1. 面向对象
相比于c++,python中的OOP理解和使用都较简单,其把隐藏的的语法杂质和复杂性都去掉了。
## 1.1 类对象提供的默认行为
在python的面向对象模型种,要分清类对象和实例对象。类对象就是class定义了一个类只会,该类提供些行为就是类对象.而实例对象就是该类的实例。每次调用类,就会生成一个实例。
类对象提供的默认行为:
class语句创建类对象并将其赋值给变量名。就像def一样,class语句也是可执行语句,执行时会产生类对象,并赋值变量名- class语句的赋值语句会创建类属性,像模块文件一样,class语句内的顶层的赋值语句(不在
def内)会成为类对象的属性。 - 类属性提供对象的状态(变量)和行为(函数)
- 类仍然时模块内的属性。当
class执行时,只是赋值语句而已,赋值了一个类对象
1.2 实例对象是具体对象
每当调用类对象时,就会生成示例对象:
- 调用类对象会创建新的实例对象
- 每个示例对象有类的属性并且有自己的命名空间
- 在方法内对self属性做赋值会产生每个实例自己的属性(不必一定在构造函数
__init__中):在类函数内,第一个参数总是接受方法调用的隐形主体,通常用self会引用正处理的实例对象(相当于C/C++的this指针)。对self的属性做赋值运算,会创建或修改实例内的数据,而不是类的数据
1 | class firstClass: |
self会自动引用正在处理的示例对象,所以赋值语句会把值村储到实例的命名空间。因为类对象会产生多个实例,函数必须经过self参数才能识别获取正在处理的实例(就看出时c/c++中隐藏的this指针就行了)
1.3 继承
面向对象的一大特性就是继承,以下时python中继承的核心观点:
- 父类列在类开头的括号处
- 子类从父类中继承了函数和属性
- 实例会继承所有可读取类的属性:每个实例会从创建它的类中获取变量名,此外还有该类的父类
- 每个
object.attribute都会开启新的独立搜索:python会对每个属性取出表达式进行对类树的独立搜索,包括self - 一般来说逻辑的修改都是通过继承的子类修改,而不是直接修改父类
1 | class secondClass(firstClass): |
子类对属性的搜索会从下往上,即从子类到父类,直到所找属性名首次出现为止。上面的printdata函数覆盖了父类的printdata函数,这中覆盖叫做重载。
1.4 类的运算符重载初识
运算符重载就是让类写成的对象可以截获并响应内置类型上的运算,如加法、切片和打印等等,在这里我们只是片面性的列举了一些重载以做了解,更加具体的将在后面介绍。运算符重载的主要注意点:
- 运算符重载的命名方式为
__x__ - 当实例出现内置运算时,这类方法会自动调用。比如实例有
__add__方法,当对象出现+表达式时,该方法就会调用 - 类可覆盖多数内置类型运算
- 运算符重载让类变得更趋像python的对象模型
注意:我们必须关心一个方法,那就是__init__方法,也称为构造函数,它用于初始化对象的状态的,__init__和self是我们理解python面向对象特性的关键
1 |
|
输出: 1
2
3这是ThirdClass abc
这是ThirdClass abc123
[ThirdClass:abc123]
ThirdClass调用传入一个参数,这是传给__init__构造函数的参数,即在在构建实例时自动调用__init__构造函数来初始化属性- 有
__add__函数后,即+运算符重载,ThirdClass的实例对象就可出现在+处,对与+,它把左侧的对象传给self,右侧的给other。执行完后,对于__add__来说要返回一个新的对象实例 - 重载了
__str__方法后,可以直接调用print打印对象
1.5 以实例介绍类的细节
1.5.1 person和manager
在本节,将会两个类person和manager来介绍类实现的一些细节。顺带一提oython的%字符串格式为"%s,%d" %("2222",10)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26#person类
class Person:
def __init__(self,name,job=None,pay=0):
self.name=name;
self.job=jon;
self.pay=pay;
def lastName(self):
return self.name.split()[-1];
def giveRaise(self,percent):
self.pay=int(self.pay*(1+percent))
#print重载
def __str__(self):
return '[Person:%s,%s]' % (self.name,self.pay)
#manager类
class Manager(Person):
#定制自己的构造函数,使用父类(超类)的构造函数构造
def __init__(self,name,pay):
self.person=Person.__init__(self,name,'mgr',pay);
#重载函数,内部仍然使用超类的函数
def giveRaise(self,percent,bonus=1.0):
person.giveRaise(self,percent+bonus);
#改进点:
