1.STL概述
1.1 六大组件
- 容器:各种数据结构,如
vector、list、deque、set、map等,用来存放数据 - 算法:各种常用的算法(冒泡,排序),如
sort、find、copy、for_each、search、erase - 迭代器:扮演了容器与算法之间的胶合剂,是所谓的泛型指针
- 仿函数:行为类似函数,可作为算法的某种策略
- 适配器:一种用来修饰容器或者仿函数或迭代器接口的东西
- 空间配置器:负责空间的配置与管理。注意一般都伴随着重新分配空间,那么原来的迭代器就会失效
六大组件的交互关系是Container通过Allocator获得数据存储空间,Alogrithm通过Iterator存取Container的内容,Functor可以协助Algorithm完成不同的策略变化,Adapter可以修饰或套接Functor。本笔记将会以此对这六大组件进行介绍。
++说在前面:STL的实现版本由HP版本、PJ版本、RW版本、STLport版本和SGISTL版本等五个主要版本++
2. 空间配置器
在介绍STL的其他组件尤其是container组件之前,空间配置器是必须要先介绍的,因为容器内存空间的开辟需要由allocator去申请。allocator申请的空间是为构造原始的,new申请的空间是已构造的。在gcc中的容器使用了缺省的SGI版本的空间配置器:class Alloc = alloc
1
2
3
4template <class T, **class Alloc = alloc**> //默认使用了alloc
class vector {
/*...实现*/
}
2.1 空间配置器的标准接口
allocator的必要接口(无论是哪个版本的STL): 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25//成员变量
allocator::value_type;
allocator::pointer;
allocator::const_pointer;
allocator::reference;
allocator::const_reference;
allocator::size_type;
allocator::difference_type;
allocator::rbind;
//构造函数
allocator::allocator();
allocator::allocator(const allocator&);
template<class U>allocator::allocator(const allocator<U>&);
//析构
allocator::~allocator();
//返回某个对象的地址,等同于&X
pointer allocator::address(reference x)const;
//配置空间,n个足以存储U对象
pointer allocator::allocate(size_type n,const void*=0);
//回收配置的空间,p为allocate返回的指针,n为allocate分配是指定的大小
void allocator::deallocate(pointer p,size_type n);
//对分配空间进行构造
void allocator::construct(pointer,const T&x);
//对构造空间析构
void allocator::destroy(pointer p);
2.1.1设计一个简单的空间配置器
根据上述的接口,我们可以实现一个自己的、功能简单,接口不齐全的allocator。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
template<class T>
//分配空间
namespace myallocator
{
inline T* _allocate()(ptrdiff_t size,T*)
{
set_new_handler(0);
//使用全局operator new ,相当于malloc
T* tmp=(T*)(::operator new((size_t)(size*sizeof(T)))); //调用全局重载运算符new
if(tmp==0)
{
cerr<<"out_of_memory"<<endl;
exit(1);
}
return tmp;
}
//释放
template<class T>
inline void _deallocate(T*buffer)
{
//相当于free
::operator delete(buffer);
}
//构造
template<class T,class U>
inline void _construct(T* p,const U& value)
{
new(p) U(value); //placement new,相当于realloc,并进行构造
}
/析构
template<class>
inline void _destroy(T* ptr)
{
ptr->~T();
}
template<class T>
class allocator{
public:
typedef T value_type;
typedef T* pointer;
typedef const T* const_pointer;
typedef T& reference;
typedef const T& const_reference;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
//内嵌体
template<class U>
struct rebind{
typedef allocator<U> other;
}
//函数
pointer allocate(size_type n,const void* hint=0)
{
return _allocate((difference_type)n,(pointer)hint);
}
void deallocte(pointer p,size_type n)
{
_deallocate(p);
}
void construct(pointer p,const T& value)
{
_constrcut(p,value);
}
void destroy(pointer p)
{
_destroy(p);
}
}
} //end of namespace myallocator
2.2 SGI空间配置器
SGI版本的空间配置器与众不同,其名称是alloc而不是allocator。alloc不接受任何参数,即如果你的程序要采用SGI版本的配置器,则不能使用标准写法:
1
vector<int,std::allocator<int>> iv;
1
vector<int,std::alloc> iv;
GCC中是使用缺省的空间配置器,我们可以不用显示的去指定,编译器默认采用SGI的这个版本。
附:虽然SGI也提供了一个aloocator版本,但是不建议使用,因为效率不佳,因为它只是对::operator new和::operator delete做一个简单包装而已
2.3 SGI的alloc
我们知道new算式包含两个步骤:一是调用::operator new配置内存;二是调用相应的构造函数构造对象内容。同样delete算式也包含两个步骤:一是调用对象的析构函数析构;二是调用::operator delete释放内存
为了精密加工和效率的提升,STL的allocator把这两步操作区分开来,内存配置操作由alloc::allocate()负责,内存释放由alloc::deallocate()负责;而对象的构造和析构分别是由::construct()和::destroy()负责。STL的标准中规定配置器的定义位于<memory>中,对SGI版本来说<memory>内含有关键的两个文件,这两个文件实行上面的工作划分规则
1
2<stl_alloc.h>中定义了一、二级配置器,而在<stl_construct.h>定义了construct()和destroy()函数。
2.4 alloc的stl_constuct
在<stl_construct.h>定义了多个重载的construct()和destroy()函数。这里介绍接受两个迭代器版本的destroy()
1
2
3
4
5template <class ForwardIterator>
inline void destroy(ForwardIterator first, ForwardIterator lasu)
{
_destroy(first,last,value_type(first));
}[first,last)范围内对象,如果是调用一些无关痛痒得析构函数,又万一这个范围很大的话效率会极低。因此_destroy()利用value_type()获得迭代器对象所指代得类型,在_destroy内部利用_type_traits<T>判断该类型得析构是否对内存空间无关痛痒,若是_true_type,则什么也不做就结束,若是_false_type则只能迭代去析构这个范围得对象。
2.5 空间配置stl_alloc
SGI内部是以malloc()和free()完成内存得配置与释放得。考虑到小型区块可能造成内存碎片得问题,SGI设计了双层配置器,第一级直接使用molloc()和free(),第二级则看情况采用不同策略分配:
- 当配置区块超过
128bytes时,视为足够大,直接调用第一级得配置器 - 当配置区块小于
128bytes时,视为小,便采用复杂的memory pool和自由链表管理配置
内存池memory pool:内存池是在真正使用内存之前,先申请分配一定数量的、大小相等(一般情况下)的内存块留作备用。当有新的内存需求时,就从内存池中分出一部分内存块,若内存块不够再继续申请新的内存。这样,内存池允许在运行期以常数时间规划内存块,并且尽量避免了内存破碎的情况产生,使得内存分配的效率得到提升。
注意:是只开放一级配置器还是同时开放二级,由_USE_MALLOC是否被定义而定,当被定义是,只开放第一级配置器,当未背定义时两级都开放。
2.5.1 一级配置器
一级配置器是类名为template<int inst>class _malloc_alloc_template{...}的一个类,在allocate()内直接使用malloc(),在deallocate()直接使用free()。同时模拟set_new_handler()来处理内存不足的情况。奉上源码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48template<int inst>
class _malloc_alloc_template{
private:
//以下函数用来处理内存不足的情况
static void *oom_malloc(size_t);
static void *oom_realloc(void*,size_t);
static void (*_malloc_alloc_oom_handler)(); //函数指针
public:
//allocate分配
static void* allocate(size_t n){
void *result=malloc(n); //直接使用malloc分配
if(0==result)
result=oom_malloc(n); //不断尝试
}
//释放
static void deallocate(void* p,size_t n);
{
free(p);
}
//模拟set_new_hanlder,返回函数指针
static void(* set_malloc_hanlder(void(*f)()))()
{
void (*old)=_malloc_alloc_oom_handler;
//设置
_malloc_alloc_oom_handler=f;
return (old);
}
};
//函数为纯虚函数,需要自己编写处理函数来不断尝试释放内存、申请内存
void (* _malloc_alloc_template<inst>::_malloc_alloc_oom_handler)()=0;
//malloc形式的不断尝试
void *_malloc_alloc_template<inst>::oom_malloc(size_t n){
void (*my_malloc_hanlder)(); //函数指针
void *result;
for(;;)
{//不断尝试释放,配置
my_malloc_hanlder=_malloc_alloc_oom_handler;
if(0==my_malloc_handler)
_ThROW_BAD_ALLOC;
(*my_malloc_handler)();//调用释放
//进行分配
result=malloc(n);
//分配成功直接返回
if(result)
return(result);
}
}
查看上述的部分源代码可以知道
- 第一级空间分配器以
malloc()、free()、realloc()等C函数执行内存配置,而不是采用C++的::operator new,因此无法使用C++的new hanlder机制,也就不能使用set_new_hanlder(),必须仿真一个类似该功能的set_malloc_handler() allocate()分配不成功后会改调用oom_malloc()不断尝试去释放分配,其中的_malloc_alloc_oom_hanlder()函数是要自己去编写指定的。如果你没有传入该函数,源码也未提供,默认为纯虚函数,则进入到oom_hanlder()判断后直接抛异常。
2.5.2 附加知识点:new handler机制
new_handler是一个void*类型的函数指针 1
2
3
4
5namespace std {
typedef void (*new_handler)(); //函数指针,只是起个名字new_handler=void*
//new_handler是一个typedef后void*
new_handler set_new_handler(new_handler p) throw();
}
new_handler类型内的函数将在默认内存申请函数operator new和operator new[]申请内存失败时被调用;- 默认情况下, 当内存不能够分配时,
new操作将抛出一个bad_alloc的异常。 你可以改变这个默认操作, 通过set_new_handler()设置new_handler内的函数指针。当然 你可以使用set_new_handler(0), 获得一个不抛出异常的new.
