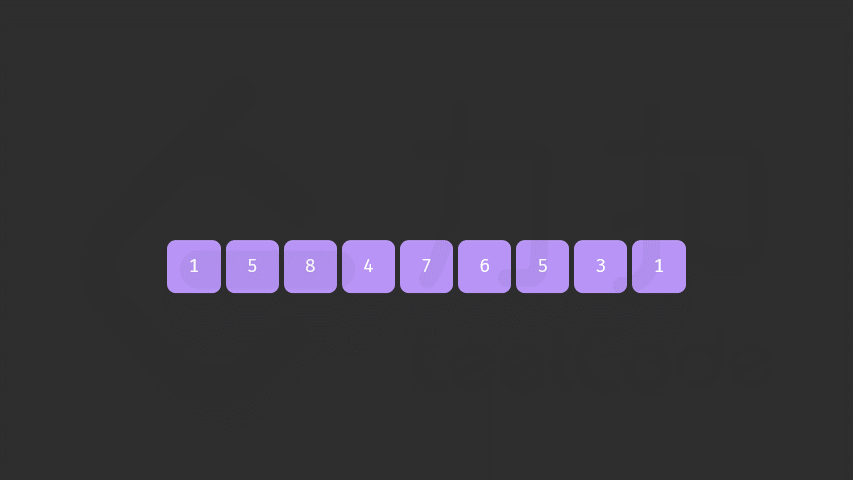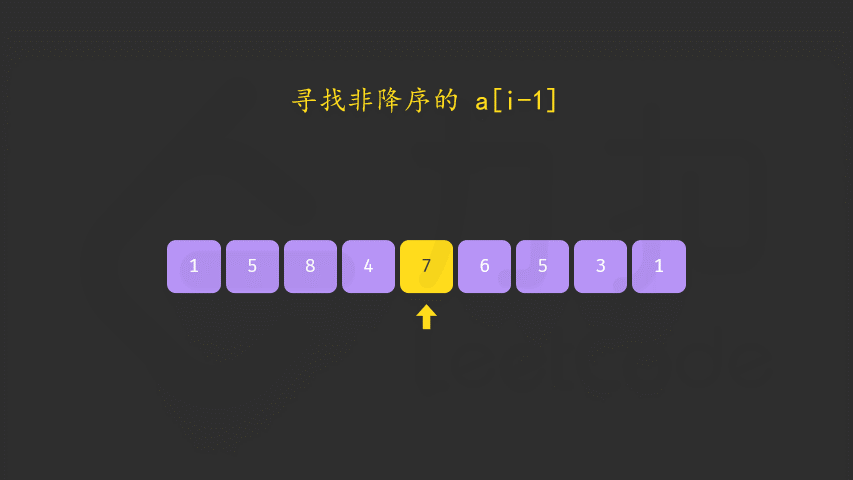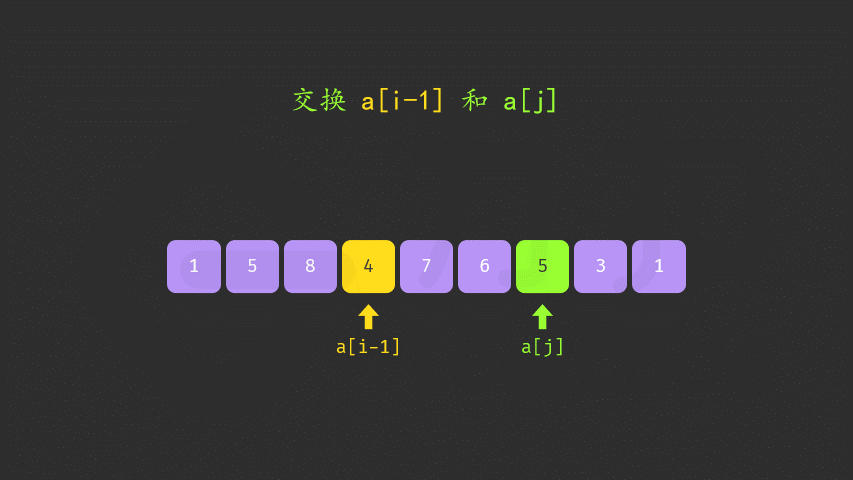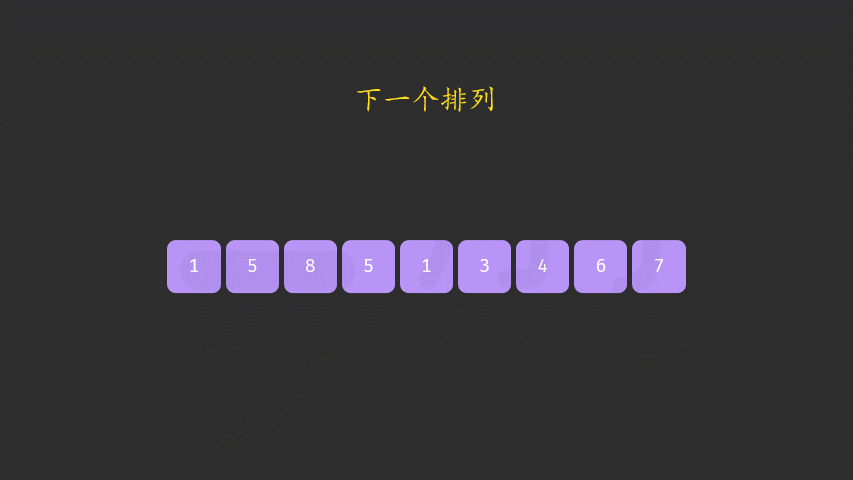
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38*/
/*双遍历:
*- 1、数组从后往前遍历,直到遇到第一个nums[i-1]<nums[i],记录该index_1=i-1
*- 2、数组再次从后往前遍历,遇到第一个nums[j]>nums[index],记录下标index_2=j
*- 3、交换nums[index_1]和nums[index_2]的值
*- 4、交换完成后,由上面的步骤一定可知道从[nums.begin()+index_1+1,nums.end()]一定是降序的,直接reverse该范围即可得到下一个子序列
*- 5、如果遍历完都不存在,就说明全部是逆序,直接reverse返回
*时间复杂度为O(N),空间复杂度为O(1)
*/
class Solution{
public:
void nextPermutation(vector<int>& nums) {
int index_1=-1,index_2=-1;
for(int i=nums.size()-1;i-1>=0;i--)
{
if(nums[i]<=nums[i-1])
continue;
index_1=i-1;
break;
}
if(index_1==-1)
reverse(nums.begin(),nums.end());
else
{
for(int j=nums.size()-1;j>index_1;j--)
{
if(nums[j]<=nums[index_1])
continue;
index_2=j;
break;
}
nums[index_1]^=nums[index_2];
nums[index_2]^=nums[index_1];
nums[index_1]^=nums[index_2];
reverse(nums.begin()+index_1+1,nums.end());
}
}
};
9. 矩阵
10. 图类
涉及到图类的题目,最多就是dfs、bfs、拓扑排序(有相同的环路问题)和并查集。
10.1 拓扑排序:课程表
你这个学期必须选修numCourses
门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。
先修课程按数组 prerequisites
给出,其中 prerequisites[i] = [ai, bi]
,表示如果要学习课程 ai 则 必须
先学习课程 bi
解题思路:
理解该题就是判断图的是否有环,可以使用拓扑排序/并查集, 这里我们使用拓扑排序,拓扑排序换的核心思想就是就是计算每个课程的入度,话句话说其实就是修这个课程之前要预先修的课程数量 - 首先将所有入度为0的节点入队列 - 出队列,得到节点,之后将该元素指向的节点的入度-1 - 如果上面过程有新的节点的入度为0,入队列 - 反复上述操作,直到队列为空
1 | class Solution { |
10.2 岛屿数量
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围
解题思路
深度优先遍历数组(四个方向),为了避免重复遍历,已经遍历过的1置为0
-
当前位置位0或者.,表示不是岛屿或者已经遍历过,直接进行到下一个位置
-
当前位置为1,是岛屿,此时进入深度优先遍历,先++islands,深度优先的作用就是将同一个岛屿1置为0,避免重复计算
- 在广度优先中不断向四个方向判断遍历,并将1置为0
1 | lass Solution { |
10.3 除法求值
11. 模拟
11.1 字符串转整数
请你来实现一个 myAtoi(string s) 函数,使其能将字符串转换成一个 32 位有符号整数(类似 C/C++ 中的 atoi 函数)。
函数 myAtoi(string s) 的算法如下:
- 读入字符串并丢弃无用的前导空格
- 检查下一个字符(假设还未到字符末尾)为正还是负号,读取该字符(如果有)。 确定最终结果是负数还是正数。 如果两者都不存在,则假定结果为正。
- 读入下一个字符,直到到达下一个非数字字符或到达输入的结尾。字符串的其余部分将被忽略。
- 将前面步骤读入的这些数字转换为整数(即,"123" -> 123, "0032" -> 32)。如果没有读入数字,则整数为 0 。必要时更改符号(从步骤 2 开始)。