#1. 使用内置的`Instance.__class__.__name__`,避免重复修改前部分的名称
def __str__(self):
return'[%s:%s,%s]' % (self.__class__.__name__,self.name,self.pay)
1.5.2 对象持久化
在上面我们创建的不是真正的数据库记录,如果关闭python,实例也将消失,因为它们是内存中的临时对象,这时可以使用python中对象持久化的功能,让对象在退出程序时依然存在。对象持久化通过3个标准库模块实现:
pickle:任意python对象和字节串之间的转化dbm:实现一个可通过键访问的文件系统,以存储字符串shelve:使用上面两个模块按照键把python对象存储到一个文件
即shelve通过使用pickle将对象转为字符串,然后存储到一个dbm文件中键值对下,shelve通过键获取pinkle化的字符串,并用pickle在内存中重新创建最初对象。shelve就像字典一样,但是shelve一开始必须打开,并且在修改后关闭它
1
2
3
4
5
6
7import shelve
a=Person("小红");
b=Manager("小路",1000)
db=shelve.open('persondb')
for object in(a,b)
db[objecct.name]=object
db.close();persondb的文件
1.6 抽象类
抽象类只是实现给继承者的一些接口,继承者类将接口实现什么功能完全由继承类决定,因此抽象接口类不能产生实例,只要类中有一个抽象方法,我们就不能创建该类的实例对象。在python3中,在class的头部使用一个关键字参数,以及特殊的@装饰器语法,后续会讲装饰器
1
2
3
4
5from abc import ABCmeta,abstractmethod
class Super(metaclass=ABCmeta):
def method_1(self,*args):
pass;
1.7 命名空间
我们知道点号和无点号的变量名,会用不同方式进行访问,还有一些作用域是用于对对象命名空间做初始而设定的(如模块和类),总结如下:
- 无点号运算的变量民与作用域相对应(如普通的全局和局部赋值)
- 点号的属性名
object.x使用的是对象的命名空间 - 有些作用域会对对象的命名空间初始化(模块和类)
1.8 python的封装
在Python中,与许多其他面向对象的编程语言不同,没有显式的语法来声明一个成员变量或成员函数为“私有的”(即完全不可从类的外部访问)。但是,Python有一个约定俗成的做法来模拟私有属性和方法:在成员变量或方法的名字前加上单个下划线_或者双下划线
__。它们都是伪私有
- 单下划线
_前缀:使用单个下划线 _ 前缀的变量或方法被视为“内部使用”的,意味着它们是类的实现细节,不应在类的外部直接访问。但这只是一个约定,Python本身并不阻止外部代码访问这些“私有”成员。1
2
3
4
5
6
7
8
9
10class MyClass:
def __init__(self):
self._private_var = "This is private"
def _private_method(self):
print("This is a private method")
# 仍然可以从外部访问,但不建议这样做
obj = MyClass()
print(obj._private_var) # 输出: This is private
obj._private_method() # 输出: This is a private method
-**
双下划线__前缀(名称修饰):当在成员变量或方法前使用双下划线__
前缀时,Python会对其进行名称修饰(name
mangling)。这意味着Python会在这些名称前添加_类名前缀,从而使它们更难从外部直接访问。然而,这仍然不是一个真正的私有机制,因为知道命名修饰规则**的人仍然可以访问它们。
1
2
3
4
5
6
7
8
9
10
11
12
13class MyClass:
def __init__(self):
self.__private_var = "This is really private"
def __private_method(self):
print("This is a really private method")
# 不能直接访问,因为名称被修饰了成为_MyClass__private_var
obj = MyClass()
print(obj.__private_var) # AttributeError: 'MyClass' object has no attribute '__private_var'
obj.__private_method() # AttributeError: 'MyClass' object has no attribute '__private_method'
# 但仍然可以通过特殊的访问方式(不推荐)
print(obj._MyClass__private_var) # 输出: This is really private
# 注意:这里调用了内部修饰后的名称,这是不推荐的,因为它破坏了封装性
为什么Python没有强制的私有性? Python的设计哲学之一是“我们都是同意的成年人”。Python相信程序员能够正确地使用和理解他们正在编写的代码,因此没有提供强制的私有性机制。相反,它依赖于文档和代码的可读性来传达哪些成员应该被视为“私有的”或“保护的”。