用户定义的my_handler应该可以做以下几件事之一:
- 释放内存, 产生更多可以用的内存
- 抛出bad_alloc异常(或bad_alloc派生类)
- 终止程序(比如调用abort或exit)
2.5.3 二级配置器
二级配置器类名为template<bool threads,int ints>class _default_alloc_template{...}:维护16个自由链表,负责16种小型区块内存池的次配置能力,内存池memory pool事先由malloc配置而得。为了方便管理,SGI的二级配置会主动将小额的内存需求上调至8的倍数,例如我们要求分配30bytes,那么二级配置器就会分配维护多个32bytes的内存块。第二级配置器多了许多机制,以避免太多的小额区块造成内存碎片,从而避免内存浪费和减轻配置负担,第二级配置的做法是:
- 当配置区块超过
128bytes时,视为足够大,直接调用第一级得配置器 - 当配置区块小于
128bytes时,视为小,便采用复杂的memory pool管理配置,又称为次层配置。
memory pool的想法是:预先配置一大块内存,一般来书为需求的2倍,并维护与之对应的自由链表free list。下次若有对应大小的内存需求,则直接从该链表拔出给它就行;如果客户端释还从该内存池种拔出的一部分内存,则由配置器回收到该内存池中。
1
2
3
4
5//free list的节点结构如下所示:节点使用union而不是struct,从而达到节省内存开销的目的。
union obj{
union obj* free_list_link; //未被使用时,由次指针维护
char client_data[1]; //当内存被使用时,软件开发者使用这个,执行实际区块
};free list是chunk_alloc()函数得工作。
- 如
chunk_alloc(32,20)会根据end_free-start_free来判断内存池得水量是否充足,如果水量充足,则直接调出20个相应大小的内存区块给free_list;如果不充足则调用malloc分配至少40个32bytes的内存块,一个直接给客户端,19个给free_list维护,另外的给内存池 - 如果不够20个但至少能满足一个32bytes的内存块,也会拨出至少一个;
- 如果连一个区块都拨不出去,此时便会利用
malloc从heap上配置内存,从内存中为内存池注入水源以应付需求,一般来说申请的内存是需求量的2倍。
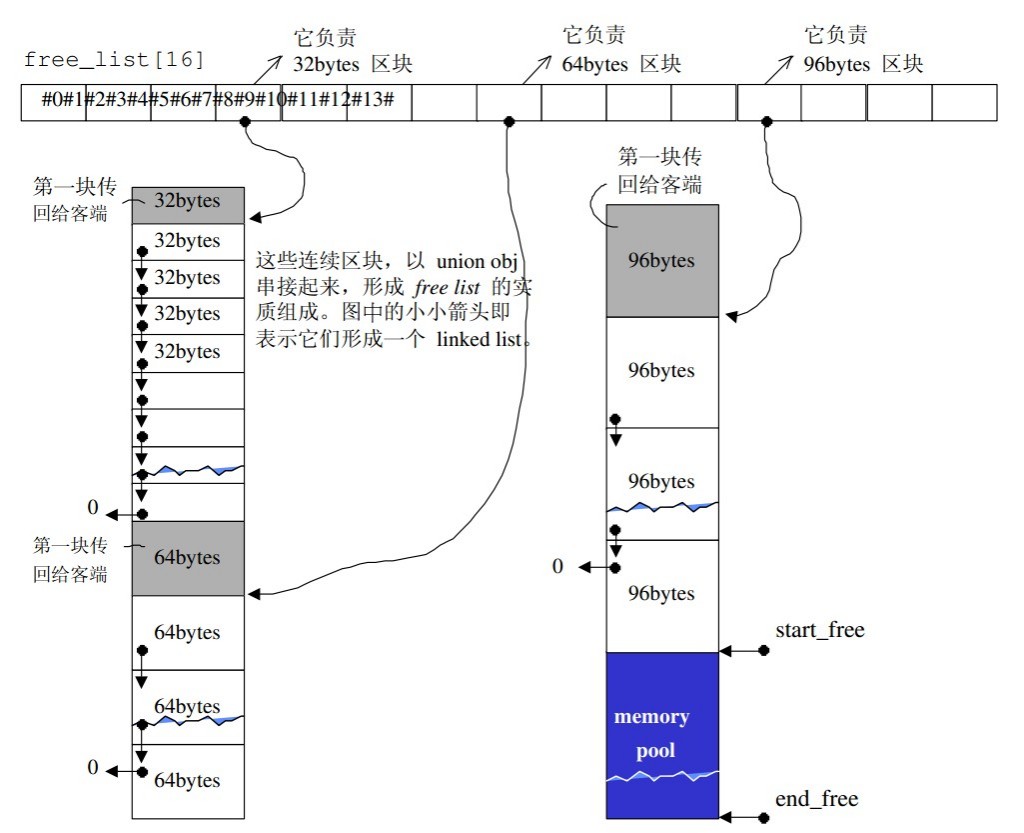
如上图:
- 假设程序一开始就调用
chunk_alloc(32,20),那么malloc就会配置40个32bytes的区块,其中第一个交出,另外19个交给free_list[3]维护,剩余20个交给内存池。 - 接下来客户端再调用
chunk_alloc(64,20),此时很明显free_list[7]没有内存,必须向内存池请求支持,但内存池也只够10个64bytes的区块,那么就会交付这10,一个直接给客户端,另外9个由free_list[7]维护。此时内存池已经空了, - 如果再调用
chunk_alloc(96,20),不仅free_list[11]没有内存,就连内存池也没有,那么就会调用malloc配置40+n个96bytes区块,其中第一个给客户端,19个给free_list[11],另外的给内存池。 - 如果
malloc()也无法分配内存,就会使用第一级配置,不断尝试去释放获取。
3. 迭代器与traits编程技法
iterator是指提供一种方法,使之能够依序巡防某个容器所含的各个元素,而又无需暴露该容器的内部表达式。STL通过泛型化将数据容器和算法分开,采用iterator将两者粘合起来,以find为例:
1
2
3
4
5
6
7template<class InputIterator,class T>
InputIterator find(InputIterator first,InputIterator last,const T& value)
{
while(first!=last&&*first!=value)
++first;
return first;
}operator *、operator->、operator++进行重载
3.1 traits编程技法-STL源码的门钥
3.1.1 为什么要使用traits编程技法
迭代器一般都为模板,其所指对象的的型别,称为该迭代器的value type。模板函数虽然带有参数类型的推导,但却不是万能的:万一value type用于函数的反回值,毕竟template的参数推导机制只是适用于参数,无法推导返回值。我们可能可以在类内定义内嵌型别来解决,也可以使用C++11的的尾置返回类型remove_reference<decltype(beg*)>::type
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18//内嵌类型声明
template<class T>
struct myiter{
typedef T value_type; //内嵌型别声明
....