- 如果整数数超过 32 位有符号整数范围 [−231, 231 − 1] ,需要截断这个整数,使其保持在这个范围内。具体来说,小于 −231 的整数应该被固定为 −231 ,大于 231 − 1 的整数应该被固定为 231 − 1 。
- 返回整数作为最终结果。
注意:
- 本题中的空白字符只包括空格字符 ' ' 。
- 除前导空格或数字后的其余字符串外,请勿忽略 任何其他字符。
1 | //易错点: |
11.2 剑指offer29. 顺时针打印矩阵
输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字。
思路:首先从外圈向内圈进行打印,圈按顺时针方向,分别为从左向右,从上到下,从右到左,从下到上。用四个遍历分别记录上边界、下边界、左边界和右边界
1 | /* |
11.3 顺时针转90°
11.4 包含min函数的栈
定义栈的数据结构,请在该类型中实现一个能够得到栈的最小元素的 min
函数在该栈中,调用 min、push 及 pop 的时间复杂度都是 O(1)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55class MinStack {
public:
/** initialize your data structure here. */
long num_min;
stack<long> stack_diff;
MinStack() {
}
void push(int x) {
/*
*压入:我们以差值的形式压入,即currValue-min,
*- 为空时,直接设min=currValue,因此压入0
*- 当差值<0时,说明此时压入的值比之前最小值还小,因此要更新最小值,此时先压入currValue-max,之后
更新min=currValue
*- 当差值>=0时,说明压入值比之前最小值大,不要更新,直接压入差值即可
*取栈顶:
*- 当stack[top]>0,说明其不是最小值,要返回min+stack[top]
*- 当stack[top]<=0,说明此时栈顶是最小值,直接返回min即可
*弹出:
*- 当stack[top]>0,说明其不是最小值,不用更新最小值,直接弹出pop即可
*- 当stack[top]<=0时,说明当前栈顶是最小值,弹出后要更新最小值,右上面推导知道,当前值currvalue是最小值,差值=currValue-min<=0,那么弹出后的最小值是min=currValue-差值,即min-=stack[top]
*/
if(stack_diff.empty())
{
num_min = x;
stack_diff.push(0);
return;
}
stack_diff.push((long)x-num_min);
if(x < num_min)
{
num_min = x;
}
}
void pop() {
//每次pop都有更新现有栈的num_min
if(stack_diff.top() < 0)
{
num_min -= stack_diff.top();
}
stack_diff.pop();
}
int top() {
if(stack_diff.top() >= 0)
{
return stack_diff.top()+num_min;
}
else
{
return num_min;
}
}
int min() {
return num_min;
}
};
11.5 剑指offer59-II. 队列的最大值
请定义一个队列并实现函数 max_value
得到队列里的最大值,要求函数max_value、push_back 和
pop_front 的均摊时间复杂度都是O(1)。
若队列为空,pop_front 和 max_value 需要返回
-1
思路: -
使用两个队列来实现,一个是普通的先进先出队列q,另一个是双端队列d; -
主要是双端队列,它是单调递减形式,队头最是当前进队列数字的最大值,每次插入都会与队尾元素不断比较,如果d.back()<value,则弹出,这就保证了max_Value
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34/*
*使用两个队列来实现,一个是普通的先进先出队列q,另一个是双端队列d;
*其中:普通队列记录正常进出顺序,保证push_back和pop_front的功能,双端队列为单调减队列,它存储当前的最大值
*即在双端队列中,每次插入都会与队尾元素不断比较,如果d.back()<value,则弹出,这就保证了max_Value
*/
class MaxQueue {
queue<int> q;
deque<int> d;
public:
MaxQueue() {
}
int max_value() {
if(d.empty())
return -1;