在Python中,通常建议通过文档和清晰的命名约定来管理访问权限,而不是依赖于强制的私有性机制。
1.8 运算符重载详解
运算符重载是意味着给自定义类增加操作,在类方法中拦截内置操作,当类的实例出现内置操作时,python自动调用你的方法。以下时常见的运算符重载方法:
| 运算符重载函数名 | 重载功能 | 调用 |
|---|---|---|
__init__ |
构造函数 | 实例创建时自动调用 |
__del__ |
析构函数 | 实例对象回收时自动调用 |
__add__ |
运算符+ |
如果没有__iadd__,X+Y,X+=Y时会调用 |
__sub__ |
运算符- |
X-Y,X-=Y调用 |
__repr__,__str__ |
打印,转换 | print(x),repr(x),str(x) |
__call__ |
函数调用 | X(*args,**dargs) |
__getattr__ |
点号运算 | X.undefined |
__setattr__ |
属性赋值语句 | X.attribute=value |
__delattr__ |
属性删除 | del X.attribute |
__getattribute__ |
属性获取 | X.attribute |
__getitem__ |
索引运算 | x[key],x[i:j] |
__setitem__ |
索引赋值语句 | x[key]=value,x[i:j]=sequance |
__delitem__ |
索引和分片删除 | del x[key],del x[i:j] |
__iter__,__next___ |
迭代环境 | i=iter(x),next(i) |
__len__ |
长度 | 如果没有__bool__,直接len(x) |
__bool__ |
布尔测试 | bool(x) |
__lt__,__gt__ |
比较 | 从左到右以此为<,> |
__le__,__ge__ |
比较 | <=,>= |
__eq__,__ne__ |
比较 | ==,!= |
__contains__ |
成员关系测试 | item in X |
__str__ |
打印 | 调用print(类实例对象)时会调用该函数 |
由上面可知,运算符的重载前后都有两个下划线标识,以区分其他变量名函数。
1.8.1 构造函数__init__
__init__是python面向对象类的一个特殊方法,它在创建类的新实例时自动被调用,我们可以同c++一样称这个函数为构造函数,有以下特点是:
- python中一个类内只允许有一个init函数(这是因为python不支持函数重载造成的,因为它自己本身就是动态编译语言,类型在允许时绑定,一个函数后续也能实现比较好的重载)
- 第一个参数总是
self,相当于c++中隐藏的this指针 - 还有一点不同的是,子类的构造函数不会自动调用父类的构造函数,如果你需要调用父类构造,则必须显示使用
super().__init(父类init的参数,无则不用)__(当然还有一种写法是super(当前子类, self).__init__(),效果是一样的)
1.8.2 析构函数__del__
每当实例产生时就会调用__init__方法,每当实例空间被回收(垃圾回收),也会自动调用__del__函数
1 | class Test: |
1.8.3
索引和分片__getitem__和__setitem__
如果类中定义或者继承了该运算符,则对于实例的索引运算和分片,会自动调用__getitem__,会把实例传递给第一个参数,方括号内的值则传递给后面的一个参数,__setitem__则加了一个值value参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class operatorOverload:
def __init__(self):
self.L=[1,2,3,4];
def __getitem__(self,index):
return self.L[index];
def __setitem__(self,index,value):
self.L[index]=value;
x=operatorOverload();
#索引操作
print(x[2]); #3
print(x.L); #[1,2,3,4]
#分片操作
print(x[::2]) #[1,3]
#赋值
x[::2]=[8,9];
print(x[:]) #[8,2,9,4]
1.8.4 索引迭代__getitem__
__getitem__有一个买一送一的情况,该重载不仅仅支持上面所讲的索引和分片功能,同时支持了for循环的迭代(当然只出现在类未定义__iter__时):- 当类中未定义
__iter__时,即for循环每次循环时都会调用类的__getitem__。其实不仅仅指for循环会调用,其他的迭代环境,如in成员测试,列表解析,内置函数map,列表和元组赋值运算以及类型构造方法也会自动调用该方法,只有类中没有__iter__.1
2
3
4
5class stepper:
def __getitem__(self, index):
return self.data[i]