};
template<class I>
typename I::value_type func(I iter)
{
return *iter;
}
//尾置返回类型
//此例中我们通知编译器fcn2的返回类型与解引用beg的参数的结果类型相同
template<class T>
auto fcn2(T beg,T end)->typename remove_reference<decltype(*beg)>::type
{
return *beg;
}traits的偏特例化编程。(像int*,double*内置类型或者自动定义的类的指针就是原生指针)
3.1.2 traits和偏特例化
traits单词只是说明这个类能萃取到迭代器的特性,只是一个名字的作用,告诉编程人员注意对于这种类内部会对传入的参数进行取value type操作,说实在就是STL当中的规范协议。如下:
1
2
3
4
5
6
7
8
9
10template<class I>
struct iterator_traits{
typedef typename I::value_type value_type;
}
template<class I>
typename itrator_traits<I>::value_type(I iter)
{
return *iter;
}value type,那么就会在iterator_traits这种类内部有取value type操作。这里跟我们上面提到的内嵌型别说明是一样的。上面这个类只是起到中间转换的作用,这就traits的特定。
然后我们在去实现iterator_traits的一个特例化版本即传入指针形式的偏特化版本就能取得指针的类型
1
2
3
4
5
6
7
8
9
10//这里的机制是当我们传入T*=int*时,因为int内有定义value_type那么就肯定能获得其类型
template<class T>
struct iterator_traits<T*>{
typedef T value_type;
}
template<class T>
struct iterator_traits<const T*>
{
typedef T value_type;
}I的类型,而不是const+类型,试想当没有const版本,调用iterator_traits<const
int*>会获取到const int而不是int。三个版本都是需要的,后面两个版本为解决原生指针无法获取类型而采用(应用偏特例化)
总结:
- 实现原生指针也能推导返回值类型就是要
traits编程技法 traits不是什么C++内部关键字,它只是对STL源码编写的一个规范traits编程技法主要应用于迭代器实现,迭代器就是行为像指针的类,保证我们在使用迭代器类的operator*后能返回迭代器所指的元素traits编程技法的实现原理就是对类模板的偏特例化(上面的二个篇特例化模板)
3.2 迭代器相应型别
更加迭代器使用operator*时所返回的类别,一般有value type,difference type,pointer,reference,itrator category这五种。因此我们在对traits类进行typedef时都应当指定,以便符号STL规范,即使自己编写的迭代器类也能与STL水乳交融。
1
2
3
4
5
6
7
8template<class T>
struct iterator_traits<T*>{
typedef typename T::iterator_category iterator_category;
typedef typename T::value_type value_type;
typedef typename T::difference_type difference_type;
typedef typename T::pointer pointer;
typedef typename T::reference reference;
}
3.2.1 value_type
value_type就是迭代器所指对象的型别,任何一个打算与STL算法有完美搭配的class,都应当定义自己的value_type内嵌型别。
3.2.2 difference_type
difference_type用来表示两个迭代器的距离,因此也可以用来表示一个容器的最大容量。比如STL的count算法统计指定值出现次数:
1
2
3
4
5
6
7
8
9template<class I,class T>
typename iterator_traits<I*>::difference_type
count(I fist,I last,const T& value){
typename iterator_traits<I*>::difference_type n=0;
for(;first!=last;++first)
if(*first==value)
++n;
return n;
}
3.2.3 reference
reference_type即我们熟知的C++当中的左值引用,这个类型允许我们通过迭代器来对容器内的元素做出改变。
3.2.4 pointer
pointer是指指针,传回一个指针表示我们也可以通过迭代器对容器内的元素做改变。
1
2
3
4
5
6template<class T>
struct iterator_traits<T*>{
...
typedef T* pointer;
typedef T& reference;
}
3.2.5 iterator_category
这个型别是迭代器的类型型名,必须指定迭代器的分类如下:
 我们在设计算法的时候,必须针对上图的某种迭代器提供一明确定义,比如有一个算法明确使用
我们在设计算法的时候,必须针对上图的某种迭代器提供一明确定义,比如有一个算法明确使用ForwardIterator,那就应当明确传递这种迭代器,虽然传递RandomAccessIterator和BidirectionalIterator也可以,但效率并不是最佳。
3.3.iterator源代码展示
下面的源代码选自SGI版本的STL<stl_iterator.h>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
//五种迭代器,作为标记型别(tag types),不需要任何成员
struct input_iterator_tag{};
struct output_iteratoe_tag{};
struct forward_iterator_tag : public input_iterator_tag{};
struct bidirectional_iterator_tag : public forward_iterator_tag{};
struct random_access_iterator_tag : public bidirectional_iterator_tag{};
//为避免写代码时挂一漏万,自行开发的迭代器最好继承自下面这个 std::iterator
template<class Category,class T,class Distance=ptrdiff_t,
class Pointer=T*,class Reference=T&>
struct iterator
{
typedef Category iterator_category;
typedef T value_type;
typedef Distance difference_type;
typedef Pointer pointer;
typedef Reference reference;
};
//五种迭代器
template<class T,class Distance>
struct input_iterator
{
typedef input_iterator_tag iterator_category;
typedef T value_type;
typedef Distance difference_type;
typedef T* pointer;
typedef T& reference;
};
template<class T,class Distance>
struct output_iterator
{
typedef output_iterator_tag iterator_category;
typedef void value_type;
typedef void difference_type;
typedef void pointer;
typedef void reference;
};
template<class T,class Distance>
struct forward_iterator
{
typedef forward_iterator_tag iterator_category;
typedef T value_type;
typedef Distance difference_type;
typedef T* pointer;
typedef T& reference;
};
template<class T,class Distance>
struct bidirectional_iterator
{
typedef bidirectional_iterator_tag iterator_category;
typedef T value_type;
typedef Distance difference_type;
typedef T* pointer;
typedef T& reference;
};
template<class T,class Distance>
struct random_access_iterator
{
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef Distance difference_type;
typedef T* pointer;
typedef T& reference;
};
//"榨汁机"traits
template<class Iterator>
struct iterator_traits
{
typedef typename Iterator::iterator_category iterator_category;
typedef typename Iterator::value_type value_type;
typedef typename Iterator::difference_type difference_type;
typedef typename Iterator::pointer pointer;
typedef typename Iterator::reference reference;
}
//针对原生指针(naive pointer)而设计的traits偏特性化版本
template<class T>
struct iterator_traits<T*>
{
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef ptrdiff_t difference_type;
typedef T* pointer;
typedef T& reference;
};
//针对Pointer-to-const而设计的traits偏特化版本
template<class T>
struct iterator_traits<const T*>
{
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef ptrdiff_t difference_type;
typedef const T* pointer;
typedef const T reference;
};
//判断某迭代器iterator的类型
template<class Iterator>
inline typename iterator_traits<Iterator>::iterator_category
iterator_category(const Iterator& It)
{
typedef typename iterator_traits<Iterator>::iterator_category
return category();
}
//获取迭代器的value_type
template<class Iterator>
inline typename iterator_traits<Iterator>::value_type*
value_type(const Iterator& It)
{
return static_cast<typename iterator_traits<Iterator>::value_type*>(0);
}
//获取迭代器的distance_type
template<class Iterator>
inline typename iterator_traits<Iterator>::difference_type*
distance_type(const Iterator& It)
{
return static_cast<typename iterator_traits<Iterator>::difference_type*>(0);
}
//........................整组advance函数............................................
/*函数重载,使迭代器能在编译时期就确定调用哪个函数*/
template <class _InputIter, class _Distance>
/*迭代器类型为input_iterator_tag的函数定义*/
inline void __advance(_InputIter& __i, _Distance __n, input_iterator_tag)
{
while (__n--) ++__i;
}
template <class _BidirectionalIterator, class _Distance>
/*迭代器类型为bidirectional_iterator_tag的函数定义*/
inline void __advance(_BidirectionalIterator& __i, _Distance __n,
bidirectional_iterator_tag)
{
__STL_REQUIRES(_BidirectionalIterator, _BidirectionalIterator);
if (__n >= 0)
while (__n--) ++__i;
else
while (__n++) --__i;
}
template <class _RandomAccessIterator, class _Distance>
/*迭代器类型为random_access_iterator_tag的函数定义*/
inline void __advance(_RandomAccessIterator& __i, _Distance __n,
random_access_iterator_tag)
{
__STL_REQUIRES(_RandomAccessIterator, _RandomAccessIterator);
__i += __n;
}
template <class _InputIterator, class _Distance>
/*决定调用哪个函数,这是一个对外接口*/
inline void advance(_InputIterator& __i, _Distance __n) {
__STL_REQUIRES(_InputIterator, _InputIterator);
__advance(__i, __n, iterator_category(__i));
}
//............................整组distance函数........................................
template<class InputIterator>
inline typename std::iterator_traits<InputIterator>::difference_type
distance(InputIterator first, InputIterator last)
{
return __distance(first, last,
std::iterator_traits<InputIterator>::iterator_category());
}
template<class InputIterator>
inline typename std::iterator_traits<InputIterator>::difference_type
_distance(InputIterator first,InpuetIterator,input_iterator_tag)
{
iterator_traits<InputIterator>::difference_type n=0;
while(first != last){
++first;
++n;
}
return n;
}
template<class InputIterator>
inline typename std::iterator_traits<InputIterator>::difference_type
__distance(InputIterator first, InputIterator last,
std::random_access_iterator_tag)
{
return last - first;
}
上面的advan函数如果不加第三个参数,因为型别都未定,是实打实的template,不是重载函数,如下:
1
2
3
4
5
6
7
8template <class InputIterator, class _Distance>
inline void advance_II(InputIterator& __i, _Distance __n);
template <class BidirectinalIterator, class _Distance>
inline void advance_BI(BidirectinalIterator& __i, _Distance __n);
template <class RandomAccessIterator, class _Distance>
inline void advance_RI(RandomAccessIterator& __i, _Distance __n);
当我们调用的时候,如果选错使用advance_II来进行advance_RI的工作内容,则原本的O(1)时间复杂度就变成了O(n),因此在源码中通过增加五个结构体,来给这些函数增加第三个确定的参数形成重载机制,在编译时能够使用重载确定调用哪一个版本,容错率高。distance函数也是这样的思想。这是一个值得借鉴的模板编写方式!