return d.front();
}
void push_back(int value) {
//双端队列进行比较
while(!d.empty()&&d.back()<value)
d.pop_back();
d.push_back(value);
q.push(value);
}
int pop_front() {
if(q.empty())
return -1;
int ret=q.front();
if(ret==d.front())
d.pop_front();
q.pop();
return ret;
}
};
11.6 滑动窗口最大值
给你一个整数数组nums,有一个大小为
k的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的
k个数字。滑动窗口每次只向右移动一位。\(1<=k<=nums.size()\)
- 暴力解会超时,暴力复杂度为O(nk)
- 滑动窗口的滑动中,数字的进出很想队列的先进先出,因此可使用单调队列来优化时间复杂度
1 | /* |
11.7 正则表达式匹配
请实现一个函数用来匹配包含.和*的正则表达式。模式中的字符.表示任意一个字符,而*表示它前面的字符可以出现任意次(含0次)。在本题中,匹配是指字符串的所有字符匹配整个模式。例如,字符串aaa与模式a.a和ab*ac*a匹配,但与aa.a和ab*a均不匹配。
s可能为空,且只包含从a-z的小写字母。p可能为空,且只包含从a-z的小写字母以及字符 . 和*,无连续的'*'。
11.8 LRU
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。 实现
LRUCache 类:
LRUCache(int capacity)以 正整数 作为容量capacity初始化LRU缓存int get(int key)如果关键字key存在于缓存中,则返回关键字的值,否则返回-1。void put(int key, int value)如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以O(1)
的平均时间复杂度运行。
思路:用双向链表和哈希定位实现,双向链表的目的就是实现逐出最久未使用的关键字
- 按定义,最久未使用的关键字在链表尾部,
- 在更新中会把get
- 为了实现上述查找的O(1)时间复杂度,使用哈希来存储key-节点映射
- 为了能够快速定位头尾节点,使用额外的两个节点pHead、pBack作为头节点和尾部节点
1 | //双向链表 |
11.9 最小覆盖子串
给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 ""
解题思路:
可尝试使用滑动窗口思路解决,先用哈希Hash记录t的字母出现次数,之后对s进行滑动窗口排查
l,r表示窗口的左右边界,该问题现在转化为求最满足题意得最小窗口- 当
t出现在窗口内,++l - 当
t不在窗口内,++r
对于t是否出现在窗口,必须使用一个数据结构来记录当前窗口出现字母,在right右移的时候能够判断该字符是否是t当中的字符,并且判断加入这个字符后当前窗口是否满足t,满足则进入left右移;对于left右移,能够判断当前窗口移除该字符后,是否破坏满足条件,若破坏了就必须能够知道破坏后的窗口缺了多少个什么字符才能再次满足·
- 使用哈希
need记录t中各字符出现的次数。 - 使用
count来指示当前窗口还有多少各字符为满足。count==0时说明满足 - 再使用一个哈希来
windows来记录窗口中出现t中字符的数量,当windows于need一一对应时,则认为当前窗口满足了
1 | class Solution { |
推荐:更巧妙的做法,优化了空间复杂度,也提升了速度,该解题思路来源力扣的zrita
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27class Solution {
public:
string minWindow(string s, string t) {
vector<int> map(128);
int left = 0, right = 0, need = t.size(), minStart = 0, minLen = INT_MAX;
for(char ch : t) ++map[ch]; //统计t中字符出现次数
while(right < s.size())
{
if(map[s[right]] > 0) --need; //窗口右移,每包含一个t中的字符,need-1
--map[s[right]];
while(need == 0) //完全覆盖子串时
{
if(right - left + 1 < minLen) //此时字符被包含在[left,right)中