for data in x: #调用了__getitem__
print(data,end=' ');
- 当类中未定义
1.8.5 迭代器对象__iter__
尽管上面说的__getitem__支持迭代,但是它只是一直附加方法,真正的迭代还是要习惯用__iter__来获取迭代器,调用__next__访问,直到碰见异常StopIteration。python环境中所有迭代环境都是先尝试__iter__方法,然后再试__getitem__。
1 | class IterTest: |
上面可以看到,迭代器对象就是实例self,这是因为__next__是类方法。且上面定义的迭代器使像生成器函数和表达式、map和zip内置函数一样的单迭代对象,要达到多个迭代器的效果,__iter__只需替迭代器定义新的状态对象,而不是返回self,带来的消耗是要创建多个迭代对象:
1 | class NextTest: |
1.8.6
成员关系__contains__
再迭代领域,类通常把in成员关系运算符实现为一个迭代,使用__iter__或着__getitem__。要支持更加特定的成员关系,类应该要编写一个__contains__方法,出现是,方法优先级是contains>iter>getitem。__contains__方法应该把成员关系定义为对一个映射应用键,用于序列的搜索
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class ContainsTest:
def __init__(self,value):
self.data=value;
def __getitem__(self,i):
return self.data[i]
def __iter__(self):
return self
def __next__(self):
if(self.ix == len(self.data)): raise StopIteration
item = self.data[self.ix]
self.ix+=1
return item
def __contains__(self,x):
return x in self.data;
m=ContainsTest([1,2,3,4,5])
print("Contains:",3 in m,end=' '); #Contains: True
1.8.7 属性引用__getattr__
__getattr__方法是拦截属性点号运算,确切的说,当通过对未定义(不存在)属性名称和实例进行点号运算时,就会用属性名称作为字符串调用这个方法,如果可以通过继承找到属性就不会调用这个方法。因此,__getattr__可以作为钩子通过这种方式响应属性请求:
1
2
3
4
5
6
7
8
9
10class empty:
def ___getattr__(self,attrname):
if attrname="age":
return 40;
else:
raise AttributeError,attrname
x=empty();
x.age #40
x.name #AttributeError:namex.age会转至__getattr__方法,同理x.name也是
有个相关的重载方法,__setattr__会拦截所有属性的赋值语句,因此如果定义了这个方法要小心。除此之外,因为它对任何赋值语句都会拦截,即使是在__setattr__内也不例外,为防止无限递归,要使用该方法,必须通过属性字典做索引来赋值任何实例属性self.__dict__[attr]=value;:
1
2
3
4
5
6
7
class test:
def __setattr__(self,attrname,value):
if attr=='age':
self.__dict__[attr]=value;
else
raise AttriubteError, attrname+'nor allowed';
1.8.8 调用__call__表达式
当调用实例时,使用__call__。如果定义该方法,python1就会为实例应用函数调用表达式运行__call__。
1
2
3
4
5
6class Test:
def __call__(self,*args,**agrv):
print('called:',args,argv);
c=Test();
c(1,2,3,x=4,y=5); #called:(1,2,3){'x'=4,'y'=5}
1.8.9 布尔测试__bool__
python首先尝试__bool__来直接获取一个bool值,如果没有该方法,就尝试__len__,根据对象的长度确定一个真值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Truth:
def __init__(self,value):
self.data=value;
def __bool__(self):
if(self.data!=None):
return True;
else:
return False;
def __len__(self):
return len(self.data);
x=Truth("12314");
if x:
print('bool yes!'); #bool yes!
if len(x):
print('len yes!'); #len yes!