4. 序列式容器
序列式容器当中的元素都可序,但未必一定有序,全看编程者的操作。C++语言本身带有array,STL提供vector、list、deque、stack、queue、priority_queue等序列容器。由于stack\queue只是将deque改头换面而成,技术上被归为配接器。
4.1 vector
在vector中最关键的在于器对大小的控制以及重新配置时数据的移动效率。这些在后面会介绍到,这里我们先对vector的源码进行简单介绍:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22template<class T,class Alloc=alloc>
class vector{
public:
typedef T value_type;
typedef value_type* iterator; //这个说明了迭代器就是普通指针
typedef value_type* pointer;
typedef value_type& reference;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
protected:
//Simple_alloc时SGI STL的空间配置器,
//虽然vector使用了缺省的配置器,但Simple_alloc更方便以元素大小为配置单元
typedef Simple_alloc<value_type,Alloc>data_allocator;
iterator start; //表示目前使用空间的头
iterator finissh; //表示目前使用空间的尾
iterator end_of_storage; //表示目前可用空间的尾
void insert_aux(iterator position,const T&x);
...
public:
...//一些操作接口
}vector维护的一个连续空间,所有不论元素型别为哪一种,普通指针都可以作为vector的迭代器而满足所有必要条件,因为像operator*,->,++,--,+,-,+=,-+这些操作,普通的指针天生就具备。也就是说普通指针就是RandomAccessIterator,支持随机存取。
4.1.1 扩容机制
在不同的STL版本中,vector的扩容策略不相同,msvc编译器每次是以1.5倍且向下取整的策略进行扩容,gcc编译器则是SGI版本,每次以2.0倍的策略进行扩容。下图时MSVC中的扩容机制
1
2
3
4
5
6
7//MSVC
vector<int> vec;
int n = 34;
while (n--) {
vec.push_back(n);
cout <<"size:" << vec.size() <<" capacity:" << vec.capacity() << endl;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34size:1 capacity:1
size:2 capacity:2
size:3 capacity:3
size:4 capacity:4
size:5 capacity:6
size:6 capacity:6
size:7 capacity:9
size:8 capacity:9
size:9 capacity:9
size:10 capacity:13
size:11 capacity:13
size:12 capacity:13
size:13 capacity:13
size:14 capacity:19
size:15 capacity:19
size:16 capacity:19
size:17 capacity:19
size:18 capacity:19
size:19 capacity:19
size:20 capacity:28
size:21 capacity:28
size:22 capacity:28
size:23 capacity:28
size:24 capacity:28
size:25 capacity:28
size:26 capacity:28
size:27 capacity:28
size:28 capacity:28
size:29 capacity:42
size:30 capacity:42
size:31 capacity:42
size:32 capacity:42
size:33 capacity:42
size:34 capacity:42
所谓的动态增加,并不是在原空间之后接续新空间,因为无法保证原空间之后尚有可供配置的空间,二是以原来的2倍或1.5倍另外配置一块较大空间,然后将内容拷贝过来,然后才在原内容之后构造新元素,并释放原空间。因此对vector的任何操作若会影响到空间重新配置,指向vector的所有迭代器就都失效了。
4.2 list
相较于vector的连续线性空间,list就比较复杂,它的好处就是每次插入或删除元素,才配置或释放一个元素空间。list是一个双向链表,它不再能够像vector一样以普通指针作为迭代器,因为其节点不保证再空间中连续存在,list迭代器必须有能指向list的节点,并有能力进行正确的递增、递减、取值、成员存取等操作。
4.2.1 list的迭代器
list的迭代器的要求:
- 迭代器必须具备前移、后移的能力,因此对
list提供的是BidirectinalIterator - 与vector不同,不论是何时的插入操作和删除操作、接合操作都不会造成原因的
list迭代器失效
1 | template<class T,class Ref,class Ptr> |
4.2.2 list的数据结构
list是一个双向环形链表,所有它只需要一个指针
1
2
3
4
5
6
7
8
9
10template<class T,class Alloc=alloc>
class list{
protected:
typedef _list_node<T> list_node;
public:
typedef list_node* link_type;
protected:
link_type node; //只需一个指针
...
}
4.3 deque
deque是一种双向开口的连续线性空间,即指能在头尾两端都支持元素的插入和删除

vector虽然也能支持在头尾两端进行操作,但是效率奇差,无法接受,因为在头部的插入导致后面所有元素都要后移。而deque则不会:
duque允许时间复杂度O(1)对其头端进行元素的插入和移除,vector为O(n)deque没有所谓的容量概念,因为它是动态地以连续空间组合而成,随时可以增加一段新的空间并链接起来,即不会发生如vector那样的空间重新配置机制- 虽然
deque也提供RandomAccessIterator,但它的迭代器并不是普通指针,其复杂度和vector不可同道里计,因此除非必要我们应该尽量选择vector而不是deque。 - 在对
deque进行排序操作,为了最高效率,可将deque先完整复制到一个vector身上,将vector排序后再复制会deque
4.3.1 deque的中控器
deque是逻辑上是连续空间。deque系由一段一段的定量空间组成,一旦必要在deque的前端或尾增加空间,便配置一段定量连续空间,串接在整个deque的头端或尾端。因此对于deque容器来说必须维护其整体连续的假象,并提供随机存取接口,那么必须有中央控制器和复杂的迭代架构去实现。
Deque采取一块所谓的map(注意,不是STL的map容器)作为主控,这里所谓的map是一小块连续的内存空间,其中每一个元素(此处成为一个结点node)都是一个指针,指向另一段连续性内存空间,称作缓冲区。缓冲区才是deque的存储空间的主体。SGI STL允许我们指定缓冲区大小,默认使用512bytes(map其实就是二重指针T**)
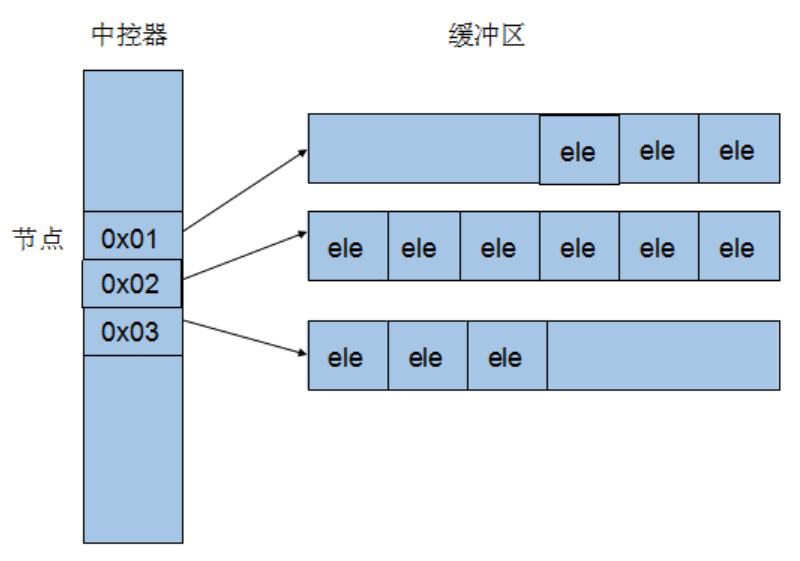
4.3.2 deque的迭代器
对于deque,维持其整体连续的假象,落在了迭代器的operator++和operator--两个重载运算符上。
- 该迭代器必须能够指出分段连续空间在哪里
- 其次他必须能够判断自己是否已经处在其所在缓冲区的边缘,如果是,一旦前进或后退就必须跳跃到下一个或上一个缓冲区。
因此为了能够正确跳跃,deque必须随时掌握管控中心map。如下的实现方式可行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34template <class T,class Ref,class Ptr,size_t Bufsize>
struct __deque_iterator{ //为继承 std::iterator
typedef __deque_iterator<T,T&,T*,Bufsize> iterator;
typedef __deque_iterator<T,const T&,const T*,Bufsize> const_iterator;
static size_t buffer_size(){return __deque_buf_size(Bufsize,sizeof(T));}
//未继承std::iterator,所以必须自行撰写下述五个必要的迭代器相应型别
typedef random_access_iterator_tag iterator_category; //1
typedef T value_type; //2
typedef Ptr pointer; //3
typedef Ref renference; //4
typedef size_t size_type;
typedef ptrdiff_t difference_type; //5
typedef T** map_pointer;
typedef __deque_iterator self;
//保持与容器的联结
T* cur; //此迭代器所指之缓冲区中的现行(current)元素
T* first; //此迭代器所指之缓冲区中的头
T* last; //此迭代器所指之缓冲区中的尾(含备用空间)
map_pointer node; //指向管控中心
...