{
minStart = left;
minLen = right - left + 1;
}
if(++map[s[left]] > 0) ++need; //窗口左移
++left;
}
++right;
}
if(minLen != INT_MAX) return s.substr(minStart, minLen);
return "";
}
};
11.10 O(1)时间插入、删除和随机获取元素
实现
RandomizedSet类:
RandomizedSet()初始化RandomizedSet对象
bool insert(int val)当元素 val 不存在时,向集合中插入该项,并返回 true ;否则,返回 false 。
bool remove(int val)当元素 val 存在时,从集合中移除该项,并返回 true ;否则,返回 false 。
int getRandom()随机返回现有集合中的一项(测试用例保证调用此方法时集合中至少存在一个元素)。每个元素应该有 相同的概率 被返回。你必须实现类的所有函数,并满足每个函数的 平均 时间复杂度为 O(1
分析:
因为题目多了一个随机获取元素。而要随机获取元素,那么只能是在项vector,数组array这类支持随机访问的数据结构上才能实现,但它们无法在insert和remove上做到\(O(1)\),要做到的话只能是在数组末尾才能达到\(O(1)\),而且还必须支持访问是\(O(1)\),要做到这点那么只能依赖哈希建立值与数组索引之间的映射关系
因此借助两个数据结构可完成,用vector<in>hash存储值,unordered_map<int,int>hmap来存储值与数组索引之间的映射关系:
insert:若插入,在hmap中建立值与索引关系remove:我们remove只在数组尾部进行,这样就避免了元素的移动。具体做法就是将hash的尾部元素复制到要删除的元素处,并以此旧的hmap映射关系,建立新的hmap映射关系,然后删除'hash`尾部元素。getRandom:直接在数组大小内取随机值返回即可
1 | class RandomizedSet { |
12 数组类型
数组一类的题目由于其所采用的数据结构为数组,因此其可考察的东西不是固定的,可以说什么方法的题目都可能涉及到数组,因此对于数组,应该多总结归纳,刷多了后,想到数组,出现在脑海的应该由:双指针、滑动窗户、动态规划、深度(递归)、前缀和、前缀差、二分查找、以及一些只针对题目的解法如数学、位运算等等,需要你对数组内的元素以及题目意思有比较深的理解。
12.1 跳跃游戏55
给定一个非负整数数组nums,你最初位于数组的 第一个下标
。
数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67/*
*方法一:
*回溯:dfs(nums,loc),loc为当前位置,step为当前位置的值即nums[loc],超时
*
*方法二:O(n)算法
*发现:如果无法跳出当前可跳区间,那么可以认为无法达到最后一个下标,
举例:比如[3,2,1,0,4],对应下标为[0,1,2,3,4];
*刚开始对于下标0的3我们的可跳区间是下标[1,3];对应数字是[2,1,0];
*在该可跳区间中由于2+1=3;1+2=3;0+3=3,表示下一个可跳区间的最大下标是3,仍在当前的可跳区间,无法出去,
*那么即可认为无法到达最后一个下标
*思路:
* - 先排除一些特殊情况,当数组大小为0或1,必能达到;当数组大小>1,当第一个数就是0不能达到
* - 我们定义beginOfJump和endOfJump,分别表示当前可跳区间的范围。
* - 为了确定下一个区间的最大下标,我们需要遍历[beginOfJump,endofJump]范围的数字,确定下一个区间最大下标nextMaxIndex
* -如果nextMaxIndex>=nums.size()-1,肯定能够到达最后一个下标位置,之间返回true
* - 如果没有到达,且跳不出当前区间,无法到达,返回false
* - 如果没有到达,但能够跳出,进行下一个区间的遍历
*/
class Solution {
public:
/*bool canJump(vector<int>& nums) {
return dfs(nums,0);
}
bool dfs(vector<int>&nums, int loc){
if(loc>=nums.size()-1)
return true;
else if(!nums[loc]&&loc<nums.size()-1)
return false;
for(int i=1;i<=nums[loc];i++)
{
if(dfs(nums,loc+i))
return true;