1.8.10
迭代环境__next__和__iter__
python对于创建得类允许自定义迭代环境,如果用户需要定义迭代环境,必须
- 实现__iter__和__next__函数, -
同时在__next__函数中指定迭代退出环境,一般为产生一个异常raise
- 在迭代中__next__中实现迭代对象,返回该对象
1 | def __iter__(self): |
1.8.11 打印print__str__
python还可以重载打印运算符,通过实现__str__()函数,那么在使用print(对象)时就好调用该函数
1
2
3
4
5
6
7
8
9
10class A:
self.name;
self.age;
def __init__(self):
self.name = "trluper"
self.age = 25
def __str__(self):
return 'This guy name %s, age is %s' %(self.name,self.age)
A a;
print(a); #This guy name trluper, age is 25
1.9 类的设计
无论是哪门语言,对于OOP,其重要的三个面向对象特性:继承、多态、封装。在python,这三个特性作用也是一样:
- 继承:提高代码的复用性
- 多态:提高程序的可扩展性和可维护性
- 封装:方法和运算符实现行为,数据隐藏是一种惯例,以此提高程序安全性
1.9.1 封装
封装提高程序的安全性。将数据(属性)和行为(方法)包装到类对象中,在方法内部对属性进行操作,在类对象的外部调用方法,这样无需关心方法内部的具体实现细节,从而隔离了复杂度;在python中没有专门的修饰符用于属性的私有,如果该属性不希望在类对象外部被访问,前边使用两个_修饰
1
2
3
4
5
6
7
8
9
10
11
12class Student:
def __init__(self,name,age):
self.name=name
self.__age=age #年龄不希望在类的外部被使用,所以加了两个__
def show(self):
print(self.name,self.__age)
stu1=Student('张三',20)
stu1.show()
print(stu1.name)
#print(stu1.__age) #这句话会报错,因为__age不希望在类外面使用
'''如果想在类之外使用,可以用_类名__实例属性来用'''
print(stu1._Student__age)
1.9.2 继承
在python中,如果一个类没有继承任何类,则默认继承object。python支持多继承,定义子类时,必须在其构造函数中调用父类的构造函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21class Person(object):
def __init__(self,name,age):
self.name=name
self.age=age
def info(self):
print(self.name,self.age)
class Student(Person):
def __init__(self,name,age,stu_num):
super().__init__(name,age)
self.stu_num=stu_num
class Teacher(Person):
def __init__(self,name,age,teachofyear):
super().__init__(name,age)
self.teachofyear=teachofyear
stu=Student('张三',20,1001)
teach=Teacher('李四',40,20)
stu.info()
teach.info()super().xxx()调用父类中被重写的方法。
另外一点,在python中object类是所有类的父类,因此所有类都有object类的属性和方法。有内置函数dir()可以查看指定对象所有属性。object还有有一个__str__()方法,用于返回一个对于“对象的描述”,对应于内置函数str()经常用于print()方法,帮我们查看对象的信息,所以我们经常会对__str__()进行重写
1 | class Student: |
1.9.3 多态
多态就是“具有多种形态”,它指的是:即便不知道一个变量所引用的对象到底是 什么类型,仍然可以通过这个变量调用方法,在运行过程中根据变量所引用对象的类型, 动态决定调用哪个对象中的方法。实现多态必须有的三个条件:
- 继承
- 方法重写
- 父类引用指向子类对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class Animal(object):
def eat(self):
print('动物会吃')
class Dog(Animal):
def eat(self):
print('狗吃骨头')
class Cat(Animal):
def eat(self):
print('猫吃鱼')
class Person():
def eat(self):
print('人吃五谷杂粮')
def fun(obj):
obj.eat()
fun(Cat())
fun(Dog())
fun(Animal())
print('——————————')
fun(Person())
1.9.4 类的浅拷贝和深拷贝
- 变量的赋值操作:只是形成两个变量,实际上还是指向同一个对象
- 浅拷贝:python拷贝一般都是浅拷贝,拷贝时,对象包含的子对象内容不拷贝,因此,源对象与拷贝对象会引用同一个子对象
- 深拷贝:使用copy模块的
deepcopy函数,递归拷贝对象中包含的子对象,源对象和拷贝 对象所有的子对象也不相同
1 | class CPU: |