inline size_t __deque_buf_size(size_t n,size_t sz){
return n!=0? n:(sz<512? size_t(512/sz):size_t(1));
}
/*
n!=0,返回n,表示buffer_size由 用户自定义
n=0,表示buffer_size使用默认值,那么:
sz<512,传回512/sz;
sz>=512,传回1
*/
};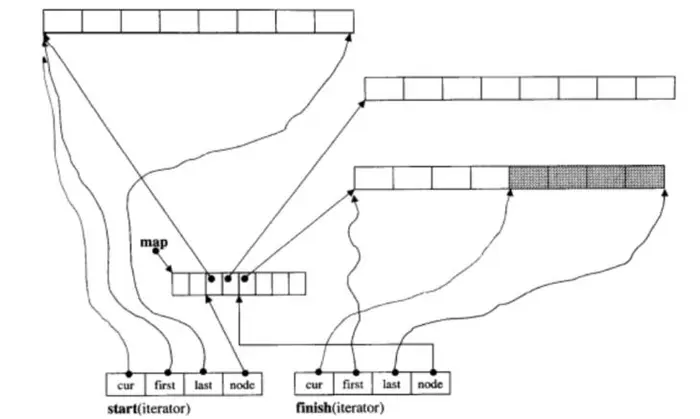 如上图,假设我们产生一个元素类型未
如上图,假设我们产生一个元素类型未int,缓冲区为8的deque,经过增删操作后拥有20个元素。deque类内的start和finish分别指向deque的第一个缓冲区和最后一个缓冲区,20/8=3,所以map拥有3个节点,且最后一个缓冲区还有插入元素的空间。三个指针cur、first、last分别如图所示,`cur·指向缓冲区的最后一个元素的下一个位置。
下面是deque几个重要操作: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79void set_node(map_pointer new_node){
node=new_node;
first=*new_node;
last=first+difference_type(buffer_size());
}
renference operator*() const {return *cur;}
pointer operator->() const {return &(operator*());}
difference_type operator-(const self& x)const{
return difference_type(buffer_size())*
(node-x.node-1)+(cur-first)+(x.last-x.cur);
}
self& operator++(){
++cur; //切换下一个元素
if(cur==last){ //如果已达到所在缓冲区的尾端
set_node(node+1); //利用set_node方法切换到下一个缓冲区
cur=first;
}
return *this;
}
self operator++(int){
self temp=*this;
++*this; //调用operator++
return temp;
}
self& operator--(){
if(cur==first){ //如果达到缓冲区的头部
set_node(node-1); //利用set_node方法切换到上一个缓冲区
cur=first;
}
--cur;
return *this;
}
self operator--(int){
self temp=*this;
--*this; //调用operator--
return temp;
}
self& operator+=(difference_type n){ //实现随机存取、迭代器可以直接跳跃n个距离
difference_type offset=n+(cur-first);
if(offset>=0&&offset<difference_type(buffer_size())) //目标位置在统一缓冲区
cur+=n;
else{ //目标位置不在统一缓冲区
difference_type node_offset=offset>0?
offset/difference_type(buffer_size())
:-difference_type((-offset-1)/buffer_size())-1;
set_node(node+node_offset); //切换至正确的节点
cur=first+(offset-node_offset*difference_type(buffer_size()); //切换至正确的元素
}
return *this;
}
self operator+(difference_type n) const{
self temp=*this;
return temp+=n; //调用operator+=
}
self& operator-=(difference_type n){
return *this+=-n;
}
self operator-(difference_type n) const{
self temp=*this;
return temp-=n; //调用operator-=
}
//随机存取第n个元素
reference operator[](difference_type n)const {return *(*this+n);}
bool operator==(const self& x)const{return cur==x.cur;}
bool operator!=(const self& x)const{return !(*this==x);}
bool operator<(const self& x)const{
return (node==x.node)?(cur<x.cur):(node<x.node);
}
4.3.3 deque的数据结构
deque除了维护map指针外,还必须维护start、finish两个迭代器,分别指向第一个缓冲区的第一个元素和最后一个缓冲区的额最后一个元素。此外,它当然也必须记住目前的map大小,因为一旦map所提供的节点不足,就必须重新配置更大的一块map。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36template <class T,class Alloc=alloc,size_t BufSiz=0>
class deque{
public:
typedef T value_type;
typedef value_type* pointer;
typedef size_t size_type;
public:
typedef __deque_iterator<T,T&,T*,BufSiz> iterator;
protected:
typedef pointer* map_pointer;//元素的指针的指针
protected:
iterator start; //表示第一个节点
iterator finish; //表示最后一个节点
map_pointer map; //指向map,map是块连续空间,其每个元素都是指针,指向一个节点
size_type map_size; //map内有多个指针
...
public:
iterator begin(){return start;}
iterator end(){return finish;}
reference operator[](size_type n){
return start[difference_type(n)]; //调用operator[]
}
reference front(){return *start;} //调用operator*
reference back(){
iterator temp=finish;
--temp; //调用operator--
return *temp; //调用operator*
}
size_type size() const{return finish-start;} //调用operator-
size_type max_size() const{return size_type(-1);}
bool empty() const{return finish==start;}
};
4.5. heap
heap不属于STL的容器组件,但我们有必要认识它的实现思想,它是实现priority queue的助手。priority queue允许用户以任何次序将元素存入容器中,但是取出时一定时从优先权最高的元素开始取。而堆正有这样的特性,适合作为priority queue的底层机制。
对于heap的虽然讲解的时候用的是完全二叉树的形式来讲解,但只是为了更直观的表达而已,一般来说实现都是采用数组的形式来实现的,同时为了达到空间可增长,采用vector+heap算法来实现堆。

4.5.1 push_heap算法
1 | template <class RandomAccessIterator> |
4.5.2 pop_heap算法
pop_heap算法思路如下:
- 1.把根节点元素取出,把最后一个节点的元素取出
- 2.将原根节点元素放在vector的最后一个节点处
- 3.将原先的最后一个节点的元素放置到原根节点处作为新根节点
- 4.将新根节点逐个与子节点比较,直到其值比子节点都大时,结束算法
1 | template <class RandomAccessIterator> |
4.5.3 sort_heap算法
既然每次pop_heap可获得heap之中键值最大的元素,如果持续对整个heap做pop_heap动作,每次将操作范围从后向前缩减一个元素(因为pop_heap会把键值最大的元素放在底部容器的最尾端),当整个程序执行完毕,我们便有了一个递增序列
1 | // 将 [first,last) 排列为一个heap |
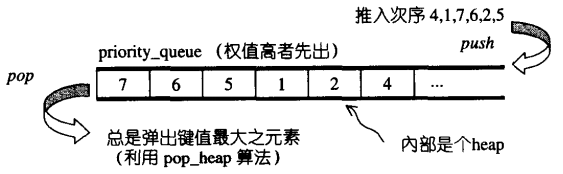
4.6 priority_queue
priority_queue是一个拥有权值观念的queue。其内部的元素不再像queue依照被存入的次序排列,而是按照元素的权值排列,权值最高者,排在最前面。缺省情况下proority_queue利用一个max-heap和vector为底部容器。priority_queue没有迭代器(queue和stack也没有)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47template <class T, class Sequence = vector<T>,