}
return false;
}*/
bool canJump(vector<int>&nums)
{
if(nums.size()==1)
return true;
if(nums.size()!=1&&nums[0]==0)
return false;
int beginOfJump=1,endOfJump=nums[0];
while(beginOfJump<=nums.size()-1)
{
//遍历该可跳区间能确定的下一个区间范围
int nextMaxIndex=0;
for(int i=beginOfJump;i<=endOfJump;i++)
{
int tmp=i+nums[i];
//若循环中就可达到,直接返回(剪枝)
if(tmp>=nums.size()-1)
return true;
if(tmp>nextMaxIndex)
nextMaxIndex=tmp;
}
//判断是否可跳出该区间,不可则说明不能到达
if(nextMaxIndex<=endOfJump)
return false;
//直接在下一区间判断
beginOfJump=endOfJump+1;
endOfJump=nextMaxIndex;
}
return false;
}
};
12.2 合并区间56
以数组 intervals 表示若干个区间的集合,其中单个区间为
intervals[i] = [starti, endi]
。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。
思路:
- 先对数组
- 然后判断:
- 首先返回数组为空时,只能选择
intervals内的第1和第2个区间比较,若第2区间与第一区间有共同区间,则执行合并操作 - 若返回数组不为空,则先对返回数组的最后一个区间与
intervals当前区间比较,看是否合并,合并的话执行合并操作;不合并则直接插入到返回数组即可
- 首先返回数组为空时,只能选择
- 合并操作:要判断是包含关系还是拼接关系
- 包含关系:即第一区间包含第二区间,则直接是第一区间不变即可
- 拼接关系:第一个区间的结尾替换为第二区间的结尾
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35/*
*排序+遍历
*/
class Solution {
public:
vector<vector<int>> merge(vector<vector<int>>& intervals) {
sort(intervals.begin(),intervals.end());
vector<vector<int>> ret;
for(int i=0;i<intervals.size();i++)
{
vector<int> tmp;
if(!ret.empty()&&(*(ret.end()-1))[1]>=intervals[i][0])
{
if((*(ret.end()-1))[1]<intervals[i][1])
(*(ret.end()-1))[1]=intervals[i][1];
}
else if(i+1<intervals.size()&&intervals[i][1]>=intervals[i+1][0])
{
tmp.push_back(intervals[i][0]);
//拼接关系
if(intervals[i][1]<intervals[i+1][1])
tmp.push_back(intervals[i+1][1]);
//包含关系
else
tmp.push_back(intervals[i][1]);
ret.push_back(tmp);
i++;
}
else{
ret.push_back(intervals[i]);
}
}
return ret;
}
};
12.3 剑指offer45 把数组排成最小的数
输入一个非负整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。
思路:
- 要自定义排序法则,将其排序成组成的数组是最小顺序
- 排序法则:从数组中任取两个数字字符串x和y,若x+y>=y+x,则说明x>=y;若x+y<y+x,则x<y
- 使用快排或者带谓词的内置函数,实现时间复杂度为O(nlogn),最坏情况为O(n*n)
1 | /* |
12.4 剑指offer56-I.数组中数字出现的次数(位运算)
一个整型数组 nums
里除两个数字之外,其他数字都出现了两次。请写程序找出这两个只出现一次的数字。要求时间复杂度是O(n),空间复杂度是O(1)。
思路:有多种解法
解法一:使用排序,时间复杂度为O(nlogn),空间复杂度为O(1)
解法二:使用哈希,时间复杂度为O(n),空间复杂度为O(n)