输出: 1
2
3
4
5
6
7
8
9
10
11
12
13//赋值就是简单的变量引用同一个对象
<__main__.CPU object at 0x000001C0D615ED10>
<__main__.CPU object at 0x000001C0D615ED10>
<__main__.Disk object at 0x000001C0D615ED40>
#浅拷贝,对象包含的的子对象内容不拷贝,都引用同一个内容
<__main__.Computer object at 0x000001C0D615ED70> <__main__.CPU object at 0x000001C0D615ED10> <__main__.Disk object at 0x000001C0D615ED40>
<__main__.Computer object at 0x000001C0D615F820> <__main__.CPU object at 0x000001C0D615ED10> <__main__.Disk object at 0x000001C0D615ED40>
#深拷贝,子对象也拷贝了
<__main__.Computer object at 0x000001C0D615ED70> <__main__.CPU object at 0x000001C0D615ED10> <__main__.Disk object at 0x000001C0D615ED40>
<__main__.Computer object at 0x000001C0D615DD50> <__main__.CPU object at 0x000001C0D615D450> <__main__.Disk object at 0x000001C0D615D3F0>
1.9.5 设计模式之委托模式
所谓的委托,通常就是指控制对象内嵌其他对象,而把运算请求传给这些内嵌对象处理,控制器对象只负责管理工作。在python中,委托通常用__getattr__钩子方法实现,因为这个方法会拦截对不存在属性的读取,因此代理类可以使用__getattr__把任意读取操作转给被包装对象。
简而言之:通过一个类来调用另一个类里的方法来处理请求,即这两个类对象参与处理同一个请求对象,只不过一个是委托者,一个是处理者。
1
2
3
4
5
6
7
8
9
10class wrapper:
def __init__(self,object):
self.wrapped=object; #内嵌对象
def __getattr__(self,attrname):
if attrname=='append':
return getattr(self.wrapped,attrname);
L=[1,2,3]
x=wrapper(L);
x.append(4);
print(L) #[1, 2, 3, 4]x.append(4)未在wrapper内定义,触发__getattr__函数,getattr(x,y)函数的作用就是点操作,即x.y。
1.9.6 绑定和无绑定方法
- 实例的绑定方法:即有
self,且在类中没有被任何装饰器修饰的方法就是绑定到对象的方法,这类方法专门为对象定制。
1 | class Person: |
通过对象调用绑定到对象的方法,会有一个自动传值的过程,即自动将当前对象传递给方法的第一个参数(self,一般都叫self,也可以写成别的名称);若是使用类调用,则第一个参数需要手动传值。
- 类的绑定方法:类中使用
@classmethod修饰的方法就是绑定到类的方法。这类方法专门为类定制。通过类名调用绑定到类的方法时,会将类本身当做参数传给类方法的第一个参数。
1 |
|
输出: 1
2<class '__main__.Operate_database'>
192.168.0.5:3306 abc/123456
- 非绑定方法:在类内部使用 @staticmethod 修饰的方法即为非绑定方法,这类方法和普通定义的函数没有区别,不与类或对象绑定,谁都可以调用(实例和类都可以),且没有自动传值的效果。
1 | import hashlib |
输出: 1
2f7a1cc409ed6f51058c2b4a94a7e1956
0659c7992e268962384eb17fafe88364
1.10 棱形继承
在多层继承和多继承同时使用的情况下,就会出现复杂的继承关系,即重重复继乘,常说的菱形继承
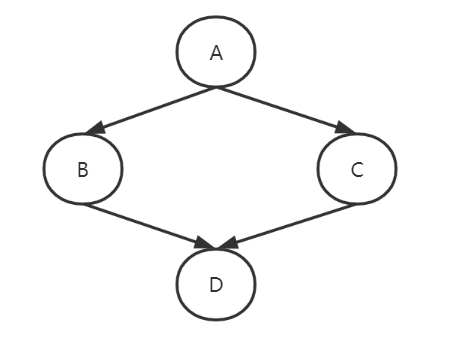 在这种结构中,在调用顺序上就出现了疑惑,调用顺序究竟是以下哪一种顺序呢,如果是深度,那么A会重复调用,造成不必要的消耗
在这种结构中,在调用顺序上就出现了疑惑,调用顺序究竟是以下哪一种顺序呢,如果是深度,那么A会重复调用,造成不必要的消耗
D->B->A->C->A(深度优先)D->B->C->A(广度优先)
上面问题的根源都跟MRO有关,MRO(Method Resolution
Order)也叫方法解析顺序,主要用于在多重继承时判断调的属性来自于哪个类,其使用了一种叫做C3的算法,其基本思想时在避免同一类被调用多次的前提下,使用广度优先和从左到右的原则去寻找需要的属性和方法。
要避免顶层父类某个方法被多次调用,此时就需要super()来发挥作用了,super本质上是一个类,内部记录着MRO信息,由于C3算法确保同一个类只会被搜寻一次,这样就避免了顶层父类中的方法被多次执行了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32"""
注意,这段代码是个特例,在D的注释处明显调用了B/C的构造函数,所有会执行两次A的构造函数,要使其不执行两次,则需要使用super().xxx()。这种方法很常用,应该熟记
"""
class A():
def __init__(self):
print('init A...')