class Compare = less<typename Sequence::value_type> >
class priority_queue {
public:
typedef typename Sequence::value_type value_type;
typedef typename Sequence::size_type size_type;
typedef typename Sequence::reference reference;
typedef typename Sequence::const_reference const_reference;
protected:
Sequence c; // 底层容器
Compare comp; // 元素大小比较标准
public:
priority_queue() : c() {}
explicit priority_queue(const Compare& x) : c(), comp(x) {}
// 以下用到的 make_heap(), push_heap(), pop_heap()都是泛型算法
// 注意,任一个建构式都立刻于底层容器内产生一个 implicit representation heap
template <class InputIterator>
priority_queue(InputIterator first, InputIterator last, const Compare& x)
: c(first, last), comp(x) { make_heap(c.begin(), c.end(),comp); }
template <class InputIterator>
priority_queue(InputIterator first, InputIterator last)
: c(first, last) { make_heap(c.begin(), c.end(), comp); }
bool empty() const { return c.empty(); }
size_type size() const { return c.size(); }
const_reference top() const { return c.front(); }
void push(const value_type& x) {
__STL_TRY {
// push_heap是泛型算法,先利用底层容器的 push_back() 将新元素推入末端,再重排heap
c.push_back(x);
push_heap(c.begin(), c.end(), comp); //push_heap是泛型算法
}
__STL_UNWIND(c.clear());
}
void pop() {
__STL_TRY {
//pop_heap 是泛型算法,从 heap 内取出一个元素。它并不是真正将元素
//弹出,而是重排 heap,然后再以底层容器的 pop_back() 取得被弹出的元素
pop_heap(c.begin(), c.end(), comp);
c.pop_back();
}
__STL_UNWIND(c.clear());
}
};
5. 关联式容器
标准的STL关联式容器分为set集合和map映射表两大类。以及两大衍生体multiset和multimap。这些容器的底层机制均与RB-tree完成。红黑树是一个独立容器,但不对外界使用。同时SGI STL还提供了一个不在标准规则之外的管理容器hash_table,以及以hash_table为底层机制完成的hash_set、hash_map、hash_multiset、hash_multimap。
所谓关联式容器类似于关联式数据库:每笔数据都有一个键值和一个实值,当元素插入到关联式容器时会按照键值大小以某种规则将这个元素放置于合适的位置,因此对于关联式容器没有push_back、push_front、pop_back、pop_front这样的行为。
5.1 RB-tree
关于红黑树的的定义和一些平衡原理见数据结构篇,这里列举一些SGI STL的RB-tree源码。
5.1.1 RB-tree结构体
1 | RB树的节点结构: |
5.1.2 RB-tree迭代器
RB-tree的迭代器属于双向迭代器,但不具备随机定位的能力,与list较为相似,比较特殊的是他具有前进和后退的操作。RB-tree迭代器的operator++是调用了基层迭代器的increment()函数,其operator--调用decrement()函数。
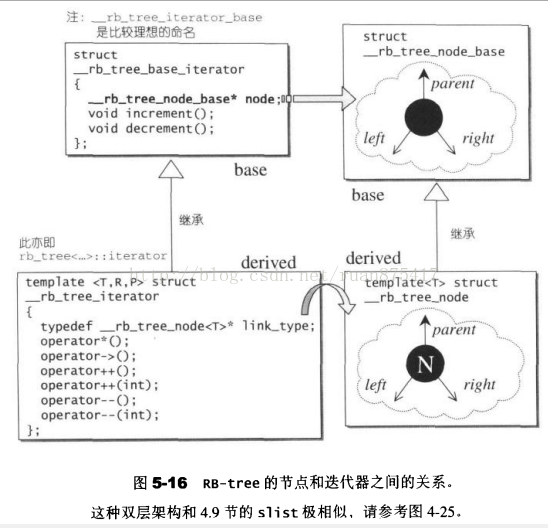
1 | //基层迭代器 |
5.1.3 RB-tree的数据结构
1 | //-------------------------------rb_tree类--------------------------------- |
5.2 set
set的特性是 所有的元素会按照键值自动排序set的键值等同于实值set不允许涵盖两个相同的键值- 不可以通过迭代器修改
set的元素数值,这会破坏元素的排列顺序。因此set<T>::iterator被定义为底层RB-tree的const_iterator,杜绝写入。也就是set的iterators是一种const iterators set类似list,当客户端对其进行元素的新增或者删除操作的时候,操作之前的迭代器不会失效,但是被操作的迭代器会失效- STL提供了一组
set/multiset的相关算法,包括交集set_intersectionset_unionset_differenceset_symmetric_difference set利用RB-tree的排序机制,因此是基于红黑树进一步的函数封装
5.2.1 set源码
1 | template <class Key,class Alloc,class Compare = std::less<Key>> |
5.3 map
- 所有元素会根据元素的键值自动被排序
- 元素的类型是
pair,同时拥有键值和实值;map不允许两个元素出现相同的键值 - 不可以修改
map的键值 但是可以修改实值 map基于红黑树实现对应的函数map和set一样,操作和删除操作时,操作之前的迭代器在操作之后依然有效
5.3.1 pair类型的定义
1 | template <class T1,class T2> |
5.3.2 map源码
1 | template <class Key,class T,class Alloc,class Compare = std::less<Key>> |
5.3.3 multiset/map
muiltiset\multimap和它们对应的set\map特性完全相同,唯一不同点时multi允许键值重复,因此插入采用的时RB-tree的底层函数的insert_equal()而不是insert_unique()。
5.4 hashtable
上面介绍的是以RB-tree为底层机制的容器,其在有序性和查找的性能(logn)上都不错。但还有一种在查找上的时间复杂度可在常数内完成的结构,那就是哈希表即:
- 二叉搜索树具有对数平均时间的表现,但是这个需要满足的假设前提是输入的数据需要具备随机性
hashtable散列表这种结构在插入、删除、搜寻等操作层面上也具有常数平均时间的表现。而且不需要依赖元素的随机性,这种表现是以统计为基础的
哈希表的特点:
hashtable可提供对任何有名项的存取和删除操作- 因为操作的对象是有名项,因此
hashtable可以作为一种字典结构 - 将一个元素映射成为一个
“大小可以接受的索引”简称为
hash function散列函数 - 考虑到元素的个数大于
array的容量,可能有不同的元素被映射到相同的位置,简称为冲突 - 解决冲突的方法有很多,线性探测、二次探测、开链
具体的hash思想可见数据结构篇,在SGI STL版本的hash_table使用的是开链法来解决哈希冲突,节点结构体如下:
1 | template <class Value> |
5.4.1 hashtable的迭代器
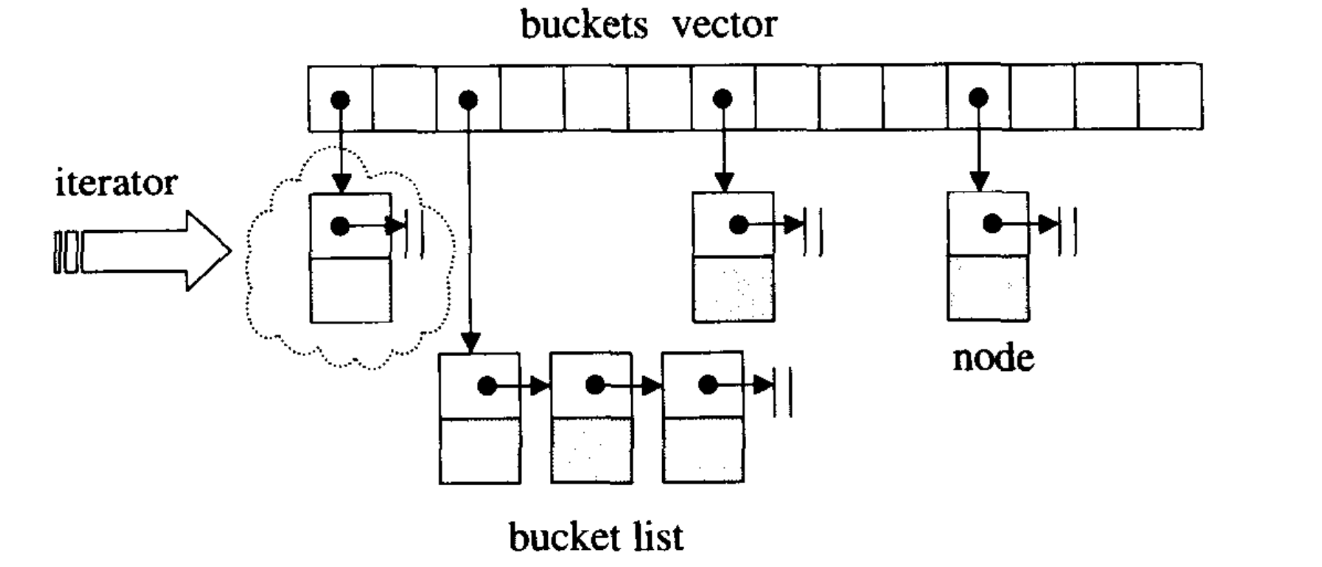
hashable迭代器维持着与整个buckets vector的关系,并记录目前所指的节点- 前进操作是从目前节点出发前进一个位置,由于节点被安置于
list内,使用next进行前进操作 - 如果目前是
list的尾端,则跳转至下一个bucket上,正是指向下一个list的头部 hashtable的迭代器没有后退操作,hashtable没有定义所谓的逆向迭代器
1 | template <class Value,class Key,class HashFcn, |
5.4.2 hashtable的数据结构
buckets聚合体以vector完成,以利动态扩充<stl_hash_fun.h>定义数个现成的hash functions全都是仿函数,hash function计算单元的位置,也就是元素对应的bucket的位置。具体调用的函数是bkt_num(),它调用hash function取得一个可以执行modulus(取模)运算的数值,以上的目的是出于 有些元素的型别是无法直接对其进行取模运算的,比如字符串类型 。- 按照质数设计
vector的大小,事先准备好28个质数,并设计一个函数用于查询最接近某数并大于某数的质数
1 | /* |
STL中哈希表一般不要外部使用,它是实现hash_map和hash_set的底层机制,编程者可以使用它们。
5.5 hash_set
同set一样,单独以键存储。hash_set是以hashtable为底层机制,因此存储数无序的,而set有序。同时其所供应的接口大部分都是转调用hashtable的函数。hash_set的使用方式与set差不多一样.