解法三:其他数字出现了两次,则可说明当数组中只有一个数是出现一次时,数组所有元素异或后,会得到这个只出现一次的数字。此时时间复杂度为O(n),空间复杂度为O(1)
对于解法三:
- 现在是有两个出现一次的数字
x和y,那么得到的结果就是x^y - 现在的重点是如何去划分两个数组使得其
x,y各在这两个数组内x^y肯定存在位为1,表示x和y的不同点,现在我们要找到第一个1位- 我们借助辅助变量
m=1去寻找,没找到m就会左移一位,找到则得到最终的m - 之后用
m与数组内的元素进行相&,如果num&m为真,划分到数组1执行异或,否则划分到数组2执行异或
1 | class Solution { |
- 位运算总结:
- x&1:得到最底位是
0还是1,与右移结合,可统计给定整数二进制形式1的个数 - x^=y:得到无进位的和;检查x和y是否相同
- x&y:与
左移<<结合得到进位
- x&1:得到最底位是
例如:不用加减乘除做加法 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20/* ^ &(进位)
* 1011 11 0 0 0 0 1011 1011 0110 0110 1000 1000 10000 10000
* 0111 7 0 1 1 0 & 0111 ^ 0111 & 1100 ^ 1100 & 1010 1010 & 0010 ^ 0010
*10010 18 1 0 1 0 0011 1100 0100 1010 1000 0010 00000 10010
* 1 1 0 1
*/
class Solution {
public:
int add(int a, int b) {
while(b)
{
//进位
int c=(unsigned int)(a&b)<<1;
//当前
a^=b;
b=c;
}
return a;
}
};
12.5 剑指offer39. 数组中出现次数超过一半的数字
数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。要求时间为O(n),空间为O(1)
- 解法:摩尔投票法,因为数字超过了一办,是大众数,那么可理解成数字不同的双方同归于尽,相同的则一起存活,用count取记录存活数量,res记录存的数字,最后活下来的一定是大众数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23/*
*解法一:排序,此时数字一定出现在中位数,取中位数即可,时间复杂度O(nlogn),空间O(1)
*解法二:哈希,时间复杂度位O(n),空间复杂度位O(n)
*解法三:摩尔投票法,因为数字超过了一办,是大众数,那么可理解成数字不同的双方同归于尽,相同的则一起存活,用count取记录存活数量,res记录存的数字,最后活下来的一定是大众数
*/
class Solution {
public:
int majorityElement(vector<int>& nums) {
int count=0,res;
for(int i(0);i<nums.size();++i)
{
if(count==0)
{
++count;
res=nums[i];
}
else{
res==nums[i]?++count:--count;
}
}
return res;
}
};
12.6 根据身高重建队列
假设有打乱顺序的一群人站成一个队列,数组 people
表示队列中一些人的属性(不一定按顺序)。每个
people[i] = [hi, ki]
表示第i个人的身高为hi ,前面 正好 有
ki 个身高大于或等于hi 的人。
请你重新构造并返回输入数组 people
所表示的队列。返回的队列应该格式化为数组 queue ,其中
queue[j] = [hj, kj] 是队列中第 j
个人的属性(queue[0] 是排在队列前面的人)。
解法1:
思路:从头到尾构造该队列,每次从people中取出适合的人在该位置,适合的人确定算法如下,假设前面已有排好的x个人,x个人中已知最低身高是min,最高身高是max:
-
先对数组按身高排序(剪枝操作,执行一次),这是因为当存在多个位次即people[i][j]满足需求时,个子矮的才是正确人选,这是因为如果个子高的在这个位置,个子矮的在后续位置无法满足,就比如[5,0]和[7,0],若[7,0]在头,无论[5,0]在后面的哪个位置,其位次都不应是0,至少是1。
-
遍历数组,查看当前people[i]中的位次是否满足该位置,如果满足,则这个位置站的就是people[i],否则取一下,反复执行直到满足
-
我们使用map来存储当前位置前出现比map.first高的人的个数
为避免重复,我们将已经拍好序的人升高赋值为-1