print('end A...')
class B(A):
def __init__(self):
print('init B...')
super(B, self).__init__()
# A.__init__(self)
print('end B...')
class C(A):
def __init__(self):
print('init C...')
super(C, self).__init__()
# A.__init__(self)
print('end C...')
class D(B, C):
def __init__(self):
print('init D...')
super(D, self).__init__()
#B.__init__(self)
#C.__init__(self)
print('end D...')
if __name__ == '__main__':
D()1
2
3
4
5
6
7
8
9init D...
init B...
init C...
init A...
end A...
end C...
end B...
end D...
- 新式类:从object继承来的类。(如:class A(object)),采用广度优先搜索的方式继承(即先水平搜索,再向上搜索)。
- 经典类:不从object继承来的类。(如:class A()),采用深度优先搜索的方式继承(即先深入继承树的左侧,再返回,再找右侧)。
注意:Python2.x中类的是有经典类和新式类两种。Python3.x中都是新式类(类都默认继承object)。因此对于多重继承,顺序很重要,他会根据继承类在首行位置,从左到右搜索
实例: 1
2
3
4
5
6
7
8
9
10
11class A:
attr=1;
class B(A):
pass;
class C(A):
attr=2;
class D(B,C):
pass;
M=D();
print(M.attr) #2D->B->C->A,在C时遇到了属性attr=2,停止搜索返回,输出为2
1.10.1 super详解
上面已经提到了,在python3.x版本上,都使用新式类,python避免重复调用是采用MRO(Method Resolution Order)机制也叫方法解析顺序,主要用于在多重继承时判断调的属性来自于哪个类,其使用了一种叫做C3的算法,其基本思想时在避免同一类被调用多次的前提下,使用广度优先和从左到右的原则去寻找需要的属性和方法。
super本质上是一个类,但super()
和父类没有实质性的关联:
super()函数需要两个参数,第一个是类名,第二个是一般都为self但也会有cls情况,但在python3.x中使用super().xxxx()等同于super(classname,self).xxxx()
1 | class A: |
super工作原理:如果在类D中调用super()会传入D类,那就会在它__mro__上一级开始查找,它的上一级是B,就会调用B的函数,依次类推下去。如下更改D类的super()输出改变
1 | class D(B,C): |
因为上一级是__mro__中C的上一级是A,就好执行A的__init__()函数
1.11 slots(可选)
python类有一个双刃剑就是:即使我们没有在类内部创建属性,也可以在实例对象中通过.给实例对象创建一个属于实例的属性,这样听起来非常bug,不像java和c++这样有很好的封装性:
1
2
3
4
5class A:
pass
a=A();
a.p=20;
print(a.p) #20__getattr__能够对未在类内创建的属性提供操作。这里介绍python提供的slots来支持这一功能。
这个特殊属性一般是在类的顶层内将变量名称(字符串形式)按顺序赋值给变量__slots__,该属性规定:只有__slots__列表内的这些变量名可赋值为实例属性。它也要遵循python的规则,实例属性名必须在引用前赋值
1
2
3
4
5
6
7
8class limiter:
__slots__=['age','name','job']
x=limiter();
#print(x.age) #AttributeError,未赋值就引用
x.age=40
print(x.age) #40
x.jk=2; #不允许,变量名不在__slots____slots__会没有__dict__属性,事实上,__slots__就是以__dict__的代价来起到这样一个功能的:
1
2
3
4
5class limiter:
__slots__=['age','name','job','__dict__']
x=limiter();
x.jk=2; #运行成功__dict__,我们就不能在类的函数内随便起变量名,因此对于__slots__看情况使用
1.12. 装饰器
装饰器一般有函数装饰器和类装饰器。装饰器即指通过对函数的包装来修改其他函数的功能的函数。我们知道在python中可以嵌套定义函数,但是我们外部无法直接访问嵌套内部函数,好在可以将一个函数名赋值给一个变量,其实函数名就是一个变量,只不过指向函数对象,也可通过返回函数变量名,然后通过变量名去调用变量名()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19def hi(name="yasoob"):
def greet():
return "now you are in the greet() function"
def welcome():
return "now you are in the welcome() function"
if name == "yasoob":
return greet
else:
return welcome
a = hi() #返回great
print(a)
print(a()) #调用a()==great()
#输出