5.5.1 hash_set源码
1 |
|
5.6 hash_map
同map一样以键值对形式存储,但其底层机制为hashtable,因此大部分情况支持常数时间复杂度访问,存储是无序的。使用方式与map相差不大
5.6.1 hash_map源码
1 |
|
6. 各个容器的适用场景
- 1)
vector的使用场景:只查看,而不频繁插入删除的,因为频繁插入删除会造成内存的不断搬家和删除。使用场景比如软件历史操作记录的存储,我们经常要查看历史记录,比如上一次的记录,上上次的记录,但却不会去删除记录。 - 2)
deque的使用场景:比如排队购票系统,对排队者的存储可以采用deque,支持头端的快速移除,尾端的快速添加。如果采用vector,则头端移除时会移动大量的数据,速度慢。vector与deque的比较:- 一:
vector.at()比deque.at()效率高,比如vector.at(0)是固定的,deque的开始位置却是不固定的。 - 二:如果有大量释放操作的话,
vector花的时间更少,这跟二者的内部实现有关。 - 三:
deque支持头部的快速插入与快速移除,这是deque的优点。
- 一:
list的使用场景:频繁的插入删除的场景,这时也可以使用queue和deque。使用场景比如公交车乘客的存储,随时可能有乘客上下车,支持频繁的不确实位置元素的移除插入删除。set的使用场景:大部分负责查找内容且要求有序的情况下。使用场景比如对游戏中个人得分历史记录的存储,存储要求从高分到低分的顺序排列。map的使用场景:对查找有较高的要求,使用场景比如按ID号存储十万个用户,想要快速要通过ID查找对应的用户。红黑树的查找效率,这时就体现出来了。
7. 算法
7.1 STL算法分类
7.1.1 质变和非质变
- 质变算法:是指运算过程中会更改区间内的元素的内容
- 非质变算法:是指运算过程中不会更改区间内的元素内容
7.1.2 STL算法的一般形式
大多数算法有下列4中形式:
alg(first,last,other args);alg(first,last,dest,other args);alg(first,last,first2,other args);alg(first,last,first2,lasst2,other args);
更一般的说法是:
- 所有泛型算法的前两个参数一定是一对迭代器,通常为
first和last,范围为[first,last) - 许多STL算法不止只支持一个版本,可接受仿函数
_if结尾,如find()函数支持传入谓词或仿函数的find_if()版本 - 质变算法通常会有至少提供两个版本,一个是就地进行改变操作对象的版本,另一个是
_copy版本,拷贝一份副本,在副本上改变,如replace()函数就有replace_copy()版本 - 所有的数值算法实现都在
<stl_numeric.h>,用户使用时可包含#include`调用 - 其他算法实现于
<stl_algo.h>\<stl_algobase.h>,用户使用可通过包含#include<algorithm>调用
7.1.3 算法总览
| 算法名称 | 算法用途 | 质变? | 所在文件 | 所属作用 |
|---|---|---|---|---|
accumulate |
元素求和 | 否 | <stl_numeric.h> |
算术 |
adjacent_difference |
相邻元素差额 | 否 | <stl_numeric.h> |
算术 |
adjacent_find |
查找相邻重复(或符合条件)的元素 | 否 | <stl_algo.h> |
查找 |
binary_search |
二分查找 | 否 | <stl_algo.h> |
查找 |
copy |
复制 | 是 | <stl_algobase.h> |
拷贝 |
copy_backward |
逆向复制 | 是 | <stl_algobase.h> |
拷贝 |
copy_n |
复制n个元素 | 是 | <stl_algobase.h> |
拷贝 |
count |
计数 | 否 | <stl_algo.h> |
查找 |
count_if |
在特定传入的谓词或仿函数条件下计数 | 否 | <stl_algo.h> |
查找 |
equal |
判断两个区间相等与否 | 否 | <stl_algobase.h> |
关系 |
equal_range |
在有序区间寻找某值,返回一个区间 | 否 | <stl_algo.h> |
关系 |
fill |
该填元素值 | 是 | <stl_algobase.h> |
生成 |
fill_n |
该填元素值,n次 | 是 | <stl_algobase.h> |
生成 |
find |
循序查找 | 否 | <stl_algo.h> |
查找 |
find_if |
查找符合条件的元素 | 否 | <stl_algo.h> |
查找 |
find_end |
查找某个子序列的最后一次出现点 | 否 | <stl_algo.h> |
查找 |
find_first_of |
查找某些元素首次出现点 | 否 | <stl_algo.h> |
查找 |
for_each |
对区间的每一个元素施行某操作 | 否 | <stl_algo.h> |
生成 |
generate |
以特定操作的运算结果填充特定区间内的元素 | 是 | <stl_algo.h> |
生成 |
inner_product |
内积 | 否 | <stl_algo.h> |
算术 |
iter_swap |
元素互换 | 是 | <stl_algobase.h> |
交换 |
lower_bound |
返回有序序列范围内的可以插入指定值而不破坏容器顺序的第一个位置 | 否 | <stl_algo.h> |
查找 |
max |
最大值 | 否 | <stl_algobase.h> |
查找 |
max_element |
最大值所在位置 | 否 | <stl_algo.h> |
查找 |
min |
最小值 | 否 | <stl_algobase.h> |
查找 |
min_element |
最小值所在位置 | 否 | <stl_algo.h> |
查找 |
merge |
合并两个序列 | 是 | <stl_algo.h> |
生成 |
inplace_merge |
合并且就地替换 | 是 | <stl_algo.h> |
生成 |
random_shuffle |
随机重排元素 | 是 | <stl_algo.h> |
生成 |
remove |
删除某类元素 | 是 | <stl_algo.h> |
删除 |
remove_copy |
删除某类元素并将结果存储都另一个容器 | 是 | <stl_algo.h> |
删除 |
remove_if |
有条件的删除某类元素 | 是 | <stl_algo.h> |
删除 |
remove_copy_if |
有条件的删除某类元素,并将结果存储到另外一个容器 | 是 | <stl_algo.h> |
删除 |
replace |
替换某类元素 | 是 | <stl_algo.h> |
替换 |
replace_copy |
替换某类元素,并将结果存储到另一个元素 | 是 | <stl_algo.h> |
替换 |
replace_if |
有条件的替换 | 是 | <stl_algo.h> |
替换 |
replace_copy_if |
有条件的替换,并将结果存储都另一个容q器 | 是 | <stl_algo.h> |
替换 |
reverse |
反转 | 是 | <stl_algo.h> |
反转 |
reverse_copy |
反转并把结果存储到另一个容器 | 是 | <stl_algo.h> |
反转 |
rotate |
旋转 | 是 | <stl_algo.h> |
旋转 |
rotate_copy |
旋转,并把结果存储到另一个容器 | 是 | <sta_algo.h> |
旋转 |
search |
查找某个子序列 | 否 | <stl_algo.h> |
查找 |
search_n |
查找连续发生n次的某个子序列 | 否 | <stl_algo.h> |
查找 |
sort |
排序 | 是 | <stl_algo.h> |
排序 |
stable_sort |
排序并保持等值元素的相对次序 | 是 | <stl_algo.h> |
排序 |
stable_partition |
分割并保存元素的相对次序 | 是 | <stl_algo.h> |
分割 |
swap |
交换 | 是 | <stl_algobase.h> |
交换 |
swap_ranges |
指定区间的交换 | 是 | <stl_algo.h> |
交换 |
unique |
去重 | 是 | <stl_algo.h> |
去重 |
unique_copy |
去重后的结果存储到另一个容器 | 是 | <stl_algo.h> |
去重 |
upper_bound |
返回有序序列范围内的可以插入指定值而不破坏容器顺序的最后位置 | 否 | <stl_algo.h> |
查找 |
make_heap |
创建一个堆 | 是 | <stl_heap.h> |
堆 |
pop_heap |
从堆取元素 | 是 | <stl_heap.h> |
堆 |
push_heap |
将元素插入堆 | 是 | <stl_heap.h> |
堆 |
sort_heap |
堆heap排序 | 是 | <stl_heap.h> |
堆 |
7.2 sort
7.2.1 适用容器
sort()算法是最复杂堆庞大的一个,这个算法接受两个RandomAccessIterator迭代器,然后将区间内的元素由小到大重新排列。第二个版本则允许用户传入谓词或者仿函数作为排序条件,指定按什么规则排序。适用sort算法的容器有vecror\deque。