上述时间复杂度是O(nlogn)+O(n*n)=O(n*n),排序达到了剪枝效果,因此实际复杂度
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37class Solution {
public:
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
map<int,int> record;
int n=people.size(),m=2;
vector<vector<int>> ret(n,vector<int>(2,0));
//对people按h排序
sort(people.begin(),people.end());
for(int i=0;i<n;++i)
record.insert({people[i][0],0});
int x=0;
while(x<n){
int i=0;
for(;i<n;++i){
//该people已经排序
if(people[i][0]==-1) continue;
//判断该people是否符合条件
if(people[i][1]==record[people[i][0]]) break;
}
//ret插入
ret[x][0]=people[i][0];
ret[x][1]=people[i][1];
//people标记已排序
people[i][0]=-1;
//更新record
auto End = record.find(ret[x][0]);
auto it = record.begin();
while (it != End) {
++(it->second);
++it;
}
++(End->second);
++x;
}
return ret;
}
};
解法二(该题想要讲述的解法):数对分别不同规则排序+插入
思路:我们发现当我们对升高按低到高排序,,低身高的插入操作不会对高身高的人产生任何影响;反而高身高的人若插入在低身高的前面就会对低身高的产生影响。我们设人数为n,在进行排序后,它们的身高依次为\(h_0、h_1...h_n\)。如果我们按照排完序后的顺序,依次将每个人放入队列中,那么当我们放入第i个人时:
- 第\(1,...,i-1\)个人已经在队列中被安排了位置,并且他们无论站在哪里,对第\(i\)个人没有任何影响。
- 而\(i+1,...,n\)个人还没有插入,但他们只要站在第
i个人前面,就会对第i个人产生影响。
因此对于第二种情况,我们需要为这种插入留空,我们根据people[i][1]决定留空多少个。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32/*
比如:[[7,0],[4,4],[7,1],[5,0],[6,1],[5,2]]
排序:身高低到高,ki由高到低排序,得[[4,4],[5,2],[5,0],[6,1],[7,1],[7,0]]
插入:_ _ _ _ [4,4] _
_ _ [5,2] _ [4,4] _
[5,0] _ [5,2] _ [4,4] _
[5,0] _ [5,2] [6,1] [4,4] _
[5,0] _ [5,2] [6,1] [4,4] [7,1]
[5,0] [7,0] [5,2] [6,1] [4,4] [7,1]
*/
class Solution {
public:
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
sort(people.begin(),people.end(),[](vector<int>& u,vector<int>& v){
return u[0]<v[0]||(u[0]==v[0]&&u[1]>v[1]);});
int n=people.size();
vector<vector<int>> ret(n);
for(int i=0;i<n;++i){
int count=0,index=-1;
int k=people[i][1];
for(int j=0;j<n&&count<=k;j++){
if(ret[j].empty()) ++count;
++index;
}
vector<int> temp{people[i][0],people[i][1]};
ret[index]=temp;
}
return ret;
}
};
总结:一般这种数对,还涉及排序的,根据第一个元素正向排序,根据第二个元素反向排序,或者根据第一个元素反向排序,根据第二个元素正向排序,往往能够简化解题过程。
12.7 除自身以外数组的乘积
题目: 给你一个整数数组
nums,返回 数组answer,其中answer[i]等于nums中除nums[i]之外其余各元素的乘积 。
题目数据 保证 数组
nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。
请不要使用除法,且在 O(n) 时间复杂度内完成此题。
思路:类比于前后缀和和前后缀差,这里可以使用前缀乘积和后缀乘积解决该问题,定义l[i]和r[i],
l[i]表示在nums[i]左边的所有元素乘积r[i]表述nums[i]右边的所有元素乘积- 那么利润
l[i]和r[i]就能得出multi[i]=l[i]*r[i]
算法的时间复杂度为\(O(n)\),空间复杂度为\(O(N)\)
1 | * |
12.8
13 分治和二分
分治和二分法可以说是O(logn)时间复杂度的代名词,因此学会分治和二分法是必须的。运用分治的诸如归并排序、二分法如二分查找和查找第k大数字
### 13.1 寻找两个正序数组的中位数
给定两个大小分别为m和n的正序(从小到大)数组 nums1和 nums2。请你找出并返回这两个正序数组的
中位数 。
算法的时间复杂度应该为O(log (m+n))。
解题思路:题目要求时间复杂度为O(log (m+n)),那么必然是使用二分法
二分法:
使用类似于二分法的操作,计算出nums1和nums2的长度和m+n,那么可以肯定,当为奇数时,中位数所在位置为(m+n)/2;当偶数时中位数所在位置为(m+n)/2与(m+n)/2-1的均值;因此计算出k=(m+n)/2,表示第K大的数,当为奇数时,即得到第k+1大的数字即可;当为偶数是,得到第k大和k+1大数字的和平均
我们可以通过一下适用于两个数组的二分法实现,构造一个新的辅助函数,该函数功能为得到第k大的数字
- 首先定义出起始位置
start1和start2 - 由于
m=k>>1情况对某一数组而言存在越界情况,因此需取min(len,start+m)的较小值,由于数组下标从0开始,需-1,后得到index1、index2 - 比较
nums1[index1]与nums[index2]的大小- 当
nums1[index1]>=nums2[index2],那么就说明可以去除nums2数组中[0,k/2]范围的数字,更新k值和数组nums1的起始位置start1 - 当
nums1[index1]<nums2[index2],那么就说明可以去除nums1中的[0,k/2],更新k值和start2
- 当
- 退出条件:
- 当某一数组遍历完后,那么可知第k大数组必定在另一个数组,且
k\start更新过,可以直接返回nums[start+k-1] - 当
k==1,返回min(nums1[start1],nums2[start2])
- 当某一数组遍历完后,那么可知第k大数组必定在另一个数组,且
1 | class Solution { |
13.2 数组中的第K个最大元素
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。
思路:我们知道快速排序是以分治的思想来降低复杂度,其算法流程是
- 分解:将数组\(a[l...r]\)划分成两个子数组\(a[l...q-1]、a[q+1...r]\),使得\(a[l...q-1]\)中的元素小于等于\(a[q]\),且\(a[q]\)小于等于\(a[q+1...r]\)中的每一个元素。其中,计算下标q也是划分过程的一部分
- 解决:通过递归调用快速排序,对于数组\(a[l...q-1]、a[q+1...r]\)进行排序
- 合并:因为子数组都是原址排序的,所以不需要进行合并操作,\(a[l...r]\)已经有序
- 上文中提到的 「划分」 过程是:从子数组\(a[l...r]\)中选择任意一个元素 \(x\) 作为主元,调整子数组的元素使得左边的元素都小于等于它,右边的元素都大于等于它, \(x\) 的最终位置就是 \(q\)
可以发现每次划分后都会确定一个元素在数组中的位置,因此对于第k个最大元素,我们只需要关注该位置即可,对于区间有序性并不在乎。为避免最坏的时间复杂度,使用随机法取基准点,随机法能够避免最坏复杂度,
算法步骤:
- 利用快速排序的方法,只确定数组中的第K个最大的元素。
- 为避免最坏情况,使用随机法规范
1 | class Solution { |
14 并查集
14.1 等式方程的满足性
给定一个由表示变量之间关系的字符串方程组成的数组,每个字符串方程
equations[i]
的长度为4,并采用两种不同的形式之一:"a==b" 或
"a!=b"。在这里,a 和 b
是小写字母(不一定不同),表示单字母变量名。
只有当可以将整数分配给变量名,以便满足所有给定的方程时才返回true,否则返回
false。
分析
分析题目可知,可组等式方程或有关系或无关系,那么因此对所有的方程进行管理,该背景下可考虑使用并查集解决:
1 | lass UnionFind { |
以上题目均来自leetcode 题目来源:leetcode