<function greet at 0x7f2143c01500>
now you are in the greet() function
既然我们能够将函数作为变量,那么变量当然可以作为参数,当我们将函数变量作为参数传递给另外一个函数时,就会产生装饰器的知识,实际上装饰器就是做这种事:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24def a_new_decorator(a_func):
def wrapTheFunction():
print("I am doing some boring work before executing a_func()")
a_func()
print("I am doing some boring work after executing a_func()")
return wrapTheFunction
def a_function_requiring_decoration():
print("I am the function which needs some decoration to remove my foul smell")
a_function_requiring_decoration()
#outputs: "I am the function which needs some decoration to remove my foul smell"
a_function_requiring_decoration = a_new_decorator(a_function_requiring_decoration)
a_function_requiring_decoration()
# I am the function which needs some decoration to remove my foul smell
# I am doing some boring work after executing a_func()
1.12.1 函数装饰器
上面讲解了函数装饰器的原理,提供了一种方式声明函数的特定运算模式,其原理是将函数包裹到另一个函数,在另一个函数的逻辑内实现。现在为简化其实现,使用@代替这些代码,所以函数装饰器在def语句前一行,由@符号、后面跟着所谓的元函数组成。元函数就是管理另一函数(或其他可调用对象)的函数,如下:
1
2
3
4
5
6
7
8
9@a_new_decorator
def a_function_requiring_decoration():
print("I am the function which needs some decoration to "
"remove my foul smell")
a_function_requiring_decoration()
#outputs: I am doing some boring work before executing a_func()
# I am the function which needs some decoration to remove my foul smell
# I am doing some boring work after executing a_func()@a_new_decorator等价于a_function_requiring_decoration = a_new_decorator(a_function_requiring_decoration)
python内置的装饰器:
@classmethod:用于指示一个方法是类方法。类方法与实例方法和静态方法不同,因为类方法接收类作为第一个参数(通常命名为cls),而不是实例对象。这使得类方法可以在不创建类实例的情况下访问或修改类的状态@staticmethod:在类内部使用该装饰器修饰方法,这类方法不与类或对象绑定,属于静态方法,谁都可以调用,装饰的方法不接收特殊的第一个参数。它们就像普通的函数,但是被定义在类内部。你可以通过类名或类的实例来调用它们,但它们不能访问或修改类变量(除非它们被显式地作为参数传递)。@wraps(函数变量名);在上面举例的函数装饰器@a_new_decorator中会改变函数的__name__为wrapTheFunction,正常应该为a_function_requiring_decoration。这时候就需要使用@wraps()装饰器1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19print(a_function_requiring_decoration.__name__)
# Output: wrapTheFunction
from functools import wraps
#使用@wraps()
def a_new_decorator(a_func):
def wrapTheFunction():
print("I am doing some boring work before executing a_func()")
a_func()
print("I am doing some boring work after executing a_func()")
return wrapTheFunction
def a_function_requiring_decoration():
print("I am the function which needs some decoration to "
"remove my foul smell")
#输出正常
print(a_function_requiring_decoration.__name__)
# Output: a_function_requiring_decoration
1.12.2 类装饰器
类装饰器类似于函数装饰器(后续补充)
2. 链表实现(实际应用)
1 | class ListNode: |