附:因为关联容器的底层机制,根本不需要sort排序,stack\queue\priority_queue对进出的机制也要求不需排序,而list的迭代器为BidirectinalIterator不适用。
7.2.2 sort实现的原理
早期的STL
sort()算法都是采用快排来实现,对于快排平均的时间复杂度为O(NlogN),但是最坏的情况却会达到O(N*N),因此现今的STL SGI改用IntroSort即内观排序算法,极其类似于median-three QuickSort三数取中快速排序算法。这种算法即使在最坏的情况下推进到O(NlogN)。快排的最坏情况的发生与快速排序中基准点的选择是有重大的关系,当出现下面两种情况时性能最差:
- 在分解时每次选取的基准点为最小元素
- 在分解时每次选取的基准点为最大元素
快排的过程:
- 如果序列中的元素个数为0或1,结束
- 取序列中的任何一个元素,一般会取该段序列的头或者尾元素作为基准点
pivot - 将序列分类
L\R两段子序列,使L内的每一个元素都小于或等于基准点,R内的每一个元素都大于等于基准点 - 对
L\R递归执行QuickSort,重复上述操作

1 | //编写自己的quickSort,没有优化,遇到最坏情况的时间复杂度会变成O(N*N) |
7.2.3 三点取中优化方案
为了避免快排出现上述所说的最坏情况,选择哪一个元素作为基准点是关键,在快排过程中采用三点取中间值的优化方案。三数取中median-of-three指的是在挑选基准元素时,不是简单的选择数组中的第一个元素或最后一个,而是选取某三个元素,常选头、尾和中央三个元素,并且适用三个元素之中的中位数作为基准元素进行划分。这样即使在最坏的情况下将时间复杂度推进到O(NlogN)
1 | //优化后的快排代码 |
7.3 数值算法
数值算法都在头文件<numeric>中,实现于<stl_numeric.h>。 ###### 7.3.1 accumulateaccumulate`算法用来计算指定区间的和,需要提供额外参数指定累加到哪一个初始值
1
2
3
4
5
6
7//版本一
template<class InputIterator,class T>
T accumulate(InputIterator first,InputIterator last,T init);
//版本二
template<class InputIterator,class T,class BinaryOperation >
T accumulate(InputIterator first,InputIterator last,T init,
BinaryOperation binary_op);
7.3.2 power
计算某数的n次方幂,该算法四SGI版本特有算法。
1
2template<class T,class Integer>
inline T power(T x,Integer n);
7.3.3 adjacent_difference
算法adjacent_difference用来计算[first,last)中相邻元素的差额,即它会将*first赋值给*result,并针对[first,last)内的每个迭代器i,进行*i-*(i-1),然后赋值给*++result
1
2template<class InpueIterator,class OutputIterator>
OutputIterator adjacent_difference(InputIterator first,InputIterator last,OutputIterator result);
7.4 基本算法
对于SGI版本,它会把常用的一些算法定义在<stl_algobase.h>,使用时包含<algorithm>即可。
7.4.1 equal
如果两个序列在[first,lasst)区间内相等,equal会返回true。如果第二序列元素多,则剩余元素不考虑,一般调用前要先保证元素个数一样。
1
2template<class InputIterator1,class InputIterator2>
inline bool equal(InpueIterator1 first1,InpueIterator1 last1,InpueIterator1 first2);
7.4.2 fill
将[first,last)内的元素该填新值。 1
2
3
4
5
6
7
8
9template<class ForwardIterator,class T>
void fill(ForwardIterator first,ForwardIterator last,const T& value);
``
###### 7.4.3 fill_n
将`[first,last)`的前n个改填新值,返回的迭代器指向被填入的最后一个元素的下一个位置。
```cpp
template<class OutputIterator,class Size,class T>
OutputIterator fill_n(OutputIterator first,Size n,const T& value);
7.4.4 iter_swap
该算法将两个ForwardIterator所指对象对调。
1
2template<class ForwardIterator1,calss ForwardIterator2>
inline void iter_swap(ForwardIterator a,ForwardIterator2 b);
7.4.5 copy
copy()算法是最最最常用的一个算法,copy()算法将输入区间的[first,last)的元素复制到目标区间[result,result+(last-first))中,执行完后返回一个迭代器,指向result+(last-first)。copy函数对参数非常宽松,对输入区间只需由InputIterator构成即可,输出区间尾OutputIterator构成即可,即意味着可以将任何容器的任何一段内容复制带任何容器的任何一段上,当然这些容器要由对应的迭代器。
1 | template<class InpueIterator,class OutputIterator> |
7.4.6 copy_backward
与copy非常相似,只不过copy_backward是以逆行方向复制到result
1
2
3template<class BidirectionalIterator1,class BidirectionalIterator2>
inline OutputIterator copy(BidirectionalIterator1 first,
BidirectionalIterator1,BidirectionalIterator2 result)
7.5 其他算法
定义与<stl_algo.h>内地算法
7.5.1 adjacent_find
该算法找出第一组满足条件的相邻元素,这里所谓的条件,在版本一中是指两元素相等,在版本二中允许用户指定一个二元为谓词运算,两操作数是相邻第一个元素和第二个元素。
1
2
3
4
5
6
7//版本一
template<class ForwardIterator>
ForwardIterator adjacent_find(ForwardIterator first,ForwardIterator last);
//版本二
template<class ForwardIterator,class BinaryPredicate>
ForwardIterator adjacent_find(ForwardIterator first,
ForwardIterator last,BinaryPredicate binary_pred);
7.5.2 find
在[first,lasy)找出第一个符合匹配条件的元素,返回该元素所在位置的迭代器,未找到则返回last
1
2template<class InputIterator,class T>
InputIterator find(InputIterator first,InputIterator last,const T& value);
7.5.3 find_if
传入一原谓词,根据指定的条件pred元素条件查找,返回该元素所在位置的迭代器,未找到则返回last
1
2template<class InputIterator,class predicate>
InputIterator find(InputIterator first,InputIterator last,predicate pred);
7.5.4 find_end
在序列一的[first1,last1)区间中,查找序列二[first2,last2)最后一次出现点,如果不存在,则返回last1。由两个版本,版本一默认使用==,版本二允许用户传入二元运算谓词。
1
2
3
4//版本一
template<class ForwardIterator1,class ForwardIterator2>
inline ForwardIterator(ForwardIterator1 first1,ForwardIterator1 last1
ForwardIterator2 first2,ForwardIterator2 last2);
7.5.5 find_first_of
本算法以[first2,last2)区间内的元素作为查找目标,寻找它们在[first1,last1)第一次出现的位置,只要[first2,last2)任何一个元素第一次出现在[first1,last1)就返回。两个版本,一个默认使用==,一个允许用户指定二元谓词传入
1
2
3template<class InputIterator,class ForwardIterator>
inline ForwardIterator(InputIterator first1,InputIterator last1
ForwardIterator2 first2,ForwardIterator2 last2);

